
本文转自雷锋网,如需转载请至雷锋网官网申请授权。
在本文中,我们将用C语言从头开始实现一个基本的神经网络框架。之所以在C语言中这样做,是因为大多数库和其他高级语言(如Python)都抽象出了实现细节。在C语言中实现反向传播实际上会让我们更详细地了解改变权重和偏差是如何改变网络的整体行为的。
注意:本文假设您了解反向传播算法背后的数学原理。
我们的目标是建立一个通用的框架,其中的层数和神经元将由用户根据他的要求指定。因此,我们将从用户获得以下输入来定义我们的神经网络框架:
1. 层数
2.每层神经元数目
3.学习速率
4.训练例子
5.输出标签
定义层和神经元结构:
一旦我们有了层的数量和每层神经元的数量,我们就可以创建我们的神经网络的架构。但首先我们必须定义神经元和层的结构。
神经元结构将包含以下参数:
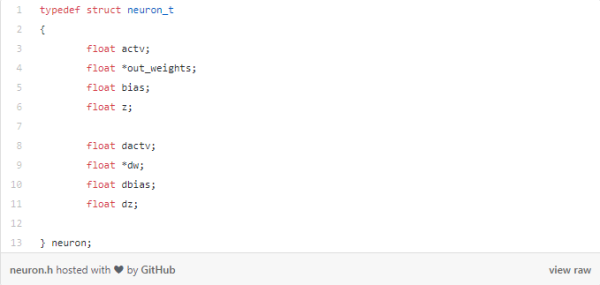
层结构将有许多神经元在该层和一个指针的neuron_t结构。

创建架构:
现在,让我们使用create_architecture()函数创建我们的神经网络的体系结构。
在下面的代码片段中,外部For循环创建层,内部For循环将指定数量的神经元添加到该层。我们也随机初始化神经元的权值在0到1之间。

训练的例子:
我们将使用get_input()函数存储训练示例:
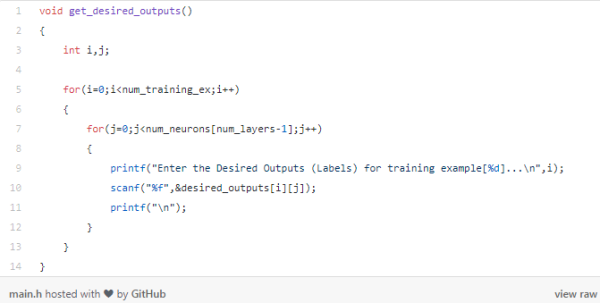
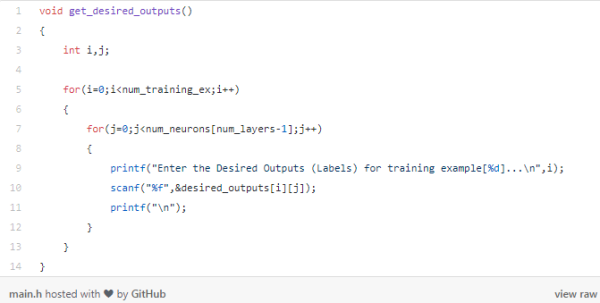
得到输出标签:
我们将使用get_desired_exports()函数存储输出标签
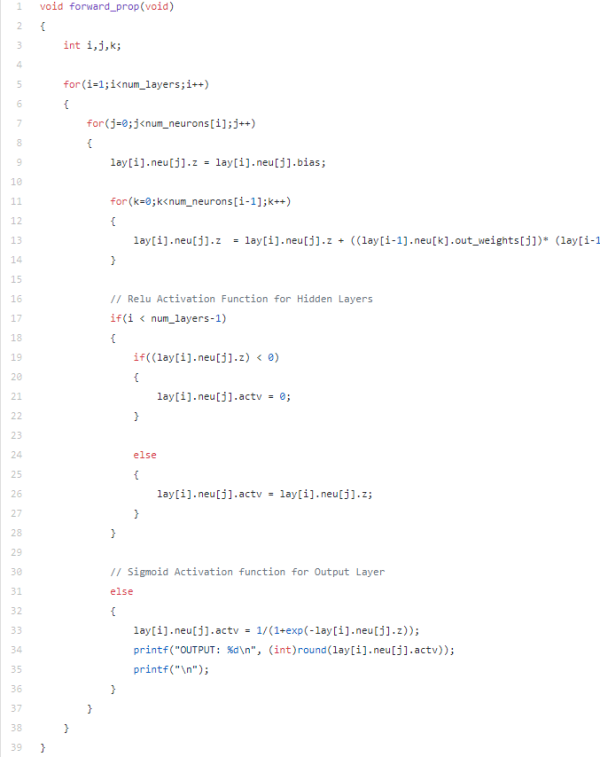
前向传递:
第i层第j个神经元的激活与(i−1)第(i−1)层神经元的激活关系为:

注意:σ是激活函数。这里输出层使用sigmoid激活函数,隐藏层使用Relu激活函数。
sigmoid函数:
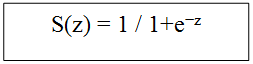
Relu函数:

让我们实现forward_prop()函数
反向传递:
反向传播的目标是反向传播错误并更新权值以最小化错误。这里,我们将使用均方误差函数来计算误差。

权重(dw)和偏差(dbias)的变化是使用成本函数C对网络中的权重和偏差的偏导数(∂C/ ∂weights和∂C/∂ bias)来计算的。
sigmoid函数的导数:
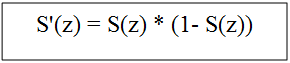
relu函数的导数:
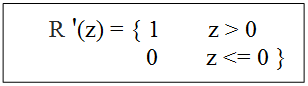
反向传播背后的四个基本方程:
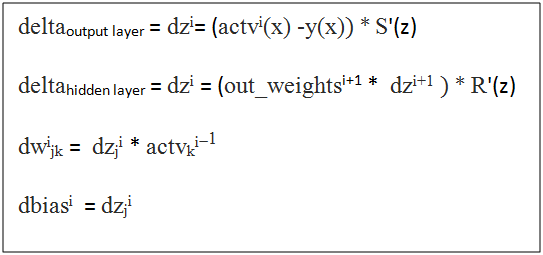
让我们在back_prop()函数中实现这些公式:

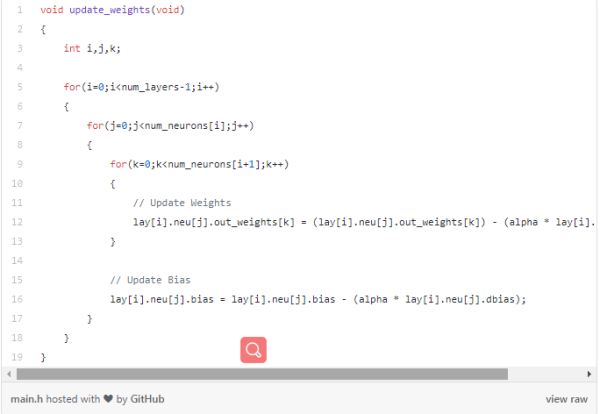
更新权重:
在每个epoch中,我们将使用update_weights()函数更新网络权值和偏差
测试框架:
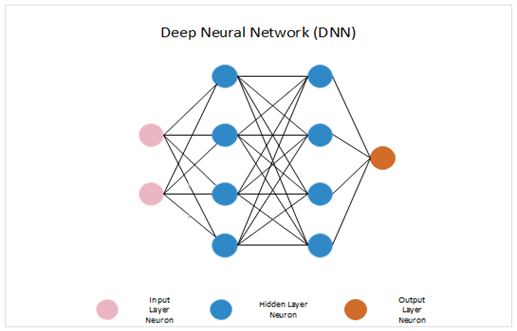
现在我们已经准备好了所有的部分,我们将验证框架的工作情况。因此,让我们创建一个4层的神经网络,输入层有2个神经元,第一隐含层有4个神经元,第二隐含层有4个神经元,输出层有1个神经元。另外,隐藏的和输出的神经元会有偏差。
现在,我们可以针对不同的逻辑门训练这个神经网络,比如XOR, OR等等。在下面的示例中,我们将实现XOR gate。
首先,提供所需的层数和每层神经元的数目:
Enter the number of Layers in Neural Network: 4 Enter number of neurons in layer[1]: 2 Enter number of neurons in layer[2]: 4 Enter number of neurons in layer[3]: 4 Enter number of neurons in layer[4]: 1 |
神经网络体系结构将根据给定的规范创建:
Created Layer: 1 Number of Neurons in Layer 1: 2 Neuron 1 in Layer 1 created Neuron 2 in Layer 1 created Created Layer: 2 Number of Neurons in Layer 2: 4 Neuron 1 in Layer 2 created Neuron 2 in Layer 2 created Neuron 3 in Layer 2 created Neuron 4 in Layer 2 created Created Layer: 3 Number of Neurons in Layer 3: 4 Neuron 1 in Layer 3 created Neuron 2 in Layer 3 created Neuron 3 in Layer 3 created Neuron 4 in Layer 3 created Created Layer: 4 Number of Neurons in Layer 4: 1 Neuron 1 in Layer 4 created |
所有的权值将在0和1之间随机初始化。
接下来,提供学习率和输入训练示例。下面是XOR逻辑门的真值表。

我们将以上4个输入作为神经网络的训练实例。
Enter the learning rate (Usually 0.15): 0.15 Enter the number of training examples: 4 Enter the Inputs for training example[0]: 0 0 Enter the Inputs for training example[1]: 0 1 Enter the Inputs for training example[2]: 1 0 Enter the Inputs for training example[3]: 1 1 |
输出标签:
Enter the Desired Outputs (Labels) for training example[0]: 0 |
Enter the Desired Outputs (Labels) for training example[1]: 1 Enter the Desired Outputs (Labels) for training example[2]: 1 Enter the Desired Outputs (Labels) for training example[3]: 0 |
我们的神经网络将在这4个训练实例上训练20000个epoch。现在,测试训练好的神经网络:
Enter input to test: 0 0 Output: 0 Enter input to test: 0 1 Output: 1 Enter input to test: 1 0 Output: 1 Enter input to test: 1 1 Output: 0 |
总结:
这是一个神经网络框架的基本实现,目的是了解神经网络的基本原理和反向传播算法。可以通过实现各种损失函数和提供保存/装载重量来增强代码。

