最近,GPT-3火了!相信你已经在网上看到各种有关GPT-3的演示。这个由OpenAI创建的大型机器学习模型,它不仅可以自己写论文,还会写诗歌,就连你写的代码都能帮你写了。
下面还是先让你看看GPT-3的威力吧,首先来看看GPT3在问答任务上的表现:

无论你的问题是天马行空的脑筋急转弯,还是有逻辑性极强的数学问题,它都能对答如流。
开发者Sharif Shameem用GPT-3做了一个生成器,你只要输入你所需的布局,它就能为你生成JSX代码,如视频所示。
还有人在 Google 表格里开发了一个新的 GPT3 函数,除了简单的数学运算之外,它还可以自动查找美国各州的人口以及创建年份:
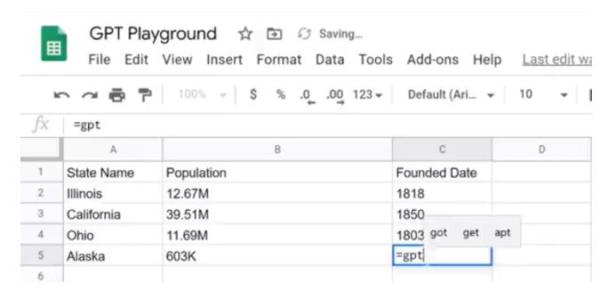
除此之外,它还能查到Twitter账号:

遗憾的是,如果你想试用GPT-3,你得先拿到体验资格才行,但是此模型创建的应用程序似乎有无限可能,通过它你可以使用纯英语查询SQL数据库,自动注释代码,自动生成代码,编写热门文章标题,甚至帮助猿妹我写出一篇爆文。
GPT-3是什么?
GPT-3是一种神经网络驱动的语言模型。与大多数语言模型一样,GPT-3在未标记的文本数据集上进行了大量的训练(训练数据包括Common Crawl和Wikipedia),从文本中随机删除单词或短语,并且模型必须学会仅使用周围的单词作为上下文来填充单词或短语。这是一个简单的培训任务,可以产生功能强大且可推广的模型。
GPT-3模型架构本身就是一个基于单向transformer语言模型。这种架构在2-3年前开始流行,流行的NLP模型BERT和GPT-3的前身GPT-2都是基于transformer构建。从架构的角度来看,GPT-3实际上并不是很新颖!
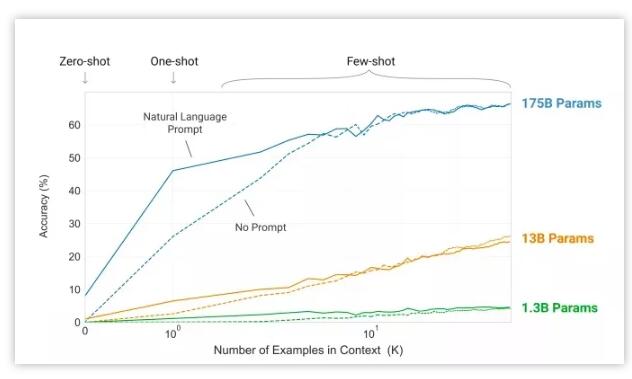
它之所以会这么火,是因为GPT-3的模型尺寸增大到了1750亿,并且使用45TB数据进行训练,是有史以来创建的最大语言模型。源于它的参数模型巨大,因此可以完成许多其他模型无法完成的事情,就像前面所说的,你可以让它成为一名翻译家、作家、诗人、程序员等。
如果你对GPT-3的模型参数1750亿感到有些抽象,那么,我举个例子,你应该就懂了:
BERT模型有3亿参数
GPT-3模型的前身GPT-2有15亿个参数
英伟达的Megatron-BERT有80亿参数
微软Turing NLP,有170亿参数
就连排名第二的微软Turing NLP的数据参数和GPT-3都不是一个量级的。

值得一提的是,这次的GPT-3论文作者足足有31位,论文体量更是高达72页,网友都惊呼,现在PTM的工作是要开始pk论文页数了吗?
和往常一样,GPT-3立即放出了GitHub项目页面,你可以在上面找到各种各样有趣的demo,最后附上Github地址:https://github.com/openai/gpt-3。

