今天这篇文章带你讲解下稍显神秘的mmap到底是怎么一回事。
简单的与麻烦的
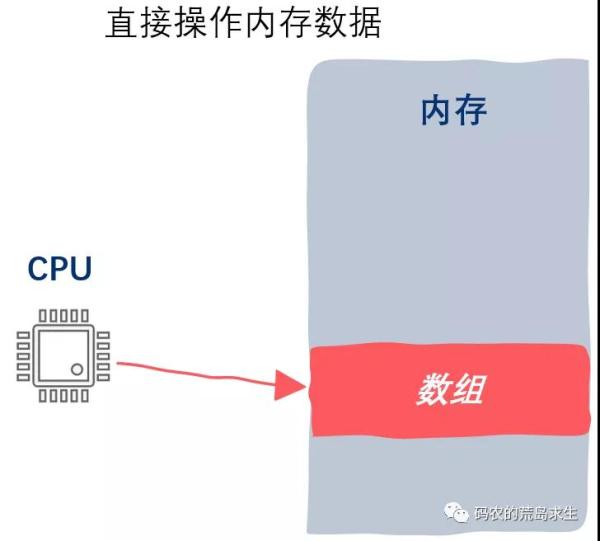
用代码读写内存对程序员来说是非常方便非常自然的,但用代码读写磁盘对程序员来说就不那么方便不那么自然了。
回想一下,你在代码中读写内存有多简单:
定义一个数组:
int a[100];
a[0] = 2;
看到了吧,这时你就在写内存,甚至你可能在写这段代码时下意识里都没有去想读内存这件事。
再想想你是怎样读磁盘文件的?
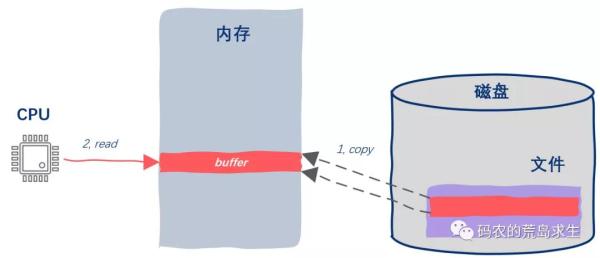
char buf[1024]; int fd = open("/filepath/abc.txt"); read(fd, buf, 1024); // 操作buf等等看到了吧,读写磁盘文件其实是一件很麻烦的事情,你需要open一个文件,意思是告诉操作系统“Hey,操作系统,我要开始读abc.txt这个文件了,把这个文件的所有信息准备好,然后给我一个代号”。这个代号就是所谓的文件描述符,拿到文件描述符后你才能继续接下来的读写操作。
为什么麻烦
现在你应该看到了,操作磁盘文件要比操作内存复杂很多,根本原因就在于寻址方式不同。
对内存来说我们可以直接按照字节粒度去寻址,但对磁盘上保存的文件来说则不是这样的,磁盘上保存的文件是按照块(block)的粒度来寻址的,因此你必须先把磁盘中的文件读取到内存中,然后再按照字节粒度来操作文件内容。
你可能会想既然直接操作内存很简单,那么我们有没有办法像读写内存那样去直接读写磁盘文件呢?
答案是肯定的。
要开脑洞了
对于像我们这样在用户态编程的程序员来说,内存在我们眼里就是一段连续的空间。啊哈,巧了,磁盘上保存的文件在程序员眼里也存放在一段连续的空间中(有的同学可能会说文件其实是在磁盘上离散存放的,请注意,我们在这里只从文件使用者的角度来讲)。

那么这两段空间有没有办法关联起来呢?
答案是肯定的,怎么关联呢?
答案就是。。。。。。你猜对了吗?答案是通过虚拟内存。
关于虚拟内存我们已经讲解过很多次了,虚拟内存就是假的地址空间,是进程看到的幻象,其目的是让每个进程都认为自己独占内存,关于虚拟内存完整的详细讲解请参考博主的深入理解操作系统,关注公众号码农的荒岛求生并回复操作系统即可。
既然进程看到地址空间是假的那么一切都好办了。
既然是假的,那么就有做手脚的操作空间,怎么做手脚呢?
从普通程序员眼里看文件不是保存在一段连续的磁盘空间上吗?我们可以直接把这段空间映射到进程的内存中,就像这样:
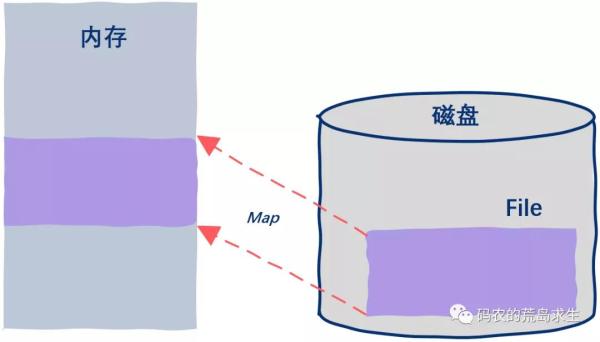
假设文件长度是100字节,我们把该文件映射到了进程的内存中,地址是从600 ~ 800,那么当你直接读写600 ~ 800这段内存时,实际上就是在直接操作磁盘文件。
这一切是怎么做到呢?
魔术师操作系统
原来这一切背后的功劳是操作系统。
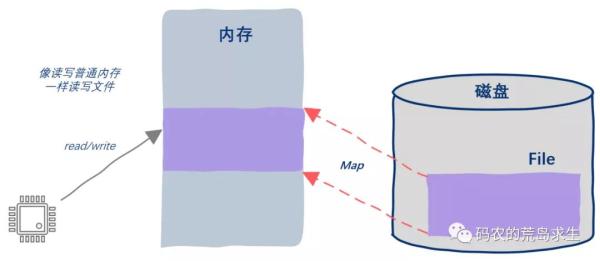
当我们首次读取600~800这段地址空间时,操作系统会检测的这一操作,因为此时这段内存中什么内容都还没有,此时操作系统自己读取磁盘文件填充到这段内存空间中,此后程序就可以像读内存一样直接读取磁盘内容了。
写操作也很简单,用户程序依然可以直接修改这块内存,此后操作系统会在背后将修改内容写回磁盘。
现在你应该看到了,其实采用mmap这种方法磁盘依然还是按照块的粒度来寻址的,只不过在操作系统的一番骚操作下对于用户态的程序来说“看起来”我们能像读写内存那样直接读写磁盘文件了,从按块粒度寻址到按照字节粒度寻址,这中间的差异就是操作系统来填补的。
我想你现在应该大体明白mmap是什么意思了。
接下来你肯定要问的问题就是,mmap有什么好处呢?我为什么要使用mmap?
内存copy与系统调用
我们常用的标准IO,也就是read/write其底层是涉及到系统调用的,同时当使用read/write读写文件内容时,需要将数据从内核态copy到用户态,修改完毕后再从用户态copy到内核态,显然,这些都是有开销的。
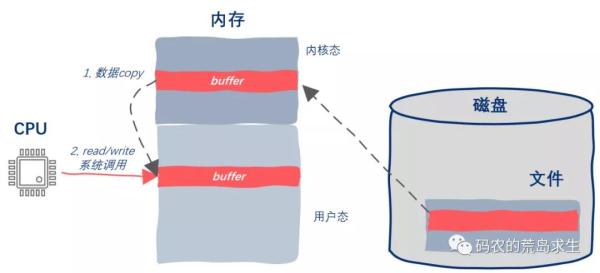
而mmap则无此问题,基于mmap读写磁盘文件不会招致系统调用以及额外的内存copy开销,但mmap也不是完美的,mmap也有自己的缺点。
其中一方面在于为了创建并维持地址空间与文件的映射关系,内核中需要有特定的数据结构来实现这一映射,这当然是有性能开销的,除此之外另一点就是缺页问题,page fault。
注意,缺页中断也是有开销的,而且不同的内核由于内部的实现机制不同,其系统调用、数据copy以及缺页处理的开销也不同,因此就性能上来说我们不能肯定的说mmap就比标准IO好。这要看标准IO中的系统调用、内存调用的开销与mmap方法中的缺页中断处理的开销哪个更小,开销小的一方将展现出更优异的性能。
还是那句话,谈到性能,单纯的理论分析就不是那么好用了,你需要基于真实的场景基于特定的操作系统以及硬件去测试才能有结论。
大文件处理
到目前为止我想大家对mmap最直观的理解就是可以像直接读写内存那样来操作磁盘文件,这是其中一个优点。
另一个优点在于mmap其实是和操作系统中的虚拟内存密切相关的,这就为mmap带来了一个很有趣的优势。
这个优势在于处理大文件场景,这里的大文件指的是文件的大小超过你的物理内存,在这种场景下如果你使用传统的read/write,那么你必须一块一块的把文件搬到内存,处理完文件的一小部分再处理下一部分。
这种需要在内存中开辟一块空间——也就是我们常说的buffer,的方案听上去就麻烦有没有,而且还需要操作系统把数据从内核态copy到用户态的buffer中。
但如果用mmap情况就不一样了,只要你的进程地址空间足够大,可以直接把这个大文件映射到你的进程地址空间中,即使该文件大小超过物理内存也可以,这就是虚拟内存的巧妙之处了,当物理内存的空闲空间所剩无几时虚拟内存会把你进程地址空间中不常用的部分扔出去,这样你就可以继续在有限的物理内存中处理超大文件了,这个过程对程序员是透明的,虚拟内存都给你处理好了。关于虚拟内存的透彻讲解请参考博主的深入理解操作系统,关注公众号码农的荒岛求生并回复操作系统即可。
注意,mmap与虚拟内存的结合在处理大文件时可以简化代码设计,但在性能上是否优于传统的read/write方法就不一定了,还是那句话关于mmap与传统IO在涉及到性能时你需要基于真实的应用场景测试。
使用mmap处理大文件要注意一点,如果你的系统是32位的话,进程的地址空间就只有4G,这其中还有一部分预留给操作系统,因此在32位系统下可能不足以在你的进程地址空间中找到一块连续的空间来映射该文件,在64位系统下则无需担心地址空间不足的问题,这一点要注意。
节省内存
这可能是mmap最大的优势,以及最好的应用场景了。
假设有一个文件,很多进程的运行都依赖于此文件,而且还是有一个假设,那就是这些进程是以只读(read-only)的方式依赖于此文件。
你一定在想,这么神奇?很多进程以只读的方式依赖此文件?有这样的文件吗?
答案是肯定的,这就是动态链接库。
要想弄清楚动态链接库,我们就不得不从静态库说起。
假设有三个程序A、B、C依赖一个静态库,那么链接器在生成可执行程序A、B、C时会把该静态库copy到A、B、C中,就像这样:
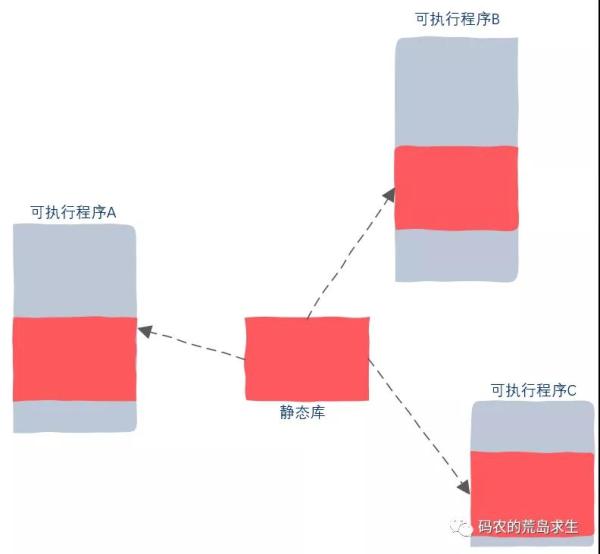
假设你本身要写的代码只有2MB大小,但却依赖了一个100MB的静态库,那么最终生成的可执行程序就是102MB,尽管你本身的代码只有2MB。
而且从图中我们可以看出,可执行程序A、B、C中都有一部分静态库的副本,这里面的内容是完全一样的,那么很显然,这些可执行程序放在磁盘上会浪费磁盘空间,加载到内存中运行时会浪费内存空间。
那么该怎么解决这个问题呢?
很简单,可执行程序A、B、C中为什么都要各自保存一份完全一样的数据呢?其实我们只需要在可执行程序A、B、C中保存一小点信息,这点信息里记录了依赖了哪个库,那么当可执行程序运行起来后再把相应的库加载到内存中:
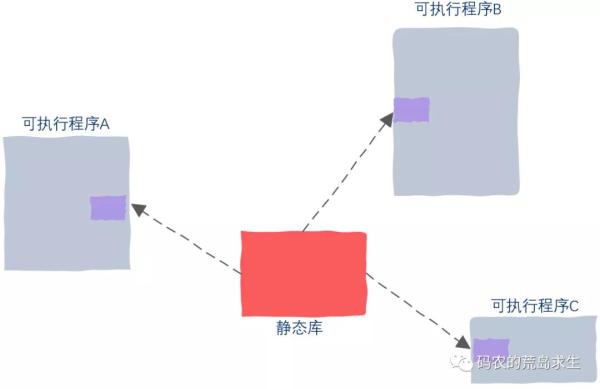
依然假设你本身要写的代码只有2MB大小,此时依赖了一个100MB的动态链接库,那么最终生成的可执行程序就是2MB,尽管你依赖了一个100MB的库。
而且从图中可以看出,此时可执行程序ABC中已经没有冗余信息了,这不但节省磁盘空间,而且节省内存空间,让有限的内存可以同时运行更多的进程,是不是很酷。
现在我们已经知道了动态库的妙用,但我们并没有说明动态库是怎么节省内存的,接下来mmap就该登场了。
你不是很多进程都依赖于同一个库嘛,那么我就用mmap把该库直接映射到各个进程的地址空间中,尽管每个进程都认为自己地址空间中加载了该库,但实际上该库在内存中只有一份。

mmap就这样很神奇和动态链接库联动起来了,关于链接器以及静态库动态库等更加详细的讲解你可以关注公众号码农的荒岛求生并回复链接器即可。
想用好mmap没那么容易
现在你应该大体了解mmap,想用好mmap你必须对虚拟内存有一个较为透彻的理解,并且能对你的应用场景有一个透彻的理解,在使用mmap之前问问自己是不是还有更好的办法,因此,对于新手来说并不推荐使用该机制。
总结
mmap在博主眼里是一种很独特的机制,这种机制最大的诱惑在于可以像读写内存样方便的操作磁盘文件,这简直就像魔法一样,因此在一些场景下可以简化代码设计。
但谈到mmap的与标准IO(read/write)的性能情况就比较复杂了,标准IO设计到系统调用以及用户态内核态的copy问题,而mmap则涉及到维持内存与磁盘文件的映射关系以及缺页处理的开销,单纯的从理论分析这二者半斤八两,如果你的应用场景对性能要求较高,那么你需要基于真实场景进行测试。

