在过去几年中,深度学习改变了整个人工智能的发展。深度学习技术已经开始在医疗保健,金融,人力资源,零售,地震检测和自动驾驶汽车等领域的应用程序中出现。至于现有的成果表现也一直在稳步提高。
在学术层面,机器学习领域已经变得非常重要了,以至于每20分钟就会出现一篇新的科学文章。
在本文中,我将介绍2018年深度学习的一些主要进展,与2017年深度学习进展版本一样,我没有办法进行详尽的审查。我只想分享一些给我留下最深刻印象的领域成就。
语言模型:Google的BERT
在自然语言处理(NLP)中,语言模型是可以估计一组语言单元(通常是单词序列)的概率分布的模型。在该领域有很多有趣的模型,因为它们可以以很低的成本构建,并且显着改进了几个NLP任务,例如机器翻译,语音识别和内容解析。
历史上,最著名的方法之一是基于马尔可夫模型和n-gram。随着深度学习的出现,出现了基于长短期记忆网络(LSTM)更强大的模型。虽然高效,但现有模型通常是单向的,这意味着只有单词的上下文才会被考虑。
去年10月,Google AI语言团队发表了一篇引起社区轰动的论文。BERT是一种新的双向语言模型,它已经实现了11项复杂NLP任务的最新结果,包括情感分析、问答和复述检测。
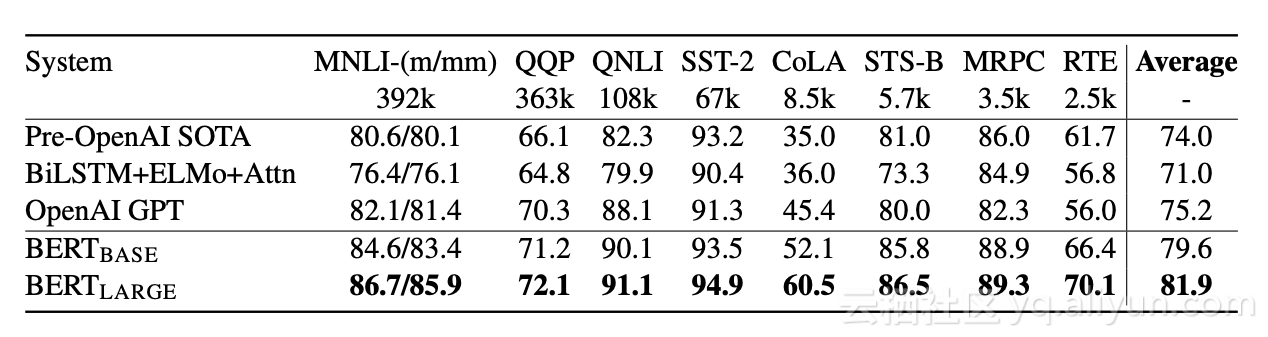
GLUE基准的比较结果
预训练BERT的策略不同于传统的从左到右或从右到左的选项。新颖性包括:
· 随机屏蔽一定比例的输入词,然后预测那些被屏蔽的词;这可以在多层次的背景下保持间接“看到自己”的词语。
· 构建二元分类任务以预测句子B之后是否紧跟句子A,这允许模型确定句子之间的关系,这种现象不是由经典语言建模直接捕获的。
至于实施,Google AI开源了他们的论文代码,该代码基于TensorFlow。其中一些在PyTorch也能实现,例如Thomas Wolf和Junseong Kim的实现。
BERT对业务应用程序的影响很大,因为这种改进会影响NLP的各个方面。这可以在机器翻译,聊天机器人行为,自动电子邮件响应和客户审查分析中获得更准确的结果。
视频到视频合成
我们通常习惯由图形引擎创建的模拟器和视频游戏进行环境交互。虽然令人印象深刻,但经典方法的成本很高,因为必须精心指定场景几何、材料、照明和其他参数。一个很好的问题是:是否可以使用例如深度学习技术自动构建这些环境。
在他们的视频到视频合成论文中,NVIDIA的研究人员解决了这个问题。他们的目标是在源视频和输出视频之间提供映射功能,精确描绘输入内容。作者将其建模为分布匹配问题,其目标是使自动创建视频的条件分布尽可能接近实际视频的条件分布。为实现这一目标,他们建立了一个基于生成对抗网络(GAN)的模型。在GAN框架内的关键思想是,生成器试图产生真实的合成数据,使得鉴别器无法区分真实数据和合成数据。他们定义了一个时空学习目标,旨在实现暂时连贯的视频。
结果非常惊人,如下面的图片所示:

输入视频位于左上象限,它是来自Cityscapes数据集的街道场景视频的分段图。作者将他们的结果(右下)与两个基线进行比较:pix2pixHD(右上)和COVST(左下)。
这种方法甚至可以用于执行未来的视频预测。由于NVIDIA开源vid2vid代码(基于PyTorch),你可以尝试执行它。
改进词嵌入
去年,我写了关于字嵌入在NLP中的重要性,并且相信这是一个在不久的将来会得到更多关注的研究课题。任何使用过词嵌入的人都知道,一旦通过组合性检查的兴奋(即King-Man+Woman=Queen)已经过去,因为在实践中仍有一些限制。也许最重要的是对多义不敏感,无法表征词之间确切建立的关系。到底同义词Hyperonyms?另一个限制涉及形态关系:词嵌入模型通常无法确定诸如驾驶员和驾驶之类的单词在形态上是相关的。
在题为“深度语境化词语表示”(被认为是NAACL 2018年的优秀论文)的论文中,来自艾伦人工智能研究所和Paul G. Allen计算机科学与工程学院的研究人员提出了一种新的深层语境化词汇表示方法。同时模拟单词使用的复杂特征(例如语法和语义)以及这些用途如何在语言环境(即多义词)中变化。
他们的提议的中心主题,称为语言模型嵌入(ELMo),是使用它的整个上下文或整个句子来对每个单词进行矢量化。为了实现这一目标,作者使用了深度双向语言模型(biLM),该模型在大量文本上进行了预训练。另外,由于表示基于字符,因此可以捕获单词之间的形态句法关系。因此,当处理训练中未见的单词(即词汇外单词)时,该模型表现得相当好。
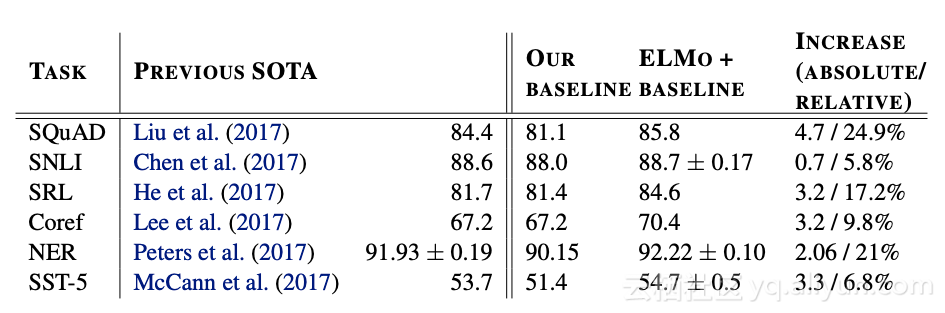
六项基准NLP任务中最先进模型的比较结果。
作者表明,通过简单地将ELMo添加到现有的最先进解决方案中,结果可以显著改善难以处理的NLK任务,例如文本解释,共指解析和问答,与Google的BERT表示一样,ELMo是该领域的重要贡献,也有望对业务应用程序产生重大影响。
视觉任务空间结构的建模
视觉任务是否相关?这是斯坦福大学和加州大学伯克利分校的研究人员在题为“Taskonomy:Disentangling Task Transfer Learning”的论文中提出的问题,该论文获得了2018年CVPR的最佳论文奖。
可以合理地认为某些视觉任务之间存在某种联系。例如,知道表面法线可以帮助估计图像的深度。在这种情况下,迁移学习技术-或重用监督学习结果的可能性将极大的提高。
作者提出了一种计算方法,通过在26个常见的视觉任务中找到转移学习依赖关系来对该结构进行建模,包括对象识别、边缘检测和深度估计。输出是用于任务转移学习的计算分类图。
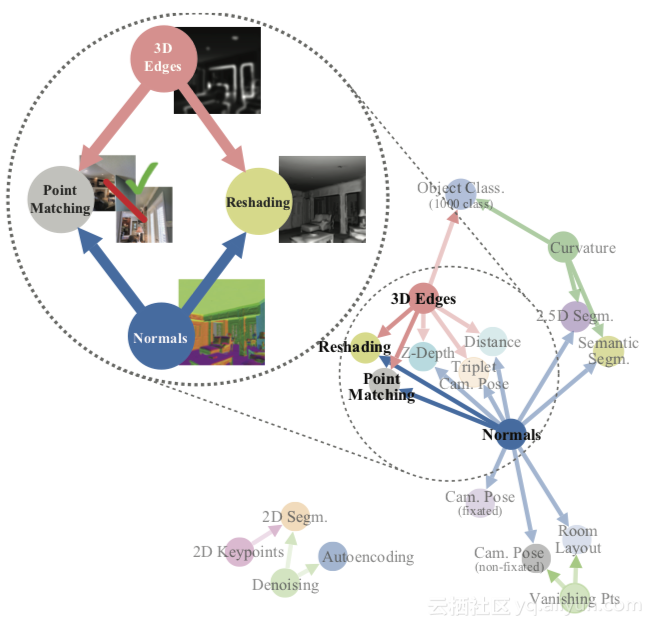
由计算任务分类法发现的示例任务结构。
上图显示了计算分类法任务发现的示例任务结构。在该示例中,该方法告知我们如果组合了表面法线估计器和遮挡边缘检测器的学习特征,则可以用很少的标记数据快速训练用于重新整形和点匹配的模型。
减少对标签数据的需求是这项工作的主要关注点之一。作者表明,可以通过粗略地减小求解一组10个任务所需的标记的数据点的总数2/3(具有独立训练相比),同时保持几乎相同的性能。这是对实际用例的重要发现,因此有望对业务应用程序产生重大影响。
微调通用语言模型以进行文本分类
深度学习模型为NLP领域做出了重大贡献,为一些常见任务提供了最先进的结果。但是,模型通常从头开始训练,这需要大量数据并且需要相当长的时间。
Howard和Ruder提出了一种归纳迁移学习方法,称为通用语言模型微调(ULMFiT)。主要思想是微调预训练的语言模型,以使其适应特定的NLP任务。这是一种精明的方法,使我们能够处理我们没有大量数据的特定任务。
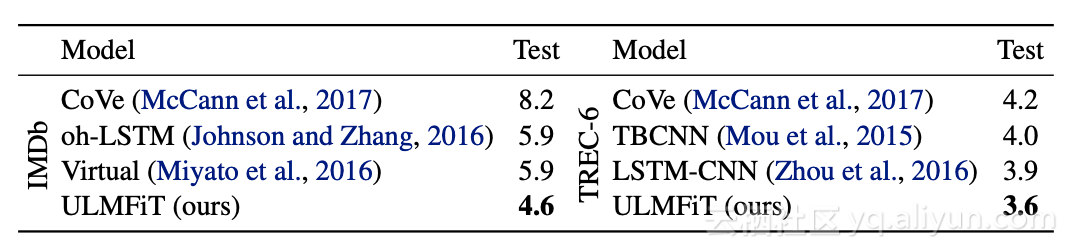
两个文本分类数据集上的测试错误率(越低越好)。
他们的方法优于六个文本分类任务的最新结果,将错误率降低了18-24%。关于训练数据的数量,结果也非常惊人:只有100个标记样本和50K未标记样本,该方法实现了与10K标记样本从头开始训练的模型相同的性能。
同样,这些结果证明迁移学习是该领域的关键概念。你可以在这里查看他们的代码和预训练模型。
最后的想法
与去年的情况一样,2018年深度学习技术的使用持续增加。特别是,今年的特点是迁移学习技术越来越受到关注。从战略角度来看,这可能是我认为今年最好的结果,我希望这种趋势在将来可以继续下去。
我在这篇文章中没有探讨的其他一些进展同样引人注目。例如,强化学习的进步,例如能够击败Dota 2的职业玩家的惊人的OpenAI Five机器人。另外,我认为现在球CNN,特别有效的分析球面图像,以及PatternNet和PatternAttribution,这两种技术所面临的神经网络的一个主要缺点:解释深层网络的能力。
上述所有技术发展对业务应用程序的影响是巨大的,因为它们影响了NLP和计算机视觉的许多领域。我们可能会在机器翻译、医疗诊断、聊天机器人、仓库库存管理、自动电子邮件响应、面部识别和客户审查分析等方面观察到改进的结果。
从科学的角度来看,我喜欢Gary Marcus撰写的深度学习评论。他清楚地指出了当前深度学习方法的局限性,并表明如果深度学习方法得到其他学科和技术的见解(如认知和发展心理学、符号操作和混合建模)的补充,人工智能领域将获得相当大的收益。无论你是否同意他,我认为值得阅读他的论文。
本文由阿里云云栖社区组织翻译。
文章原标题《major-advancements-deep-learning-2018》
作者:Javier译者:虎说八道,审校:袁虎。

