【51CTO.com快译】通常,诸如MySQL等时下流行的数据库管理系统(DBMS),都是由Web托管方(如云服务平台)提供的。这些数据库往往被设置成为默认、或通用的运行模式,且不一定适合用户系统的真实运行环境。为此,我们有必要对其进行适当的优化。

不过,一提到数据库优化,您也许会马上想到更高的查询效率、更高的整体性能等方面。其实,优化的好处远不至于此。在具体实现方法上,数据库管理人员往往也需要与Web开发团队通力合作,根据目标系统的实际情况,更改相应的配置策略和规则。本文将为Web开发人员列出七项数据库优化的常见技巧,以方便参考与实践。
1.删除未使用的表
通常,当您在应用中删除或停用了某个插件后,与之对应的数据库表并未随之自动消除。而且,它们会保留全量的用户信息、默认选项、以及其他数据。这些被遗留下来的数据集,不但是系统受到各种攻击的安全隐患,而且很可能会拖慢服务器与系统的整体性能。
如果您使用的是WordPress,那么可以通过安装一个名为“插件垃圾收集器”(Plugins Garbage Collector)的插件,来扫描并发现目标数据库中任何未在使用的数据表,以供您选择并删除它们。
当然,如果您更喜欢命令行操作的话,则可以使用如下图所示的UPDATE_TIME字符串,直接查找那些非活跃的数据表。

StackOverflow中的UPDATE_TIME字符串示例。来源:StackOverflow。
不过,某些插件在访问数据集后,可能无法更新目标数据表,因此您需要在删除数据库表之前,再三确认它们是否的确不再被使用、或没有被某处所调用到。而且作为一项预防性的办法,在做任何修改之前,您最好事先手动创建目标数据库的一个备份。当然,托管类型的云端服务通常都会提供针对服务器的自动化备份,您只需事先了解如何从中进行恢复便可。
2. 创建一个执行计划
执行计划(execution plan)的主要功能是:展示出在创建和执行某个查询时,所涉及到的各种检索数据的方法,其中包含:它查询了哪些表,先查询的是哪张表,后查询的又是哪张表,是否使用了索引,以及查询是否高效等信息。因此,典型的执行计划包括以下方面:
操作的类型
操作的排序
可使用的索引
通过统计来估算行数
通过结果来估算行数
下图是一个ApexSQL执行计划的图形化示例:
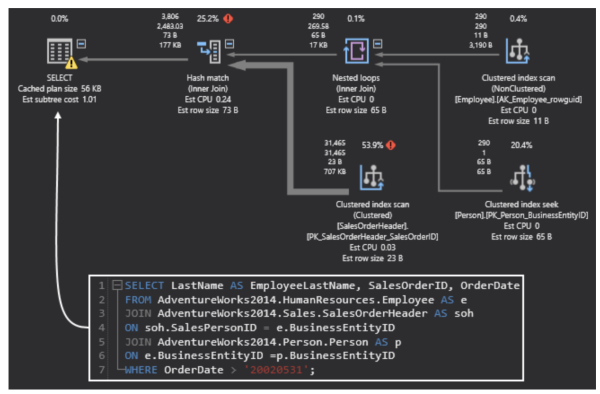
ApexSQL的执行计划示例。来源:ApexSQL。
可见,只有当您获得一个适当的执行计划,才能构建出实用的索引,进一步优化目标数据库,同时也为后续的优化打下基础。
3. 适当的索引
从概念上说,索引能够允许您更快地访问数据库,并加速查询。相反,如果您未能合理地使用索引,那么查询的处理过程就会变得缓慢。当然,过分地索引(over-indexing)数据库,是不会给系统带来任何好处的。
目前,Web开发人员经常使用两种类型的数据库索引:聚合(clustered index)和非聚合索引(non-clustered index)。

来源:DataSchool。
聚合方式使用主键来组织表中的数据。也就是说,在主键被定义后,索引将会被自动地创建出来。

定义主键。来源:DataSchool。
非聚合索引的主要目的是:通过创建能够更易于搜索的列,进而加快查询的效率。

创建索引。来源:DataSchool。
4. 避免通过索引访问临时表
根据MySQL的官方文档,创建临时表的一个条件是:对语句中包含的ORDER BY子句和不同的GROUP BY子句进行评估。然而,您可以通过使用“索引访问(index access)”,避免使用ORDER BY子句来创建临时表。使用这种索引的一个先决条件是:所有GROUP BY列都必须从相同的索引处引用不同的属性。而且,该索引必须按照顺序存储它们的键。
目前,我们可以在MySQL中使用两种类型的索引访问:松索引扫描(Loose Index Scan )和紧索引扫描(Tight Index Scan)。其中,松索引扫描只考虑索引键的一小部分,而并不能满足查询中的每一个WHERE条件。如果WHERE子句中包含了范围谓词,那么松索引扫描会首先在每一组中,查找满足范围条件的第一个键,然后再去读取最小数量的键。
当然,一些为数据表预定的条件可以直接使用松索引扫描。当松索引扫描适合某个查询时,EXPLAIN的输出会展示那些在额外列(Extra column)中,为group-by使用的索引。
下面的查询示例就是使用了松索引扫描访问:

查询列表示例:在表t1 (c1,c2,c3,c4)上的idx (c1,c2,c3)。来源:MySQL。
如果目标数据表的条件不支持使用松索引扫描,您可以选用紧索引扫描方式。当然,根据实际查询的需求,您也可以在此基础上,选用完整的、或一定范围的紧索引扫描。
此类索引访问的基础是:当一定范围条件的所有键被发现后,数据库将不会针对GROUP BY子句,生成一个临时的数据表,来满足该查询。
如下查询示例虽然不适合使用松索引扫描,但是我们可以采用紧索引扫描的方式:
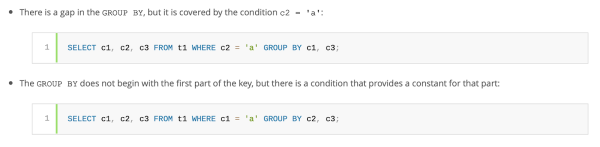
查询列表示例:在表t1 (c1,c2,c3,c4)上的idx (c1,c2,c3)。来源:MySQL。
5. 避免编码循环
一个SQL查询如果需要被运行多次,那么该系统不但低效,而且可能会导致不必要的性能问题。而对于大型数据集而言,此类问题会迅速积累,让系统最终不堪重负。目前,业界有多种不错的解决方案。从本质上说,这些方法都会要将查询移出循环,以确保只执行一次。
如下示例展示了,如何使用JOIN和GROUP BY从多个表中选择数据,并使数据库通过单个查询来执行计数。此方法对于多个查询(包括COUNT和MAX子句)来说,特别有效。
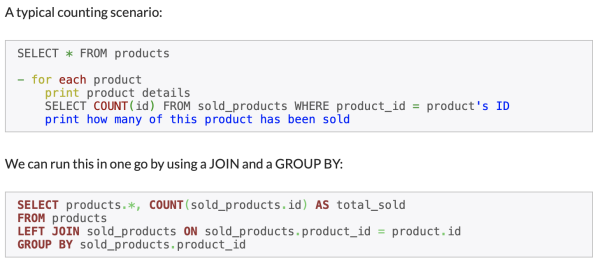
使用Join和Group By。来源:CodeUtopia。
当然,您还可以采用子选择,即:在SELECT子句中嵌套使用SELECT子句。由于此类查询的执行过程需要较少的资源,因此它对于合并查询非常实用。

子选择的示例。来源:CodeUtopia。
6. 摆脱相关子查询
从本质上说,相关子查询(Correlated subqueries)就是一种编码循环。也就是说,子查询通过逐行运行,直至满足父语句为止。当输出主要依赖于多部分的答案验证(multi-part answer validation)时,该处理方法十分有效。
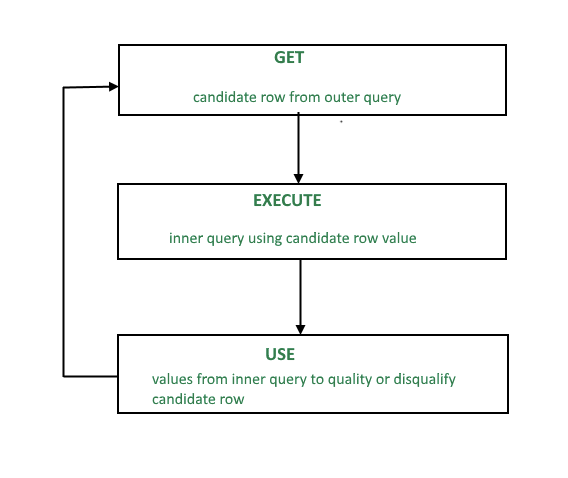
关联子查询流程图。来源:GeeksforGeeks。
您可以通过使用JOIN子句来避免相关子查询,进而提高查询的运行效率。实际上,该方法替换了WHERE,并消除了前端请求分别为每一行执行子查询的必要性。下图展示了该方法的工作过程:

Example of JOIN子句示例。来源:Ubitsoft。
7. 避免*式查询
每个查询的最终目标都是为了高效地检索到相关数据。但是,在创建查询时,如果采用的是SELECT *子句,则通常会导致检索各种并不相关的大量数据。如果目标数据集的体量较小,此类影响并不明显;而在处理大型数据集时,该影响则会非常巨大。因此,为了优化查询速度,并减少系统资源的消耗,我们应尽量减少查询的数据量。通常,您可以使用如下代码段中的LIMIT子句,来限制查询结果的输出。当然,如果确实需要检索并查询整个数据集,您仍然可以使用SELECT *的方式。

LIMIT子句的示例。来源:TechontheNet
小结
对Web开发人员来说,优化数据库并不简单,而且往往无法一蹴而就。不过,通过反复的试验与调试,相信您一定能够通过上述给出的七项技巧,提高目标数据库的性能和查询效率。当然,值得注意的是:在采取任何调优之前,请您做好数据库的备份工作,以便按需恢复到先前的状态。
原文标题:7 Database Optimization Hacks for Web Developers,作者:Kristina Tuvikene
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】

