恶意爬虫(bot)在企业网络的安全漏洞中起到至关重要的作用。这已经不是什么秘密。爬虫经常被恶意软件利用,在企业网络中传播。但检测和移除恶意爬虫却很复杂,这是由于操作环境中的许多日常进程,诸如软件更新,用的都是爬虫。
直到最近,一直都没有什么有效的方式让安全团队能区分出“好爬虫”和“坏爬虫”。开源源码和社区规则声称它们可以辨别爬虫,但收效甚微;误报太多。最后,安全分析专家会因为追踪分析“好爬虫”触发的无关紧要的安全警报而疲于奔命。
在 Cato,我们保护客户网络时也面临相同问题。为解决这个问题,我们发明了一种新方法,在我们的安全即服务中实施的多维度方法论,可以比单纯使用开源源码或社区规则多鉴别 72%以上的恶意事件。
最重要的是,你可以在自己的网络中采用类似策略。您的工具将会是任何网络工程师的交易手段:访问您的网络,像分接传感器一样捕获流量,保留足够的磁盘空间来存储一周的数据包。下面是如何分析这些捕获的数据包,以便更好地保护你的网络。
辨别恶意爬虫和流量的五项原则
在这篇文章中,我们将引入多维度的方法来分辨恶意爬虫。仅凭一条规律或许并不能让我们准确辨别出恶意爬虫,但综合多条规则并加以分析利用,将让这些爬虫无所遁形。方法并不难懂,是常见的逐步缩小狩猎范围,从人们日常产生的会话缩小到危害网络安全的那部分会话。
具体步骤如下:
区分人类与爬虫
区分浏览器与其他用户客户端
找出浏览器中的爬虫
分析 payload
确定目标威胁程度
下面,让我们一步一步地看:
根据对话频率区分人类与爬虫
爬虫的本质决定了它们会更倾向于与对象进行连续不断的会话。这是由于它们需要接收命令、发送 KeepAlive 信号,或者是渗出数据。区分爬虫与人类行为的第一步便是要揪出这些与目标机械性的重复对话。
我们需要找到那些与多个目标有规律且不间断对话的主机,过往经验告诉我们,收集一周左右的流量便足以判断这些客户端与目标间对话的本质。从统计学的角度来看,这些会话越是有规律,他们越有可能是由爬虫生成的(见图一)。
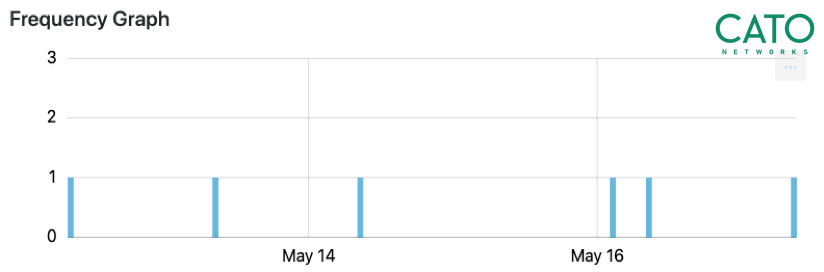
图中所示为今年五月中旬时收集的爬虫对话频率,对话产生的流量均匀分布,基本可以确定是爬虫流量。
区分浏览器与其他用户客户端
仅仅是分辨出爬虫寄居的主机并没有太大的用处,如我们之前提到的,大多数的主机都可能产生爬虫流量,因此我们还需要搞清楚网络中客户端的通信类型。一般来说,良性爬虫存在于浏览器之中,而恶意爬虫则相反。
操作系统中有很多种客户端和库都会产生流量,像是“Chrome”、“WinINet”,以及“Java Runtime Environment”都是客户端类型。乍一看这些客户端产生的流量可能大同小异,但通过一些方法,我们还是可以将他们区分开来的。
首先是应用层的头。因为大多数防火墙都会在设置里允许 HTTP 和 TLS 访问任意 IP,许多爬虫都会利用这些协议与他们的目标进行对话。我们只需要辨别客户端设置中的 HTTP 和 TLS 特征群组,便可轻易揪出在浏览器外运行的爬虫。
每一个 HTTP session 都有请求头来定义请求,以及服务器端的应对方法。这些头的序列、值,都是在生成 HTTP 请求的时候就设定好的(见图二)。类似的,TLS 的 session 属性,例如加密套件、扩展列表、ALPN(应用层协议协商)和椭圆曲线等,这些都是在初始的 TLS 消息中确定的。这条初始的消息又被称作“ClientHello”消息,也是未经过加密处理的。根据 HTTP 和 TLS 属性种类的不同进行聚类,可以在一定程度上将爬虫进行分类。
举例来说,如果我们捕获到了加密套件不相符的 TLS 流量,那么我们基本就可以确定这些流量是在浏览器外生成的了,这种非人为行为也就意味着是爬虫在制造流量。
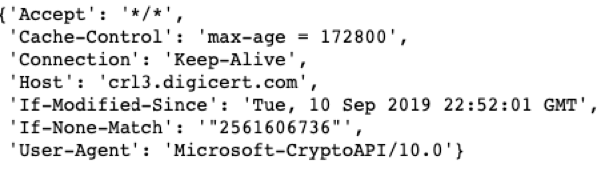
图中的例子是某条由 Windows 加密库生成的消息的头。通过查看与设置不相符的 seq、key 以及 value 可以辨别出爬虫的存在。
找出浏览器中的爬虫
判定恶意爬虫的另一种方法则是通过观察 HTTP 头中的一些特定信息:网络浏览器的 HTTP 头通常都是规范且清晰的。在正常的浏览 session 中,点击浏览器中的链接后生成的请求头中会包含 Referer,标明这个链接的来源。爬虫流量则相反,直接访问链接的请求头中 Referer 会为空,部分恶意访问甚至可以仿造 Referer。因此,在所有信息流中都长得一模一样的请求,大概率是爬虫流量。

图中显示的是在浏览 session 中包含 Referer 的头的示例
User-Agent(UA)这个字符段代表了程序在发起对话请求,一些诸如 fingerbank.org 这类的第三方服务会将 UA 里的程序版本号与已知版本相对应,并试图通过这条信息检测异常爬虫。
举例来说,最新版本浏览器会在 UA 字段使用“Mozilla/5.0”,低于这个版本的 Mozilla 或者缺失这条信息的请求基本意味着会是异常爬虫。有信誉的浏览器产生都流量不会不携带 UA 值。
Payload 分析
但是,我们并不希望异常爬虫的检查被局限在 HTTP 和 TLS 协议上,所有我们需要将更多的协议纳入考虑范围。以 IRC 协议为例,IRC 上的爬虫为僵尸网络贡献了不少有生力量。我们可以通过观察在已知端口上,使用固定未知协议的现有恶意软件样本,利用应用识别来标记恶意爬虫。
而流量的方向(入方向或出方向)在鉴别爬虫时同样有重要价值。直连到互联网的设备通常会被暴露在扫描操作中,因此,我们可以将这些爬虫看作是入站扫描器。另一方面,出站扫描行为则代表了该设备已被扫描器感染。感染的后果则是目标可能会被袭击,降低企业的 IP 地址信誉。
下图显示了在某一时间段内的流量图,这样的活动轨迹很可能是扫描机器人的杰作。这种类型的图可以通过计算流量/秒来进行数据分析。
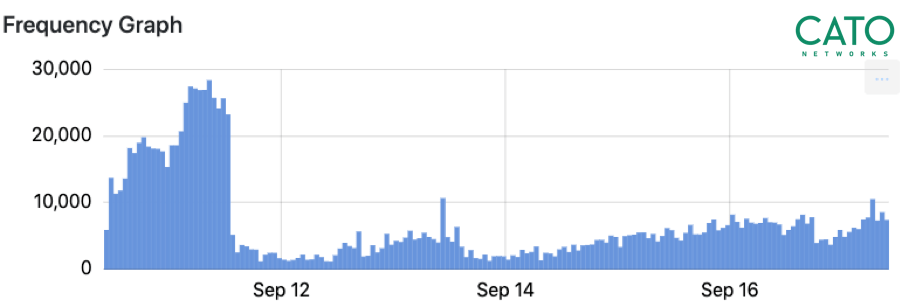
高频率出站扫描活动示例
目标分析:了解你的目的地是什么
在了解过从客户端-服务器的通信频率以及客户端类型判断恶意爬虫后,我们将引入另一判定维度:爬虫的目标或者说目的地。判定恶意爬虫的目标需要考虑两种因素:
一是目标的信誉
二是目标的受欢迎度
目标信誉可以从各种渠道中收集来的经验,判断一个域受到恶意攻击的可能性而计算得出。信誉的判定需要由第三方服务给出,或者是通过收集用户反馈的受到攻击的报告得出。
然而,通常情况下,仅仅是凭借着对目标信誉、URL 信誉的判断,并不足以标记恶意爬虫。每个月都要有数以百万计的新域名注册成功,在没有充足背景调查下的域名信誉判定系统并不能很好地给出该域名是否可信的判断,由此带来的高误判率也证明了这一点。
总而言之
将文中的方法总结后,可以发现,如果 session 满足以下条件,其为恶意爬虫的可能性很高:
由计算机生成而非人为
产生于浏览器之外,或是带有异常元数据的浏览器流量
与低人气目标沟通,目标如果被标记为恶意或未归类,那么将更可疑。正常或良性爬虫不应当与低人气目标对话。
练习:揭开仙女座恶意软件的网络面纱
通过综合这几种判定手段,我们可以找出网络中的各类危险因素。光说不练假把式,下面我们将通过“仙女座爬虫”这个经典例子来练习。“仙女座”是其他恶意软件的常用下载器,而通过文中介绍的四种手段进行数据分析,我们将揭露“仙女座”爬虫的真面目。
目标声誉
多家高信誉的网站均判断“disorderstatus.ru”为恶意域名,他们给这个域名打上的标签大多是:“已知感染源”,“僵尸网络”之类。然而,仅凭如此,我们并不能直接判定与该域名对话的主机感染了仙女座病毒:用户可能只是访问过这个网站而已。更何况,这个 URL 大概率只会被归类为“未知”或“非恶意”。
目标受欢迎度
访问某个目标的用户万中无一,这个“一”很不寻常,也为该贡献了“低人气”分数。
对话频率
在一周的数据收集中,我们注意到了客户端与目标在连续三天内均有流量产生。重复的对话意味着爬虫的存在。
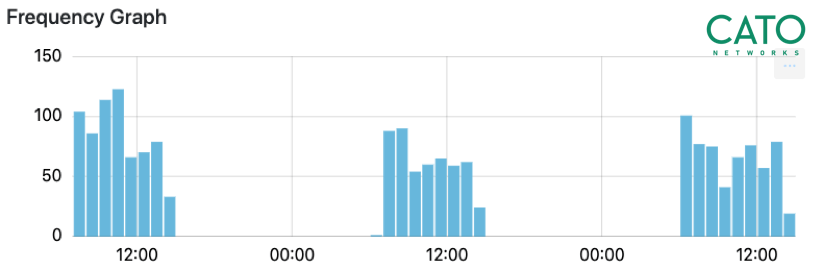
用户与 disorderstatus.ru 在三天内均有持续一小时的 client-target 对话流量产生
头分析
请求头中的“User-Agent”值为“Mozilla/4.0”,无效的服务器版本信息意味着该 UA 多半是爬虫制造。

图中是我们在与 disorderstatus.ru 对话时捕获的 HTTP 头。值得注意的是,在我们捕获的所有请求中,没有一个头包含“Referer”。另外,UA 值为“Mozilla/4.0”。这两点都指向了 Andromeda 会话。
总结
IP 网络中的爬虫检测正在逐渐成为检测恶意软件的基本组成部分之一,虽然不易,但我们相信,通过文中介绍的这五种手段的组合变种,爬虫检测将会更加有效。
原文链接:
https://www.catonetworks.com/blog/how-to-identify-malicious-bots-on-your-network-in-5-steps

