
2021年是人工智能继续突飞猛进的一年。近日,Github上有人总结出了今年最有趣、最惊艳的38篇关于AI和机器学习论文,值得收藏。
1、Zero-Shot Text-to-Image Generation
https://arxiv.org/pdf/2102.12092.pdf

文本到图像的生成传统上侧重于为固定数据集的训练寻找更好的建模假设。本文描述了一种基于Transformer的简单方法来完成此任务,将文本和图像标记自回归建模为单个数据流。凭借足够的数据和规模,当以零样本方式进行评估时,我们的方法与以前的特定领域模型相比具有竞争力。
2、VOGUE: Try-On by StyleGAN Interpolation Optimization
https://vogue-try-on.github.io/static_files/resources/VOGUE-virtual-try-on.pdf

给定目标人物的图像和穿着服装的另一个人的图像,我们会自动生成给定服装中的目标人物。我们方法的核心是姿势条件 StyleGAN2 潜在空间插值,它无缝地结合了每个图像的兴趣区域,即体型、头发和肤色来自目标人物,而带有褶皱的服装 、材料属性和形状来自服装图像。
3、Taming Transformers for High-Resolution Image Synthesis
https://compvis.github.io/taming-transformers/

本文将 GAN 和卷积方法的效率与Transformer的表达能力相结合,为语义引导的高质量图像合成提供了一种强大且省时的方法。
4、Thinking Fast And Slow in AI
https://arxiv.org/abs/2010.06002

本文从人类能力中汲取灵感,提出了走向更通用和更值得信赖的人工智能(AGI)和人工智能研究社区的 10 个问题。
5、Automatic detection and quantification of floating marine macro-litter in aerial images
https://doi.org/10.1016/j.envpol.2021.116490

来自巴塞罗那大学的研究人员开发了一种基于深度学习的算法,能够从航拍图像中检测和量化漂浮的垃圾。他们还制作了一个面向网络的应用程序,允许用户在海面图像中识别这些垃圾。
6、ShaRF: Shape-conditioned Radiance Fields from a Single View
https://arxiv.org/abs/2102.08860

试想一下,如果只拍摄对象的照片并将其以 3D 格式插入到您正在创建的电影或视频游戏中,或者插入到 3D 场景中进行插图,那该有多酷。
7、Generative Adversarial Transformers
https://arxiv.org/pdf/2103.01209.pdf

本文利用了强大的 StyleGAN2 架构中Transformer的注意力机制,使其更加强大!
8、We Asked Artificial Intelligence to Create Dating Profiles. Would You Swipe Right?
https://studyonline.unsw.edu.au/blog/ai-generated-dating-profile

你会在 AI 的个人资料页面上仔细查看吗?你能区分真人与机器吗?这项研究揭示了在约会应用程序上使用AI,会发生什么事情。
9、Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
https://arxiv.org/abs/2103.14030v1

Transformers 会取代计算机视觉中的 CNN 吗?在不到 5 分钟的时间内,你就可以通过这篇关于 Swin Transformer 的新论文,了解如何将 Transformer 架构应用于计算机视觉任务。
10、IMAGE GANS MEET DIFFERENTIABLE RENDERING FOR INVERSE GRAPHICS AND INTERPRETABLE 3D NEURAL RENDERING
https://arxiv.org/pdf/2010.09125.pdf

本文提出了名为 GANverse3D 的模型,只需要一张图像,就可以创建可以自定义和动画的 3D 图像。
11、Deep nets: What have they ever done for vision?
https://arxiv.org/abs/1805.04025

本文将公开分享有关用于视觉应用的深度网络、它的成功之处,以及我们必须解决的局限性等一切内容。
12、Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image
https://arxiv.org/pdf/2012.09855.pdf
视图合成的下一步,就是永久视图生成,目标是创造出一张能够飞入其中的图片,还能在图像内的美景进行探索!
13、Portable, Self-Contained Neuroprosthetic Hand with Deep Learning-Based Finger Control
https://arxiv.org/abs/2103.13452

本文提出了一种由人工智能驱动的神经接口,截肢患者可以以栩栩如生的灵巧和直觉来控制神经假肢。
14、Total Relighting: Learning to Relight Portraits for Background Replacement
https://augmentedperception.github.io/total_relighting/total_relighting_paper.pdf

你有没有想过改变图片的背景,但让它看起来很逼真?这并不简单。你不能只是在家里拍一张自己的照片,然后换成海滩背景。图片看起来会很假,任何人都会马上看出「这是PS的」。本文提出的方法可能会完美解决这个问题。
15、LASR: Learning Articulated Shape Reconstruction from a Monocular Video
https://openaccess.thecvf.com/content/CVPR2021/papers/Yang_LASR_Learning_Articulated_Shape_Reconstruction_From_a_Monocular_Video_CVPR_2021_paper.pdf

本文提出一种方法,可以仅以短视频作为输入,生成人类或动物移动的 3D 模型。事实上,模型实际上明白,生成的目标是一个奇怪的形状,可以移动,但仍然需要和原视频保持附着,因为这仍然是「一个目标」,而不仅仅是多目标的集合。
16、Enhancing Photorealism Enhancement
http://vladlen.info/papers/EPE.pdf

本文中,英特尔的研究人员提出一个 AI模型,可实时应用于视频游戏,并让每一帧图像看起来更自然。
如果你认为这「只是另一个 GAN」,将视频游戏的图片作为输入,并按照自然世界的风格对其进行修改,其实并非如此。你可以在游戏图形上花费更少的精力,使其稳定和完整,然后使用此模型改进图形风格。
17、DefakeHop: A Light-Weight High-Performance Deepfake Detector
https://arxiv.org/abs/2103.06929

如何在 2021 年准确识别Deepfake假视频?这篇新论文可能会提供答案。可能是「再次使用人工智能」。以后,「眼见为实」可能很快就会变成「AI说真才是真」。
18、High-Resolution Photorealistic Image Translation in Real-Time: A Laplacian Pyramid Translation Network
https://arxiv.org/pdf/2105.09188.pdf

本文提出一种基于机器学习的新方法,实时将任何样式的图像翻译成指定风格的 4K 图像!
19、Barbershop: GAN-based Image Compositing using Segmentation Masks
https://arxiv.org/pdf/2106.01505.pdf

这篇文章本身并不是一项新技术,而是关于 GAN 的一个令人兴奋的新应用。这个 AI 可以改变你的发型,看看改变前后的对比吧。
20、TextStyleBrush: Transfer of text aesthetics from a single example
https://arxiv.org/abs/2106.08385

2021年,在异国旅行的你走进一家餐馆,面对看不懂的菜单,你甚至不需要打开谷歌翻译,只要简单地使用 Facebook AI 的这篇文章中的新模型,就可以翻译菜单图像中的每个文字。
21、Animating Pictures with Eulerian Motion Fields
https://arxiv.org/abs/2011.15128

本文中的AI模型拍摄一张照片,了解哪些粒子应该在移动,并将图片转换为无限循环的动画,同时完全保留图片的其余部分,创建出逼真的视频。
22、CVPR 2021最佳论文奖: GIRAFFE - Controllable Image Generation
http://www.cvlibs.net/publications/Niemeyer2021CVPR.pdf

本文使用修改后的 GAN 架构,可以在不影响背景或其他目标的情况下移动图像中的目标。
23、GitHub Copilot & Codex: Evaluating Large Language Models Trained on Code
https://arxiv.org/pdf/2107.03374.pdf

OpenAI 的这个新模型,可以从单词生成代码。
24、Apple: Recognizing People in Photos Through Private On-Device Machine Learning
https://machinelearning.apple.com/research/recognizing-people-photos
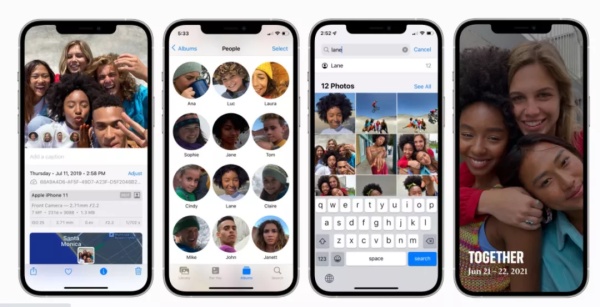
苹果使用在您的设备上多种基于机器学习的算法,让用户在 iOS 15 上实现准确规划和组织自己的图像和视频。
25、Image Synthesis and Editing with Stochastic Differential Equations
https://arxiv.org/pdf/2108.01073.pdf

是时候告别复杂的 GAN 和用于图像生成的Transformer架构了!来自斯坦福大学和卡内基梅隆大学的研究人员可以从任何基于用户的输入中生成新图像。即使是毫无艺术基础的人,现在也可以从草图中生成漂亮的图像。
26、Sketch Your Own GAN
https://arxiv.org/abs/2108.02774

通过按照草图生成图像,让每个人都可以更轻松地进行 GAN 训练!事实上,借助这种新方法,您可以根据最简单的知识类型来控制 GAN 的输出:手绘草图。
27、Tesla's Autopilot Explained
https://www.louisbouchard.ai/tesla-autopilot-explained-tesla-ai-day/

本文中,特斯拉人工智能总监安德烈·卡帕西等人展示了特斯拉的自动驾驶系统是如何通过他们的八个摄像头采集图像,实现道路上导航。
28、Styleclip: Text-driven manipulation of StyleGAN imagery
https://arxiv.org/abs/2103.17249

AI 可以生成图像,通过反复试验,研究人员可以按照特定的样式控制生成结果。现在,有了这个新模型,只使用文本就能做到这一点!
29、Time Lens: Event-based Video Frame Interpolation
http://rpg.ifi.uzh.ch/docs/CVPR21_Gehrig.pdf

TimeLens 模型可以理解视频帧之间的粒子运动,以人眼无法捕捉的速度重建视频。事实上,本文中的模型效果达到了目前智能手机都无法达到的效果。
30、Diverse Generation from a Single Video Made Possible
https://arxiv.org/abs/2109.08591

你有没有想过编辑视频?比如删除或添加某人、更改背景、更改分辨率以适应特定的纵横比,无需对原视频进行压缩或拉伸它。本文中的这项新研究。可以帮助你在单个视频中以高清格式完成所有这些工作。
31、Skillful Precipitation Nowcasting using Deep Generative Models of Radar
https://www.nature.com/articles/s41586-021-03854-z

DeepMind 刚刚发布了一个生成模型,能够在 89% 的情况下优于广泛使用的临近预报方法,其准确性和实用性通过了 50 多位气象学家的评估!这个模型专注于预测未来 2 小时内的降水,实现效果出奇地好。
32、The Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks
https://arxiv.org/pdf/2110.09958.pdf
你是否曾在收看视频或电视节目时完全听不见演员的声音,或者音乐太大声?嗯,这个问题可能永远不会再发生了。三菱和印第安纳大学刚刚发布了一个新模型和一个新数据集,用于识别并处理关于视频配乐声音的问题。
33、ADOP: Approximate Differentiable One-Pixel Point Rendering
https://arxiv.org/pdf/2110.06635.pdf
想象一下,从拍摄的一堆照片中生成一个 3D 模型或一段简单流畅的视频。现在,这个目标可以实现了。
34、(Style)CLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis
https://arxiv.org/abs/2111.03133
只需要拍一张你要复制样式的图片,再输入你要生成的文字,本文中的算法就会自动生成一张新的图片。
35、SwinIR: Image restoration using swin transformer
https://arxiv.org/abs/2108.10257
您是否曾经拍下过非常喜欢的图像,但现在只有一张小图了?如果能把它的清晰度提高四到八倍该有多好。本文中的方法可以将图像的分辨率提高4倍,使其看起来更加平滑。而且可以在几秒钟内自动完成,几乎适用于任何图像。
36、EditGAN: High-Precision Semantic Image Editing
https://arxiv.org/abs/2111.03186
本文中的图像编辑工具可以从草稿中控制任何特征,只会编辑你想要的内容,保持图像的其余部分不变。这是一款NVIDIA、MIT 和 UofT 提出的基于 GAN 的草图模型的 SOTA 图像编辑工具。
37、CityNeRF: Building NeRF at City Scale
https://arxiv.org/pdf/2112.05504.pdf
本文中的模型称为 CityNeRF,是从 NeRF 发展而来的。NeRF 是最早使用辐射场和机器学习从图像构建 3D 模型的模型之一。但效率不高,而且只适用于单一规模。本文中,CityNeRF可同时应用于卫星和地面图像,为任何视点生成各种 3D 模型比例。
38、ClipCap: CLIP Prefix for Image Captioning
https://arxiv.org/abs/2111.09734
CLIP 是一种将图像与文本作为指南链接的模型。一个非常相似的任务称为图像字幕,听起来很简单,但实际上也同样复杂。它体现了机器生成图像自然描述的能力。简单标记您在图像中看到的对象很容易,但理解单个二维图片则是另一回事,这个新模型做得非常好。

