Julia是一种多范式函数编程语言,主要用于机器学习和统计编程。
_wps图片.jpg")
Python是另一种用于机器学习的多范式编程语言,尽管大家通常认为Python是面向对象的。
另一方面,Julia更多的是基于功能范式。虽然Julia当然没有Python那么受欢迎,但是将Julia用于数据科学有一些巨大的好处,使得它在Python的许多情况下都是一个更好的选择。
1. 广泛
Python的应用范围很广泛,很多事情可以用Python做,但不能用Julia做。当然,这只是本地语言,因为我们现在讨论的多功能性指的是语言的多功能性。Julia代码在R、Latex、Python和C中都是通用的可执行代码,这意味着典型的数据科学项目有可能只编写一次,并从包装器中的另一种语言以Julia为本机进行编译,或者只发送字符串。
PyCall和RCall也是相当大的交易。考虑到Julia的一个严重缺点实际上是包,因此在需要时调用Python和R非常方便。PyCall在Julia中得到了很好的实现,而且做得非常好,非常有用。
2. 多分派
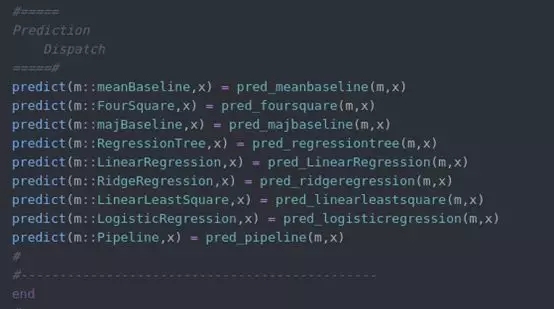
Julia是一种非常独特的类型语言,它有自己的怪癖和特性,但其中最酷的特性之一是Julia的多分派。首先也是最重要的是,Julia的多分派速度很快。除此之外,使用Julia的多分派使得函数定义作为结构的属性应用成为可能。
不仅如此,使用Julia的多分派使得函数可扩展。这对包扩展是一个很大的好处,因为无论何时显示导入方法,用户都可以更改它。显式导入方法并将其扩展为将结构路由到新函数会很容易。
3. 速度

谈到Julia不谈速度是很难的。Julia以速度快而自豪。Julia与Python不同,Python是一种编译语言,它主要是用自己的基础编写的。然而,与C等其他编译语言不同,Julia是在运行时编译的,而传统语言是在执行之前编译的。
Julia,特别是写得好的时候,可以和C语言一样快,有时甚至比C语言更快。Julia使用即时(JIT)编译器,编译速度非常快,尽管它编译起来更像是一种解释语言,而不是像C语言或Fortran这样的传统低级编译语言。
4. 包管理器(Package Manager)
首先要说的是,Julia的Pkg包管理器是Python的Pip包管理器之上的整个世界。Pkg附带了自己的REPL和Julia包,可以从中构建、添加、删除和实例化包。这特别方便,因为Pkg与Git的连接。更新很容易,添加软件包总是很容易的,而且总的来说Pkg在Python的Pip上随时都可以使用。
5. 在机器学习中的应用

来源:Pexels
与Python不同,Julia用于统计和机器学习。Python是在90年代早期作为一种简单的面向对象语言创建的,尽管从那时起它已经发生了很大的变化。考虑到Python的历史,以及Python的广泛用途(因为它非常流行),使用Julia这种专门为高级统计工作而设计的语言可以显示出很多好处。
Julia比Python稍胜一筹的另一个方面是线性代数。Vanilla Python可以通过线性代数,但vanilla Julia可以飞跃线性代数。当然,这是因为Python从未打算支持机器学习中的所有矩阵和方程。这不是Python的坏处,尤其是在NumPy上,但是就一个没有包的体验而言,Julia觉得这类数学更受欢迎。Julia的操作数系统比Python的更接近R,这是一个很大的好处。大多数线性代数是更快和更容易做。下面展示一个向量点积方程(dot-product equation),以便进一步说明这一点:
Python -> y =np.dot(array1,array2) R -> y <- array1 * array2 Julia -> y = array1 .* array2
结论

来源:Pexels
使用哪种语言并不重要,不管是R、Julia、Python还是Scala。然而,需要注意的是,每一种语言都有其缺点,没有一种语言会成为“完美的语言”。如果你在编程上多才多艺,从机器学习到GUI再到API,情况尤其如此。Python有更好的包,通常如果项目足够小,我会转向Python,但是对于具有数百万观察的数据集,甚至很难用Python读取此类数据。
总之,我很看好Julia.的未来。Julia写起来很有趣,而且将来在数据科学领域可能会变得更加可行。
(文章来源:读芯术)

