基于 Redis 的分布式锁对大家来说并不陌生,可是你的分布式锁有失败的时候吗?在失败的时候可曾怀疑过你在用的分布式锁真的靠谱吗?以下是结合自己的踩坑经验总结的一些经验之谈。

图片来自 Pexels
你真的需要分布式锁吗?
用到分布式锁说明遇到了多个进程共同访问同一个资源的问题。
一般是在两个场景下会防止对同一个资源的重复访问:
提高效率。比如多个节点计算同一批任务,如果某个任务已经有节点在计算了,那其他节点就不用重复计算了,以免浪费计算资源。不过重复计算也没事,不会造成其他更大的损失。也就是允许偶尔的失败。
保证正确性。这种情况对锁的要求就很高了,如果重复计算,会对正确性造成影响。这种不允许失败。
引入分布式锁势必要引入一个第三方的基础设施,比如 MySQL,Redis,Zookeeper 等。
这些实现分布式锁的基础设施出问题了,也会影响业务,所以在使用分布式锁前可以考虑下是否可以不用加锁的方式实现?
不过这个不在本文的讨论范围内,本文假设加锁的需求是合理的,并且偏向于上面的第二种情况,为什么是偏向?因为不存在 100% 靠谱的分布式锁,看完下面的内容就明白了。
从一个简单的分布式锁实现说起
分布式锁的 Redis 实现很常见,自己实现和使用第三方库都很简单,至少看上去是这样的,这里就介绍一个最简单靠谱的 Redis 实现。
最简单的实现
实现很经典了,这里只提两个要点:
加锁和解锁的锁必须是同一个,常见的解决方案是给每个锁一个钥匙(唯一 ID),加锁时生成,解锁时判断。
不能让一个资源永久加锁。常见的解决方案是给一个锁的过期时间。当然了还有其他方案,后面再说。
一个可复制粘贴的实现方式如下:
加锁:
public static boolean tryLock(String key, String uniqueId, int seconds) { return "OK".equals(jedis.set(key, uniqueId, "NX", "EX", seconds)); }这里调用了 SET key value PX milliseoncds NX,不明白这个命令的可以参考 SET key value [EX seconds|PX milliseconds] [NX|XX] [KEEPTTL]:
https://redis.io/commands/set
解锁:
public static boolean releaseLock(String key, String uniqueId) { String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then " + "return redis.call('del', KEYS[1]) else return 0 end"; return jedis.eval( luaScript, Collections.singletonList(key), Collections.singletonList(uniqueId) ).equals(1L); }这段实现的精髓在那个简单的 Lua 脚本上,先判断唯一 ID 是否相等再操作。
靠谱吗?
这样的实现有什么问题呢?
单点问题。上面的实现只要一个 Master 节点就能搞定,这里的单点指的是单 Master,就算是个集群,如果加锁成功后,锁从 Master 复制到 Slave 的时候挂了,也是会出现同一资源被多个 Client 加锁的。
执行时间超过了锁的过期时间。上面写到为了不出现一直上锁的情况,加了一个兜底的过期时间,时间到了锁自动释放,但是,如果在这期间任务并没有做完怎么办?由于 GC 或者网络延迟导致的任务时间变长,很难保证任务一定能在锁的过期时间内完成。
如何解决这两个问题呢?试试看更复杂的实现吧。
Redlock 算法
对于第一个单点问题,顺着 Redis 的思路,接下来想到的肯定是 Redlock 了。
Redlock 为了解决单机的问题,需要多个(大于 2)Redis 的 Master 节点,多个 Master 节点互相独立,没有数据同步。
Redlock 的实现如下:
①获取当前时间。
②依次获取 N 个节点的锁。每个节点加锁的实现方式同上。这里有个细节,就是每次获取锁的时候的过期时间都不同,需要减去之前获取锁的操作的耗时,
比如传入的锁的过期时间为 500ms,获取第一个节点的锁花了 1ms,那么第一个节点的锁的过期时间就是 499ms;获取第二个节点的锁花了 2ms,那么第二个节点的锁的过期时间就是 497ms。
如果锁的过期时间小于等于 0 了,说明整个获取锁的操作超时了,整个操作失败。
③判断是否获取锁成功。如果 Client 在上述步骤中获取到了(N/2+1)个节点锁,并且每个锁的过期时间都是大于 0 的,则获取锁成功,否则失败。失败时释放锁。
④释放锁。对所有节点发送释放锁的指令,每个节点的实现逻辑和上面的简单实现一样。
为什么要对所有节点操作?因为分布式场景下从一个节点获取锁失败不代表在那个节点上加速失败,可能实际上加锁已经成功了,但是返回时因为网络抖动超时了。
以上就是大家常见的 Redlock 实现的描述了,一眼看上去就是简单版本的多 Master 版本,如果真是这样就太简单了,接下来分析下这个算法在各个场景下是怎样被玩坏的。
分布式锁的坑
高并发场景下的问题
以下问题不是说在并发不高的场景下不容易出现,只是在高并发场景下出现的概率更高些而已。
性能问题来自于以下两方面:
①获取锁的时间上。如果 Redlock 运用在高并发的场景下,存在 N 个 Master 节点,一个一个去请求,耗时会比较长,从而影响性能。
这个好解决,通过上面描述不难发现,从多个节点获取锁的操作并不是一个同步操作,可以是异步操作,这样可以多个节点同时获取。
即使是并行处理的,还是得预估好获取锁的时间,保证锁的 TTL>获取锁的时间+任务处理时间。
②被加锁的资源太大。加锁的方案本身就是会为了正确性而牺牲并发的,牺牲和资源大小成正比,这个时候可以考虑对资源做拆分。
拆分的方式有如下两种:
①从业务上将锁住的资源拆分成多段,每段分开加锁。比如,我要对一个商户做若干个操作,操作前要锁住这个商户,这时我可以将若干个操作拆成多个独立的步骤分开加锁,提高并发。
②用分桶的思想,将一个资源拆分成多个桶,一个加锁失败立即尝试下一个。比如批量任务处理的场景,要处理 200w 个商户的任务,为了提高处理速度,用多个线程,每个线程取 100 个商户处理,就得给这 100 个商户加锁。
如果不加处理,很难保证同一时刻两个线程加锁的商户没有重叠,这时可以按一个维度。
比如某个标签,对商户进行分桶,然后一个任务处理一个分桶,处理完这个分桶再处理下一个分桶,减少竞争。
重试的问题:无论是简单实现还是 Redlock 实现,都会有重试的逻辑。
如果直接按上面的算法实现,是会存在多个 Client 几乎在同一时刻获取同一个锁,然后每个 Client 都锁住了部分节点,但是没有一个 Client 获取大多数节点的情况。
解决的方案也很常见,在重试的时候让多个节点错开,错开的方式就是在重试时间中加一个随机时间。这样并不能根治这个问题,但是可以有效缓解问题,亲试有效。
节点宕机
对于单 Master 节点且没有做持久化的场景,宕机就挂了,这个就必须在实现上支持重复操作,自己做好幂等。
对于多 Master 的场景,比如 Redlock,我们来看这样一个场景:
假设有 5 个 Redis 的节点:A、B、C、D、E,没有做持久化。
Client1 从 A、B、C 这3 个节点获取锁成功,那么 client1 获取锁成功。
节点 C 挂了。
Client2 从 C、D、E 获取锁成功,client2 也获取锁成功,那么在同一时刻 Client1 和 Client2 同时获取锁,Redlock 被玩坏了。
怎么解决呢?最容易想到的方案是打开持久化。持久化可以做到持久化每一条 Redis 命令,但这对性能影响会很大,一般不会采用,如果不采用这种方式,在节点挂的时候肯定会损失小部分的数据,可能我们的锁就在其中。
另一个方案是延迟启动。就是一个节点挂了修复后,不立即加入,而是等待一段时间再加入,等待时间要大于宕机那一刻所有锁的最大 TTL。
但这个方案依然不能解决问题,如果在上述步骤 3 中 B 和 C 都挂了呢,那么只剩 A、D、E 三个节点,从 D 和 E 获取锁成功就可以了,还是会出问题。
那么只能增加 Master 节点的总量,缓解这个问题了。增加 Master 节点会提高稳定性,但是也增加了成本,需要在两者之间权衡。
任务执行时间超过锁的 TTL
之前产线上出现过因为网络延迟导致任务的执行时间远超预期,锁过期,被多个线程执行的情况。
这个问题是所有分布式锁都要面临的问题,包括基于 Zookeeper 和 DB 实现的分布式锁,这是锁过期了和 Client 不知道锁过期了之间的矛盾。
在加锁的时候,我们一般都会给一个锁的 TTL,这是为了防止加锁后 Client 宕机,锁无法被释放的问题。
但是所有这种姿势的用法都会面临同一个问题,就是没发保证 Client 的执行时间一定小于锁的 TTL。
虽然大多数程序员都会乐观的认为这种情况不可能发生,我也曾经这么认为,直到被现实一次又一次的打脸。
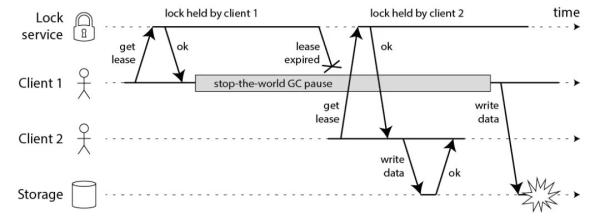
Martin Kleppmann 也质疑过这一点,这里直接用他的图:
Client1 获取到锁。
Client1 开始任务,然后发生了 STW 的 GC,时间超过了锁的过期时间。
Client2 获取到锁,开始了任务。
Client1 的 GC 结束,继续任务,这个时候 Client1 和 Client2 都认为自己获取了锁,都会处理任务,从而发生错误。
Martin Kleppmann 举的是 GC 的例子,我碰到的是网络延迟的情况。不管是哪种情况,不可否认的是这种情况无法避免,一旦出现很容易懵逼。
如何解决呢?一种解决方案是不设置 TTL,而是在获取锁成功后,给锁加一个 watchdog,watchdog 会起一个定时任务,在锁没有被释放且快要过期的时候会续期。
这样说有些抽象,下面结合 Redisson 源码说下:
public class RedissonLock extends RedissonExpirable implements RLock { ... @Override public void lock() { try { lockInterruptibly(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } @Override public void lock(long leaseTime, TimeUnit unit) { try { lockInterruptibly(leaseTime, unit); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } ... }Redisson 常用的加锁 API 是上面两个,一个是不传入 TTL,这时是 Redisson 自己维护,会主动续期。
另外一种是自己传入 TTL,这种 Redisson 就不会帮我们自动续期了,或者自己将 leaseTime 的值传成 -1,但是不建议这种方式,既然已经有现成的 API 了,何必还要用这种奇怪的写法呢。
接下来分析下不传参的方法的加锁逻辑:
public class RedissonLock extends RedissonExpirable implements RLock { ... public static final long LOCK_EXPIRATION_INTERVAL_SECONDS = 30; protected long internalLockLeaseTime = TimeUnit.SECONDS.toMillis(LOCK_EXPIRATION_INTERVAL_SECONDS); @Override public void lock() { try { lockInterruptibly(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } @Override public void lockInterruptibly() throws InterruptedException { lockInterruptibly(-1, null); } @Override public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException { long threadId = Thread.currentThread().getId(); Long ttl = tryAcquire(leaseTime, unit, threadId); // lock acquired if (ttl == null) { return; } RFuture<RedissonLockEntry> future = subscribe(threadId); commandExecutor.syncSubscription(future); try { while (true) { ttl = tryAcquire(leaseTime, unit, threadId); // lock acquired if (ttl == null) { break; } // waiting for message if (ttl >= 0) { getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS); } else { getEntry(threadId).getLatch().acquire(); } } } finally { unsubscribe(future, threadId); } // get(lockAsync(leaseTime, unit)); } private Long tryAcquire(long leaseTime, TimeUnit unit, long threadId) { return get(tryAcquireAsync(leaseTime, unit, threadId)); } private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) { if (leaseTime != -1) { return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG); } RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(LOCK_EXPIRATION_INTERVAL_SECONDS, TimeUnit.SECONDS, threadId, RedisCommands.EVAL_LONG); ttlRemainingFuture.addListener(new FutureListener<Long>() { @Override public void operationComplete(Future<Long> future) throws Exception { if (!future.isSuccess()) { return; } Long ttlRemaining = future.getNow(); // lock acquired if (ttlRemaining == null) { scheduleExpirationRenewal(threadId); } } }); return ttlRemainingFuture; } private void scheduleExpirationRenewal(final long threadId) { if (expirationRenewalMap.containsKey(getEntryName())) { return; } Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() { @Override public void run(Timeout timeout) throws Exception { RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN, "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " + "redis.call('pexpire', KEYS[1], ARGV[1]); " + "return 1; " + "end; " + "return 0;", Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId)); future.addListener(new FutureListener<Boolean>() { @Override public void operationComplete(Future<Boolean> future) throws Exception { expirationRenewalMap.remove(getEntryName()); if (!future.isSuccess()) { log.error("Can't update lock " + getName() + " expiration", future.cause()); return; } if (future.getNow()) { // reschedule itself scheduleExpirationRenewal(threadId); } } }); } }, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS); if (expirationRenewalMap.putIfAbsent(getEntryName(), task) != null) { task.cancel(); } } ... }可以看到,最后加锁的逻辑会进入到 org.redisson.RedissonLock#tryAcquireAsync 中,在获取锁成功后,会进入 scheduleExpirationRenewal。
这里面初始化了一个定时器,dely 的时间是 internalLockLeaseTime/3。
在 Redisson 中,internalLockLeaseTime 是 30s,也就是每隔 10s 续期一次,每次 30s。
如果是基于 Zookeeper 实现的分布式锁,可以利用 Zookeeper 检查节点是否存活,从而实现续期,Zookeeper 分布式锁没用过,不详细说。
不过这种做法也无法百分百做到同一时刻只有一个 Client 获取到锁,如果续期失败,比如发生了 Martin Kleppmann 所说的 STW 的 GC,或者 Client 和 Redis 集群失联了,只要续期失败,就会造成同一时刻有多个 Client 获得锁了。
在我的场景下,我将锁的粒度拆小了,Redisson 的续期机制已经够用了。如果要做得更严格,得加一个续期失败终止任务的逻辑。
这种做法在以前 Python 的代码中实现过,Java 还没有碰到这么严格的情况。
这里也提下 Martin Kleppmann 的解决方案,我自己觉得这个方案并不靠谱,原因后面会提到。
他的方案是让加锁的资源自己维护一套保证不会因加锁失败而导致多个 Client 在同一时刻访问同一个资源的情况。
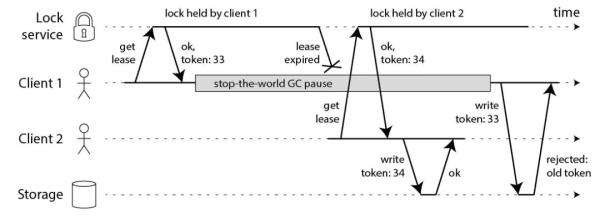
在客户端获取锁的同时,也获取到一个资源的 Token,这个 Token 是单调递增的,每次在写资源时,都检查当前的 Token 是否是较老的 Token,如果是就不让写。
对于上面的场景,Client1 获取锁的同时分配一个 33 的 Token,Client2 获取锁的时候分配一个 34 的 Token。
在 Client1 GC 期间,Client2 已经写了资源,这时最大的 Token 就是 34 了,Client1 从 GC 中回来,再带着 33 的 Token 写资源时,会因为 Token 过期被拒绝。
这种做法需要资源那一边提供一个 Token 生成器。对于这种 fencing 的方案,我有几点问题:
①无法保证事务。示意图中画的只有 34 访问了 Storage,但是在实际场景中,可能出现在一个任务内多次访问 Storage 的情况,而且必须是原子的。
如果 Client1 带着 33 的 Token 在 GC 前访问过一次 Storage,然后发生了 GC。
Client2 获取到锁,带着 34 的 Token 也访问了 Storage,这时两个 Client 写入的数据是否还能保证数据正确?
如果不能,那么这种方案就有缺陷,除非 Storage 自己有其他机制可以保证,比如事务机制;如果能,那么这里的 Token 就是多余的,fencing 的方案就是多此一举。
②高并发场景不实用。因为每次只有最大的 Token 能写,这样 Storage 的访问就是线性的,在高并发场景下,这种方式会极大的限制吞吐量,而分布式锁也大多是在这种场景下用的,很矛盾的设计。
③这是所有分布式锁的问题。这个方案是一个通用的方案,可以和 Redlock 用,也可以和其他的 lock 用。所以我理解仅仅是一个和 Redlock 无关的解决方案。
系统时钟漂移
这个问题只是考虑过,但在实际项目中并没有碰到过,因为理论上是可能出现的,这里也说下。
Redis 的过期时间是依赖系统时钟的,如果时钟漂移过大时会影响到过期时间的计算。
为什么系统时钟会存在漂移呢?先简单说下系统时间,Linux 提供了两个系统时间:clock realtime 和 clock monotonic。
clock realtime 也就是 xtime/wall time,这个时间时可以被用户改变的,被 NTP 改变,gettimeofday 拿的就是这个时间,Redis 的过期计算用的也是这个时间。
clock monotonic ,直译过来时单调时间,不会被用户改变,但是会被 NTP 改变。
最理想的情况时,所有系统的时钟都时时刻刻和NTP服务器保持同步,但这显然时不可能的。
导致系统时钟漂移的原因有两个:
系统的时钟和 NTP 服务器不同步。这个目前没有特别好的解决方案,只能相信运维同学了。
clock realtime 被人为修改。在实现分布式锁时,不要使用 clock realtime。
不过很可惜,Redis 使用的就是这个时间,我看了下 Redis 5.0 源码,使用的还是 clock realtime。
Antirez 说过改成 clock monotonic 的,不过大佬还没有改。也就是说,人为修改 Redis 服务器的时间,就能让 Redis 出问题了。
总结
本文从一个简单的基于 Redis 的分布式锁出发,到更复杂的 Redlock 的实现,介绍了在使用分布式锁的过程中才踩过的一些坑以及解决方案。
作者:陈寒立
简介:一个不误正业的程序员。先后在物流金融组、物流末端业务组和压力平衡组打过杂,技术栈从 Python 玩到了 Java,依然没学会好好写业务代码,梦想着用抽象的模型拯救业务于水火之中。
编辑:陶家龙
出处:饿了么物流技术团队

