随着 Kubernetes 在企业中应用的越来越广泛和普及,越来越多的公司在生产环境中运维多个集群。本文主要讲述一些关于多集群 Kubernetes 的思考,包括为什么选择多集群,多集群的好处以及多集群的落地方案。
VMware2020 年 Kubernetes 使用报告中指出,在采用 kubernetes 组织中 20%的组织运行 40+数目的集群。
为什么企业需要多集群?
单集群 Kubernetes 承载能力有限
首先看看官方文档中关于单集群承载能力的描述:
在 v1.12,Kubernetes 支持最多具有 5000 个节点的集群。更具体地说,我们支持满足以下所有条件的配置:
不超过 5000 个节点
Pod 总数不超过 150000
总共不超过 300000 个容器
每个节点不超过 100 个 Pod
虽然现在 Kubernetes 已经发展到 v1.20,但是关于单集群承载能力一直没有变化。可见提高单集群负载能力并不是社区的发展方向。
如果我们的业务规模超过了 5000 台,那么企业不得不考虑多个集群。
混合云或是多云架构决定了需要多个集群
到目前,其实多云或是混合云的架构很普遍了。
比如企业是一个全球化的公司,提供 Global 服务。
或像新浪微博一样,自建数据中心 + 阿里云,阿里云用于服务弹性流量。
另外公有云并没有想象中的海量资源。比如公有云的头部客户搞大促需要很大数量机器的时候,都是需要提前和公有云申请,然后公有云提前准备的。
为了避免被单家供应商锁定,或是出于成本等考虑,企业选择了多云架构,也决定了我们需要多个集群。
不把鸡蛋放到一个篮子里
即使前面两条都未满足,那么我们是否要把所有的工作负载部署到一个集群哪?
如果集群控制面出现故障,那么所有的服务都会受到影响。
也许大家认为 Kubernetes 的控制面本身就是高可用的(三个 api-server),不会有整个控制层不可用的可能。
其实则不然,我们在生产环境中,已经处理很多次类似故障了。如果一个应用(一般指需要调用 api-server 接口)在大量地调用 api-server,会导致 api-server 接连挂掉,最终不可用。直到找到故障应用,并把故障应用删除。
所以在生产环境中,一是需要严格控制访问 api-server 的权限,二是需要做好测试,三是可以考虑业务应用和基础设施分开部署。其实单集群和多集群的选择和”选择一台超算 or 多台普通机器“的问题类似。后来分布式计算的发展说明大家选择了多个普通机器。
多集群的好处
多集群在以下三个方面,有着更好地表现:
可用性
隔离性
扩展性
多集群应用程序架构
实际上,可以通过两种模型来构建多集群应用程序架构
副本 :将应用程序复制到多个可用性区域或数据中心,每个集群都运行应用程序的完整副本。我们可以依靠 Smart DNS(在 GCP,有 Global 负载均衡器的概念) 将流量路由到距离用户最近的集群,以实现最小的网络延迟。如果我们一个集群发生故障,我们可以将流量路由到其他健康集群,实现故障转移。
按服务划分:按照业务相关程度,将应用部署在不同的集群。这种模型,提供了非常好的隔离性,但是服务划分却比较复杂。
社区多集群落地方案
实际上,社区一直在探索多集群 Kubernetes 的最佳实践,目前来看主要有以下两种。
以 Kubernetes 为中心
着力于支持和扩展用于多集群用例的核心 Kubernetes 原语,从而为多个集群提供集中式管理平面。Kubernetes 集群联邦项目采用了这种方法。
理解集群联邦的最好方法是可视化跨多个 Kubernetes 集群的元集群。想象一下一个逻辑控制平面,该逻辑控制平面编排多个 Kubernetes 主节点,类似于每个主节点如何控制其自身集群中的节点。
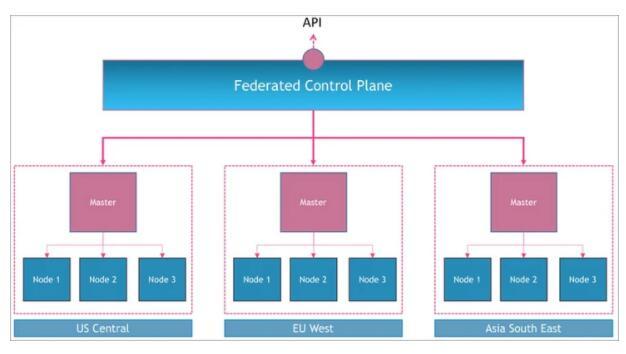
其实集群联邦本质上做了两件事情:
跨集群分发资源:通过抽象 Templates ,Placement,Overrides 三个概念,可以实现将资源(比如 Deployment)部署到不通的集群,并且实现多集群扩缩。
多集群服务发现:支持多集群 Service 和 Ingress。截止到目前,联邦项目尚处于 alpha 状态,当我们选择落地的时候,需要一定量的开发工作。
以网络为中心
以网络为中心的方法专注于在集群之间创建网络连接,以便集群内的应用程序可以相互通信。
Istio 的多集群支持,Linkerd 服务镜像和 Consul 的 Mesh 网关是通过 Service mesh 解决方案来实现网络连通。
而另外一种是 Cilium 关于多集群网络的方案。Cilium 本身是一种 CNI 网络,该方案少了服务治理的功能。
Cilium Cluster Mesh 解决方案通过隧道或直接路由,解决跨多个 Kubernetes 集群的 Pod IP 路由,而无需任何网关或代理。当然我们需要规划好每个集群的 POD CIDR。
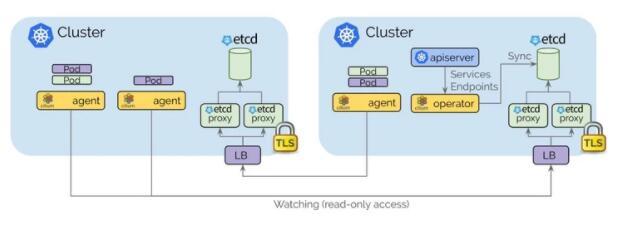
每个 Kubernetes 集群都维护自己的 etcd 集群,其中包含该集群的状态。来自多个集群的状态永远不会混入 etcd 中。
每个集群通过一组 etcd 代理公开其自己的 etcd。在其他集群中运行的 Cilium 代理连接到 etcd 代理以监视更改,并将多集群相关状态复制到自己的集群中。使用 etcd 代理可确保 etcd 观察程序的可伸缩性。访问受 TLS 证书保护。
从一个集群到另一个集群的访问始终是只读的。这样可以确保故障域保持不变,即一个集群中的故障永远不会传播到其他集群中。
通过简单的 Kubernetes secret 资源进行配置,该资源包含远程 etcd 代理的寻址信息以及集群名称和访问 etcd 代理所需的证书。
思考
上面我们讲到了两种落地多集群 Kubernetes 的方案,其实并不是非 A 即 B。
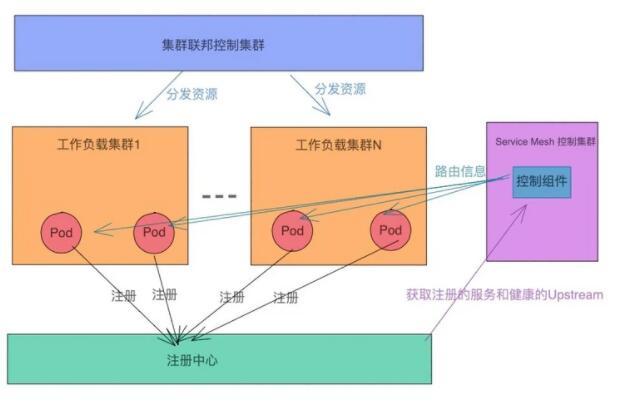
比如,当我们在落地大集群的过程中,很多公司只是用 Kubernetes 解决部署的问题。服务发现选择 consul,zk 等注册中心,配置文件管理使用配置中心,负载均衡也没有使用 kubernetes 中 Service。
此时结合两种方案是最佳实践。
集群联邦解决部署和发布的问题。Service mesh 解决多集群流量访问的问题。不过此时,工作负载集群中的 Pod,Service mesh 的控制面以及网关都需要对接外部的注册中心。具体架构如下: