本文将介绍过去五年内发表的一些重要论文,并探讨其重要性。论文1—5涉及通用网络架构的发展,论文6—9则是其他网络架构的论文。点击原文即可查看更详细的内容。
1.AlexNet(2012)
AlexNet是卷积神经网络架构的起源(尽管可能会有人认为,1998年Yann LeCun发表的论文才是真正的开创性出版物)。这篇名为“基于深度卷积网络ImageNet分类”的论文总共被引用6,184次,被公认为是该领域最具影响力的论文之一。在2012年的ImageNet大规模视觉识别挑战赛中,Alex Krizhevsky等人创建的“大而深的卷积神经网络”取得了大赛冠军——将分类误差从26%降至15%,这是一个惊人的改进,几乎让所有的计算机视觉社区为之震撼。从那时起,卷积神经网络被广泛传播,成了一个家喻户晓的名字。
该论文讨论了AlexNet架构的网络结构。与现代架构相比,AlexNet使用了相对简单的网络结构:由5个卷积层、最大池化层、drop-out层和3个全连接层组成。他们设计的网络可用于对1000个类别进行分类。
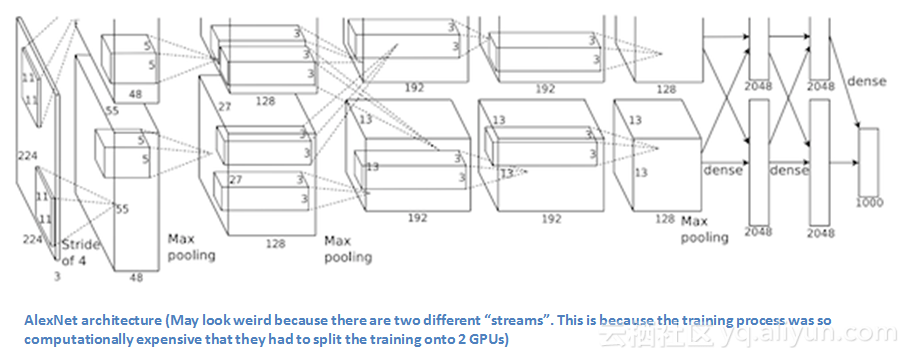
主要论点
1.在ImageNet数据集上训练网络,ImageNet数据集包含超过1500万张注释图像,类别超过22000个。
2.使用ReLU处理非线性函数(这样可以减少训练时间,因为ReLU比传统的tanh函数运行速度要快几倍)。
3.使用的数据增强技术包括:图像转换,水平反射和补丁提取。
4.采用drop-out层,解决了训练数据的过拟合问题。
5.使用批量随机梯度下降训练架构,其中动量和权重衰减都有固定的具体值。
重要性
Krizhevsky等人在2012年开发出来的神经网络,是卷积神经网络在计算机视觉社区的一场盛宴。这是首次在ImageNet数据集上性能表现非常好的架构,利用了今天仍在使用的技术,如数据增强和dropout。这篇论文阐述了卷积神经网络的优点,并创造了其他神经网络难以逾越的性能。
2.ZF Net
由于AlexNet在2012年闪亮登场,在2013的ImageNet大规模视觉识别挑战赛中出现的卷积神经网络架构数量大幅度增加,该年度大赛冠军是由纽约大学的Matthew Zeiler团队创建的网络——ZF Net,该架构实现了低至11.2%的误差率。ZF Net架构相当于对AlexNet架构做了微调,但作者仍然提出了一些能够提高模型性能的重要设想。这篇论文之所以特别重要,另一个原因就是作者花了很多精力来解释卷积神经网络的可视化,并展示了如何正确的可视化滤波器和权重。
在这篇题为“卷积神经网络的可视化和理解”的论文中,Zeiler团队首先解释了重新对卷积神经网络感兴趣的原因,这源自于大型训练集的可访问性,以及随着GPU的使用率增大,计算能力也有提高。作者还提到“更好的架构会减少试验和误差次数”。尽管和三年前相比,我们对卷积神经网络有了更全面的理解,但这仍然是很多研究人员所面临的问题!本文的主要贡献是对AlexNet架构的细节做了微调,并且以一种很有意思的方法对特征映射做了可视化处理。
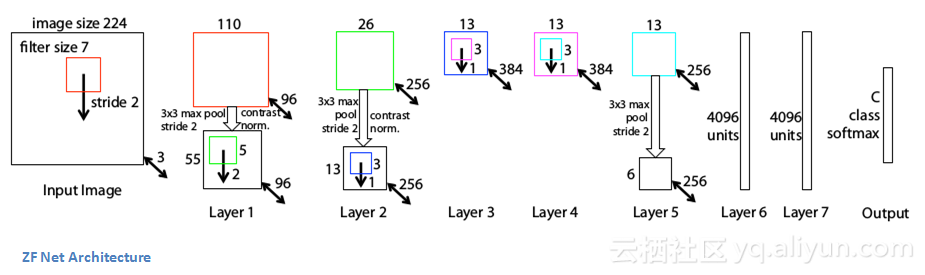
主要论点
1.ZF Net与AlexNet模型有非常相似的架构,同时也做了一些微调。
2.AlexNet训练了1500万张图片,而ZF Net仅仅训练了130万张图片。
3.AlexNet在第一层使用11*11的滤波器,而ZF Net使用了7*7的滤波器和一个较小的步长。做这一调整的原因是第一个卷积层中使用较小的滤波器有助于将大量的原始像素信息保留在输入数组中。11*11的滤波器会过滤掉很多有用的信息,尤其是在第一个卷积层。
4.随着卷积网络的发展,使用滤波器的数量有所增加。
5.将ReLUs作为其激活函数,交叉熵代价函数作为误差函数,并使用批量随机梯度下降进行训练。
6.开发了一种名为去卷积网络的可视化技术,有助于测试不同的特征激活与输入数组的关系。之所以被称为“去卷积”,因为它将特征映射为像素(与卷积层的作用正好相反)。
DeConvNet
DeConvNet模型的基本思想是,在卷积神经网络已经训练好的每一层,都增加一个“去卷积”返回图像像素。图像输入到卷积神经网络中,并在每个级别计算其特征激活。假设现在要检查第四个卷积层中某个特征激活,我们来存储这一个特征映射的激活,但将卷积层中的所有其他激活都设为0,然后将此特征映射作为输入传递给DeConvNet模型。该DeConvNet模型具有与原始卷积神经网络相同的滤波器。然后,输入经过一系列的反池化(和最大池化相反)、校正以及前面每个层的滤波器操作,然后到达输入数组。

这整个过程是因为我们想要检查到底哪种类型的结构激活给定的特征映射。 我们来看看第一层和第二层的可视化效果。
我们知道,卷积层中的第一层是一个基本特征检测器,检测边缘或颜色。如上图所示,我们可以看到,在第二层有更多的循环特征被检测到。下面,我们来看看第3、4、5层。

这些层显示了更多高级特征,如狗的头部或鲜花。需要注意的是,在第一个卷积层之后,我们通常会有一个池化层对图像进行下采样(例如,将32*32*3数组转换为16*16*3的数组)。这样做可以在第二层看到原始图像范围更广的特征。
重要性
ZF Net模型不仅是2013年度ImageNet大规模视觉识别挑战赛的冠军,而且还提供了有关卷积神经网络运行的绝佳的视觉效果,并展示了更多能够提高性能的方法。 ZF Net模型所描述的可视化方法不仅有助于解释卷积神经网络的内部运行机制,而且还提供了对网络架构进行改进的独特见解。
3. VGG Net (2014)
VGG Net是2014年创建的架构(但并不是ImageNet大规模视觉识别挑战赛的冠军),其利用率达到7.3%。来自牛津大学的Karen Simonyan和Andrew Zisserman创建了一个特别简单的19层的卷积神经网络,使用步长为1的3*3的滤波器,步长为2的2*2池化层。
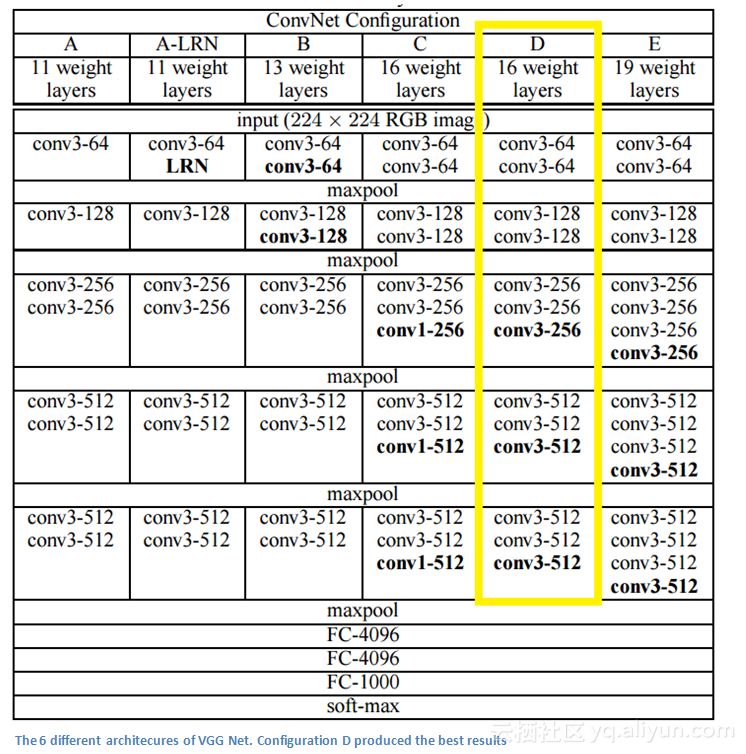
主要论点
1.仅仅使用了3*3的滤波器,这与AlexNet第一层使用的11*11滤波器和ZF Net使用的7*7滤波器大不相同。作者证明了两个3*3 卷积层的组合具有5*5的有效感受野。在使用较小的滤波器的同时,也模拟出了一个更大的滤波器,同时也减少了参数的数量。此外,我们还可以在两个卷积层中使用ReLU层。
2.三个卷积层的组合具有7*7的有效感受野。
3.随着每层的深入,输入数组随之减小(卷积层和池化层的原因),过滤器的数量随之,因此数组的深度也不断增加。
4.有趣的是,滤波器的数量在每个最大池化层之后都会增加一倍。这强化了缩小空间维度的想法,但增加了网络的深度。
5.特别适用于图像分类和本地化任务。作者使用本地化的形式作为回归。
6.用Caffe构建架构。
7.在训练过程中使用数据增强技术是抖动( scale jittering )。
8.在每个卷积层之后使用ReLU层,并采用批梯度下降进行训练。
重要性
VGG Net模型一直都是我心目中最有影响力的论文之一,因为它强化了这一观点:为了使视觉数据可以分层表示,卷积神经网络必须具有更加深入的网络层。
4. GoogLeNet (2015)
谷歌使用了Inception模块来代替简单网络架构这一概念,GoogLeNet模型是一个22层的卷积神经网络架构,并且是2014年度ImageNet大规模视觉识别挑战赛的冠军,误差率高达6.7%。据我所知,这是第一个真正摒弃了在顺序结构中对卷积层和池化层进行简单堆叠的卷积神经网络架构之一。这个新架构着重考虑内存和功耗(堆叠所有的这些层并添加大量的滤波器会产生计算成本和内存成本,同时也会增加过拟合的概率)。
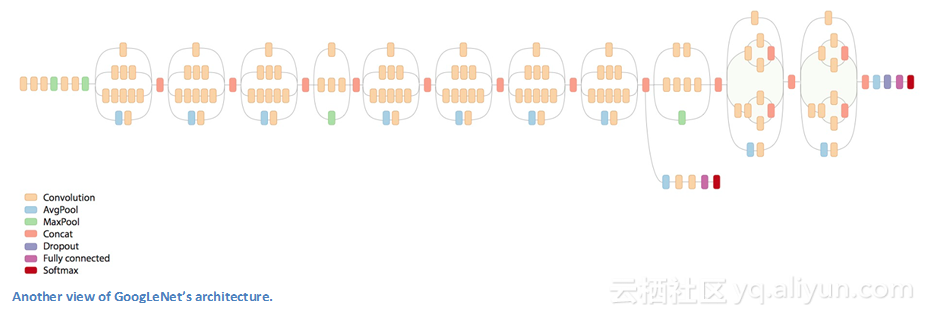
Inception模块
并不是像以前的架构按顺序运行,GoogLeNet架构中存在可以并行的网络。如下图所示,这个方框被称为Inception模块。
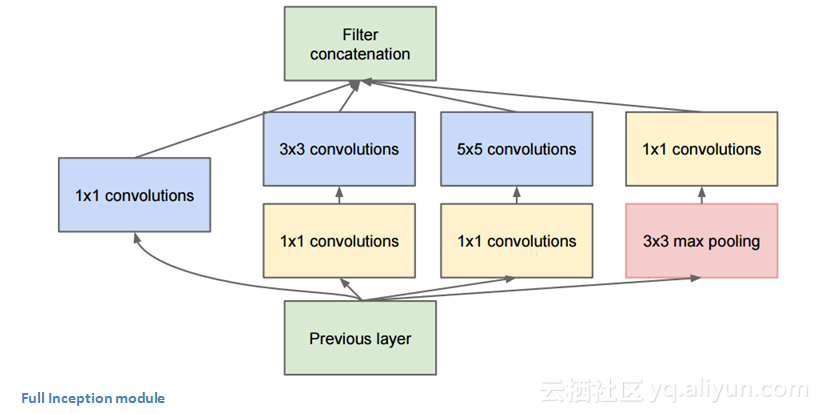
让我们来看看它的内部组成。
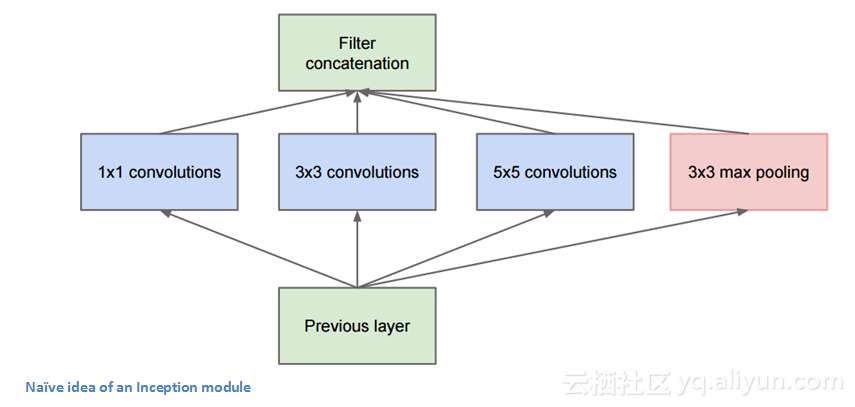
底部的绿色框是输入,最上面的是输出。在传统的卷积网络的每一层,你必须选择是否进行池化或卷积操作(也可以选择过滤器大小)。Inception模块可以所有这些操作。这正是GoogLeNet的亮点之一。
这样会导致太多的输出,为了解决这一问题,作者在3*3和5*5的层前面添加1*1 的卷积操作对其进行降维。举个例子,假设输入数组为100*100*60(这不一定是图像大小,只是网络任意一层的输入)。使用20个1*1卷积滤波器可以让将数组降到100*100*20。这就意味着3*3和5*5的卷积操作不会有大量的操作。由于我们正在降低数组的维度,这一操作被称作“特征池化”,这和我们用普通的最大池化层来减小图片的高度和宽度比较相似。
GoogLeNet模型有什么用?这个网络由网络层的一个网络、一个中型卷积滤波器、一个大型卷积滤波器和一个池化操作组成。卷积网络能够提取输入数组的细节信息,而5*5滤波器能够覆盖输入较大范围的接受野,因此也能够提取其细节信息。你还可以在GoogLeNet模型中进行池化操作,这有助于降低空间维度并避免过拟合。最重要的是,在每个卷积层之后都有ReLU函数,这有助于改善网络的非线性。基本上,网络在执行这些操作的同时,仍能够保持计算上的良好性能。
主要论点
1.在整个架构中使用了九个Inception模块,总共超过100层!
2.没有使用全连接层! 他们使用平均池化,这大大节省了参数的数量。
3.使用的参数比AlexNet架构少12倍。
4.利用R-CNN的概念介绍其检测架构。
5.Inception模块有了版本更新(版本6和7)。
重要性
GoogLeNet模型是第一个引入“卷积神经网络层并不需要依次叠加”这一理念的架构之一,作为Inception模块的一部分,富有创造性的层结构提高了整体性能和计算效率。(转载自阿里云栖社区)

