随着用户在微信上积累的数据越来越多,提升微信底层搜索技术的需求也越来越迫切。在 2021 年,我们对 iOS 微信的全文搜索技术进行了一次全面升级,本文主要介绍本次技术升级的工作经验。
作者 | qiuwenchen
一、iOS 微信全文搜索技术的现状
全文搜索是使用倒排索引进行搜索的一种搜索方式。倒排索引也称为反向索引,是指对输入的内容中的每个Token建立一个索引,索引中保存了这个Token在内容中的具体位置。全文搜索技术主要应用在对大量文本内容进行搜索的场景。

微信终端涉及到大量文本搜索的业务场景主要包括联系人、聊天记录、收藏的搜索。这些搜索功能从 2014 年上线至今,已经多年没有更新底层搜索技术,聊天记录使用的全文搜索引擎还是 SQLite FTS3,而现在已经有 SQLite FTS5,收藏首页的搜索还是使用简单的Like语句去匹配文本,联系人搜索甚至用的是内存搜索(在内存中遍历所有联系人的所有属性进行匹配)。随着用户在微信上积累的数据越来越多,提升微信底层搜索技术的需求也越来越迫切。在 2021 年,我们对 iOS 微信的全文搜索技术进行了一次全面升级,本文主要介绍本次技术升级的工作经验。
二、全文搜索引擎的选型与优化
1. 搜索引擎选型
iOS 客户端可以使用的全文搜索引擎并不多,主要有 SQLite 三个版本的 FTS 组件、Lucene 的 C++实现版本 CLucene 和 C 语言桥接版本 Lucy。这里给出了这些引擎在事务能力、技术风险、搜索能力、读写性能等方面的比较。
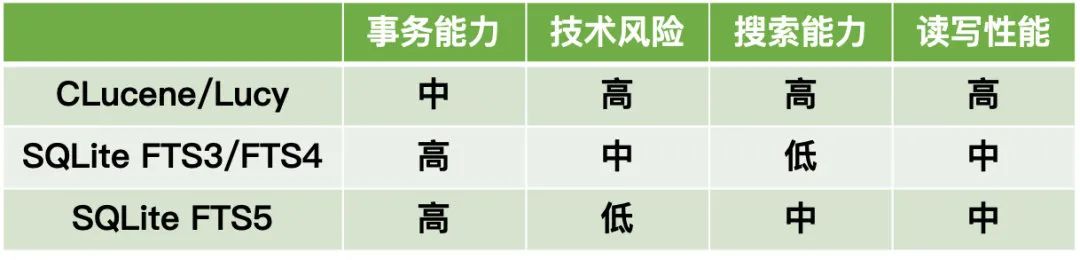
在事务能力方面,Lucene 没有提供完整的事务能力,因为 Lucene 使用了多文件的存储结构,它没有保证事务的原子性。SQLite 的 FTS 组件因为底层还是使用普通的表来实现的,可以完美继承 SQLite 的事务能力。
在技术风险方面,Lucene 主要应用于服务端,在客户端没有大规模应用的案例,而且 CLucene 和 Lucy 自 2013 年后官方都停止维护了,技术风险较高。SQLite 的 FTS3 和 FTS4 组件则是属于 SQLite 的旧版本引擎,官方维护不多了,而且这两个版本都是将一个词的索引存到一条记录中,极端情况下有超出 SQLite 单条记录最大长度限制的风险。SQLite 的 FTS5 组件作为最新版本引擎也已经推出超过六年了,在安卓微信上也已经全量应用,所以技术风险是最低的。
在搜索能力方面,Lucene 的发展历史比 SQLite 的 FTS 组件长很多,搜索能力相比也是最丰富的。特别是 Lucene 有丰富的搜索结果评分排序机制,但这个在微信客户端没有应用场景。因为我们的搜索结果要么是按照时间排序,要么是按照一些简单的自定义规则排序。在 SQLite 几个版本的引擎中,FTS5 的搜索语法更加完备严谨,提供了很多接口给用户自定义搜索函数,所以搜索能力也相对强一点。
在读写性能方面,下面是用不同引擎对 100 万条长度为 10 的随机生成中文语句生成 Optimize 状态的索引的性能数据,其中每个语句的汉字出现频率按照实际的汉字使用频率:
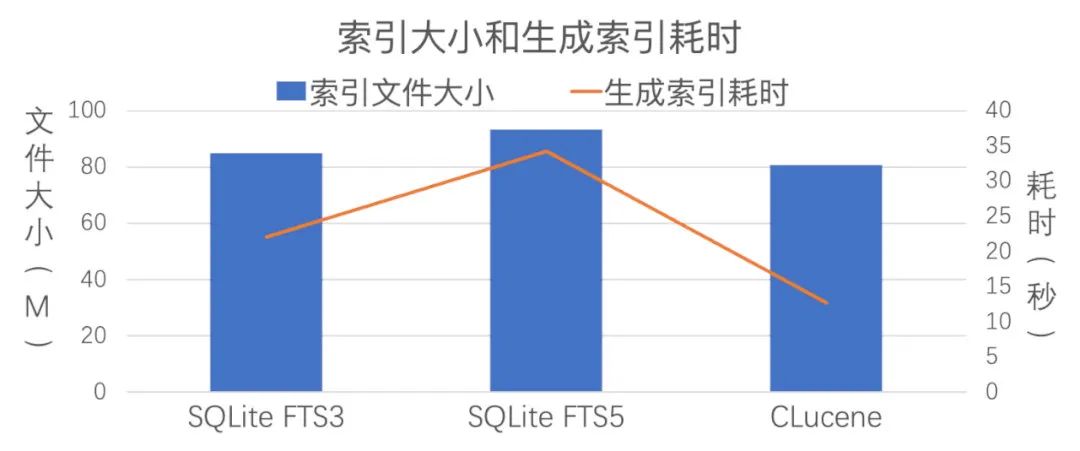
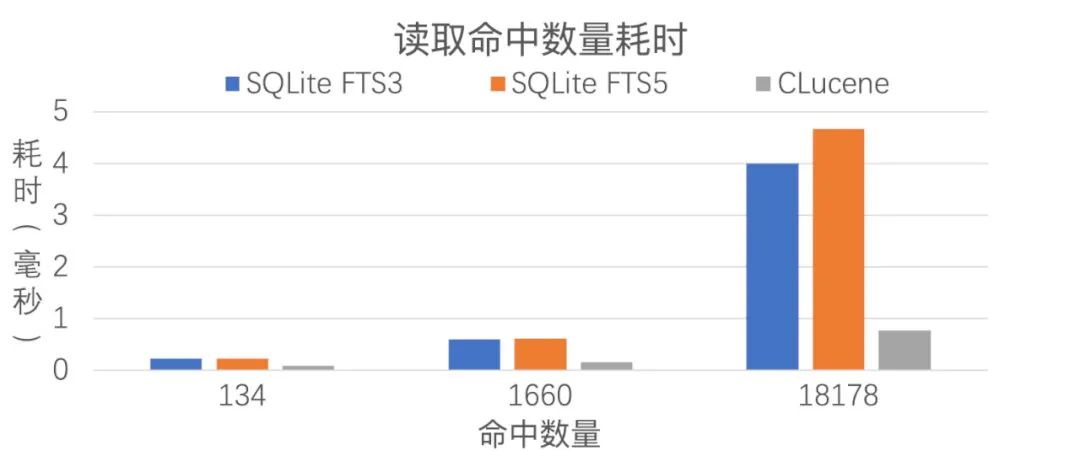
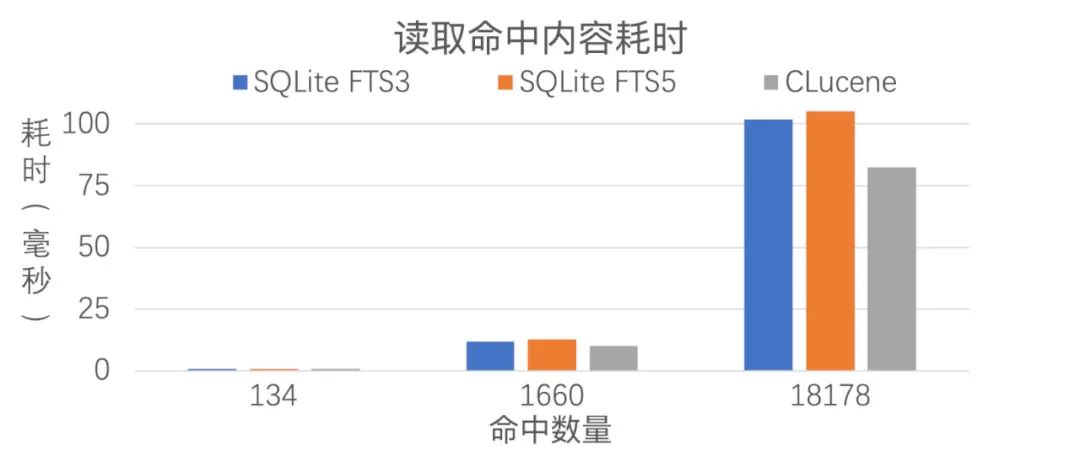
可以看到,Lucene 读取命中数量的性能比 SQLite 好很多,说明 Lucene 索引的文件格式很有优势,但是微信没有只读取命中数量的应用场景,Lucene 的其他性能数据跟 SQLite 的差距不明显。SQLite FTS3 和 FTS5 的大部分性能很接近,FTS5 索引的生成耗时比 FTS3 高一截,这个有优化方法。
综合考虑这些因素,我们选择 SQLite FTS5 作为 iOS 微信全文搜索的搜索引擎。
2. 实现 FTS5 的 Segment 自动 Merge 机制
SQLite FTS5 会把每个事务写入的内容保存成一个独立的 b 树,称为一个segment,segment中保存了本次写入内容中的每个词在本次内容中行号(rowid)、列号和字段中的每次出现的位置偏移,所以这个segment就是该内容的倒排索引。多次写入就会形成多个segment,查询时就需要分别查询这些segment再汇总结果,从而segment数量越多,查询速度越慢。
为了减少segment的数量,SQLite FTS5 引入了merge机制。新写入的segment的level为 0,merge操作可以把level为i的现有segment合并成一个level为i+1的新的segment。merge的示例如下:

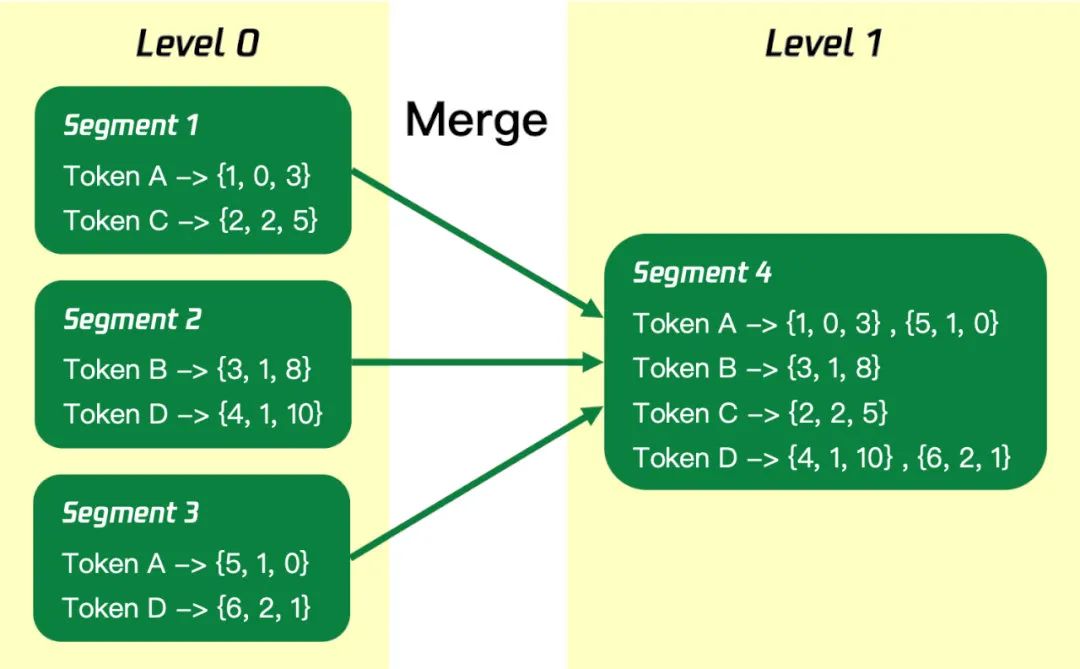
FTS5 默认的merge操作有两种:
某一个level的segment达到4时就开始在写入内容时自动执行一部分merge操作,称为一次automerge。每次automerge的写入量跟本次更新的写入量成正比,需要多次automerge才能完整合并成一个新segment。Automerge在完整生成一个新的segment前,需要多次裁剪旧的segment的已合并内容,引入多余的写入量。
本次写入后某一个level的segment数量达到 16 时,一次性合并这个level的segment,称为crisismerge。
FTS5 的默认merge操作都是在写入时同步执行的,会对业务逻辑造成性能影响,特别是crisismerge会偶然导致某一次写入操作特别久,这会让业务性能不可控。之前的测试中 FTS5 的建索引耗时较久,也主要因为 FTS5 的merge操作比其他两种引擎更加耗时。
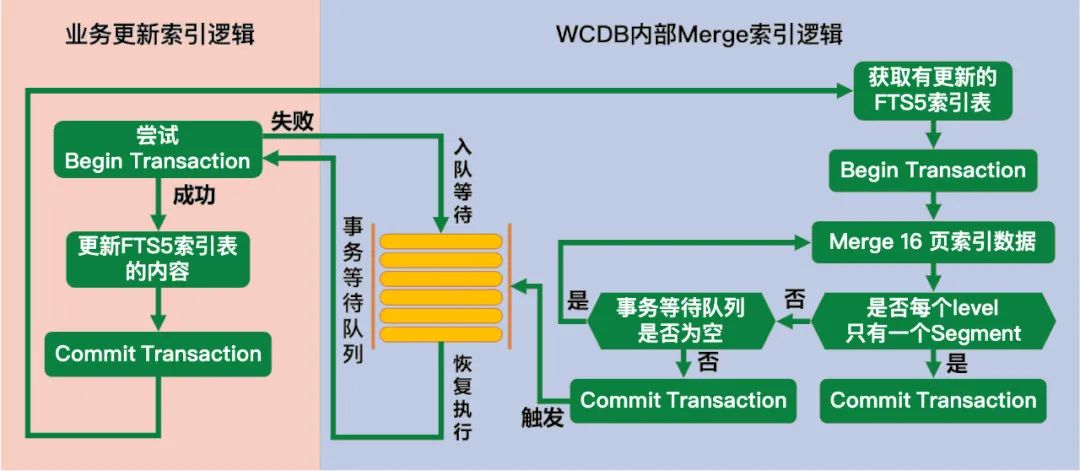
我们在 WCDB 中实现 FTS5 的segment自动merge机制,将这些merge操作集中到一个单独子线程执行,并且优化执行参数,具体如下:
监听有 FTS5 索引的数据库每个事务变更到的 FTS5 索引表,抛通知到子线程触发 WCDB 的自动merge操作。
Merge 线程检查所有 FTS5 索引表中segment数超过 1 的 level 执行一次merge。
Merge时每写入16页数据检查一次有没有其他线程的写入操作因为merge操作阻塞,如果有就立即commit,尽量减小merge对业务性能的影响。
自动merge逻辑执行的流程图如下:
限制每个level的segment数量为1,可以让 FTS5 的查询性能最接近optimize(所有segment合并成一个)之后的性能,而且引入的写入量是可接受的。假设业务每次写入量为M,写入了N次,那么在 merge 执行完整之后,数据库实际写入量为**MN(log2(N)+1)**。业务批量写入,提高M也可以减小总写入量。
性能方面,对一个包含 100w 条中文内容,每条长度 100 汉字的 fts5 的表查询三个词,optimize状态下耗时2.9ms,分别限制每个level的segment数量为2、3、4时的查询耗时分别为4.7ms、8.9ms、15ms。100w 条内容每次写入 100 条的情况下,按照 WCDB 的方案执行merge的耗时在10s内。
使用自动Merge机制,可以在不影响索引更新性能的情况下,将 FTS5 索引保持在最接近Optimize的状态,提高了搜索速度。
3. 分词器优化
分词器性能优化
分词器是全文搜索的关键模块,它实现将输入内容拆分成多个Token并提供这些Token的位置,搜索引擎再对这些Token建立索引。SQLite 的 FTS 组件支持自定义分词器,可以按照业务需求实现自己的分词器。
分词器的分词方法可以分为按字分词和按词分词。前者只是简单对输入内容逐字建立索引,后者则需要理解输入内容的语义,对有具体含义的词组建立索引。相比于按字分词,按词分词的优势是既可以减少建索引的Token数量,也可以减少搜索时匹配的Token数量,劣势是需要理解语义,而且用户输入的词不完整时也会有搜不到的问题。
为了简化客户端逻辑和避免用户漏输内容时搜不到的问题,iOS 微信之前的 FTS3 分词器OneOrBinaryTokenizer是采用了一种巧妙的按字分词算法,除了对输入内容逐字建索引,还会对内容中每两个连续的字建索引,对于搜索内容则是按照每两个字进行分词。下面是一个用“北京欢迎你”去搜索相同内容的分词例子:
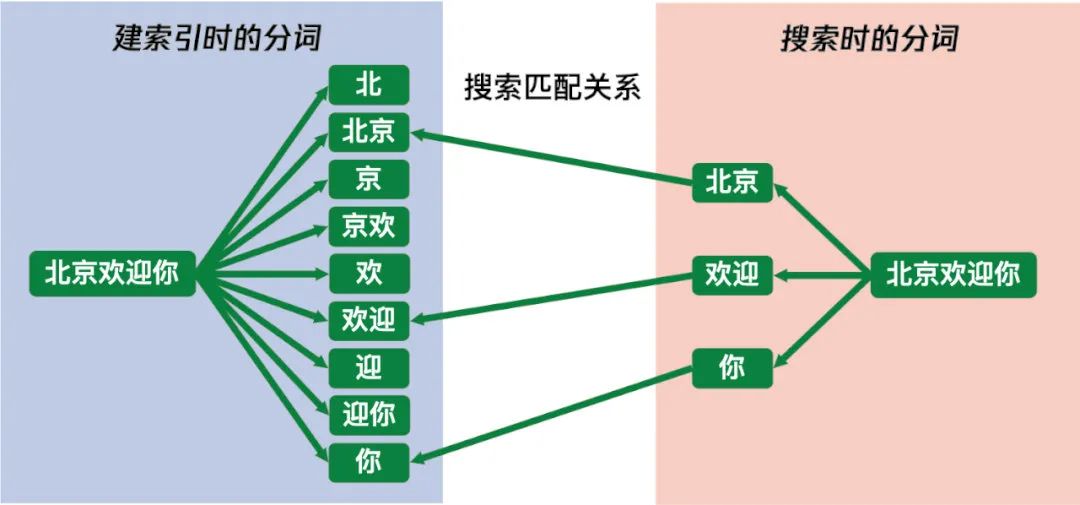
相比于简单的按字分词,这种分词方式的优势是可以将搜索时匹配的Token数量接近降低一半,提高搜索速度,而且在一定程度上可以提升搜索精度,比如搜索“欢迎你北京”就匹配不到“北京欢迎你”;这种分词方式的劣势就是保存的索引内容很多,基本输入内容的每个字都在索引中保存了三次,是一种用空间换时间的做法。
因为OneOrBinaryTokenizer用接近三倍的索引内容增长才换取不到两倍的搜索性能提升,不是很划算,所以我们在 FTS5 上重新开发了一种新的分词器VerbatimTokenizer,这个分词器只采用基本的按字分词,不保存冗余索引内容。同时在搜索时,每两个字用引号引起来组成一个Phrase,按照 FTS5 的搜索语法,搜索时Phrase中的字要按顺序相邻出现的内容才会命中,实现了跟OneOrBinaryTokenizer一样的搜索精度。VerbatimTokenizer的分词规则示意图如下:
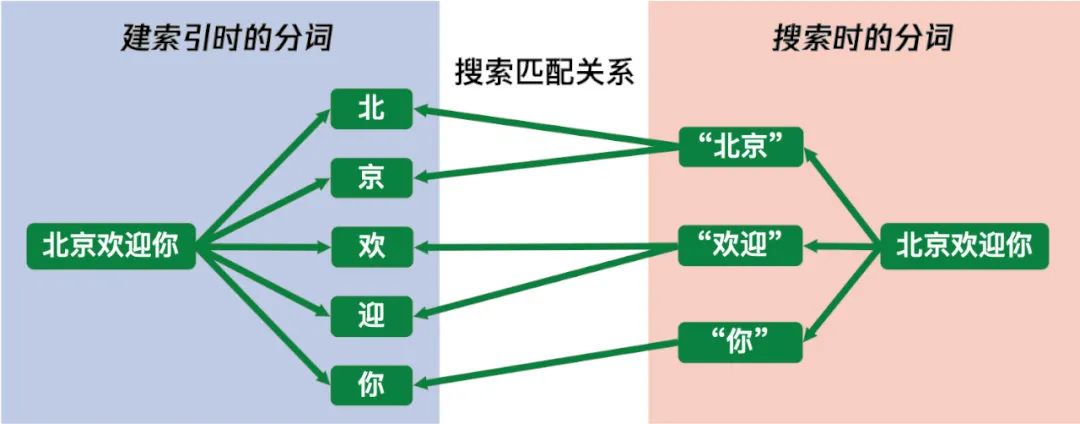
分词器能力扩展
VerbatimTokenizer 还根据微信实际的业务需求实现了五种扩展能力来提高搜索的容错能力:
支持在分词时将繁体字转换成简体字。这样用户可以用繁体字搜到简体字内容,用简体字也能搜到繁体字内容,避免了因为汉字的简体和繁体字形相近导致用户输错的问题。
支持 Unicode 归一化。Unicode 支持相同字形的字符用不同的编码来表示,比如编码为\ue9的é和编码为\u65\u301的é有相同的字形,这会导致用户用看上去一样的内容去搜索结果搜不到的问题。Unicode 归一化就是把字形相同的字符用同一个编码表示。
支持过滤符号。大部分情况下,我们不需要支持对符号建索引,符号的重复量大而且用户一般也不会用符号去搜索内容,但是联系人搜索这个业务场景需要支持符号搜索,因为用户的昵称里面经常出现颜文字,符号的使用量不低。
支持用Porter Stemming算法对英文单词取词干。取词干的好处是允许用户搜索内容的单复数和时态跟命中内容不一致,让用户更容易搜到内容。但是取词干也有弊端,比如用户要搜索的内容是“happyday”,输入“happy”作为前缀去搜索却会搜不到,因为“happyday”取词干变成“happydai”,“happy”取词干变成“happi”,后者就不能成为前者的前缀。这种 badcase 在内容为多个英文单词拼接一起时容易出现,联系人昵称的拼接英文很常见,所以在联系人的索引中没有取词干,在其他业务场景中都用上了。
支持将字母全部转成小写。这样用户可以用小写搜到大写,反之亦然。
这些扩展能力都是对建索引内容和搜索内容中的每个字做变换,这个变换其实也可以在业务层做,其中的 Unicode 归一化和简繁转换以前就是在业务层实现的。但是这样做有两个弊端,一个是业务层每做一个转换都需要对内容做一次遍历,引入冗余计算量,另一个是写入到索引中的内容是转变后的内容,那么搜索出来的结果也是转变后的,会和原文不一致,业务层做内容判断的时候容易出错。鉴于这两个原因,VerbatimTokenizer将这些转变能力都集中到了分词器中实现。
4. 索引内容支持多级分隔符
SQLite 的 FTS 索引表不支持在建表后再添加新列,但是随着业务的发展,业务数据支持搜索的属性会变多,如何解决新属性的搜索问题呢?特别是在联系人搜索这个业务场景,一个联系人支持搜索的字段非常多。一个直接的想法是将新属性和旧属性用分隔符拼接到一起建索引。但这样会引入新的问题,FTS5 是以整个字段的内容作为整体去匹配的,如果用户搜索匹配的Token在不同的属性,那这条数据也会命中,这个结果显然不是用户想要的,搜索结果的精确度就降低了。
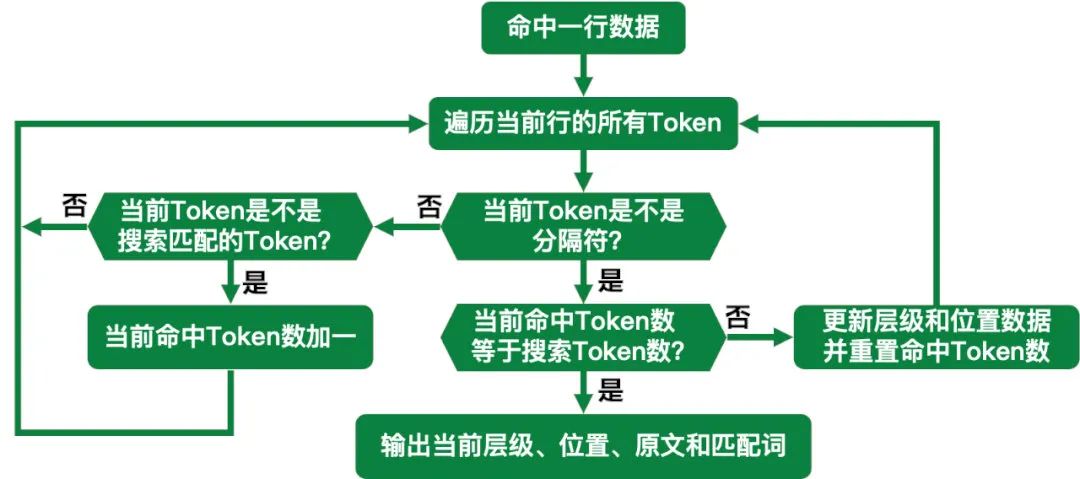
我们需要搜索匹配的Token中间不存在分隔符,那这样可以确保匹配的Token都在一个属性内。同时,为了支持业务灵活扩展,还需要支持多级分隔符,而且搜索结果中还要支持获取匹配结果的层级、位置以及该段内容的原文和匹配词。这个能力 FTS5 还不没有,而 FTS5 的自定义辅助函数支持在搜索时获取到所有命中结果中每个命中Token的位置,利用这个信息可以推断出这些Token中间有没有分隔符,以及这些Token所在的层级,所以我们开发了SubstringMatchInfo这个新的 FTS5 搜索辅助函数来实现这个能力。这个函数的大致执行流程如下:

三、全文搜索应用逻辑优化
1. 数据库表格式优化
1.1非文本搜索内容的保存方式
在实际应用中,我们除了要在数据库中保存需要搜索的文本的 FTS 索引,还需要额外保存这个文本对应的业务数据的id、用于结果排序的的属性(常见的是业务数据的创建时间)以及其他需要直接跟随搜索结果读出的内容,这些都是不参与文本搜索的内容。根据非文本搜索内容的不同存储位置,我们可以将 FTS 索引表的表格式分成两种:
第一种方式是将非文本搜索内容存储在额外的普通表中,这个表保存 FTS 索引的Rowid和非文本搜索内容的映射关系,而 FTS 索引表的每一行只保存可搜索的文本内容,这个表格式类似于这样:

这种表格式的优势是 FTS 索引表的内容很简单,不熟悉 FTS 索引表配置的同学不容易出错,而且普通表的可扩展性好,支持添加新列;劣势则是搜索时需要先用 FTS 索引的Rowid读取到普通表的Rowid,这样才能读取到普通表的其他内容,搜索速度慢一点,而且搜索时需要联表查询,搜索 SQL 语句稍微复杂一点。
第二种方式是将非文本搜索内容直接和可搜索文本内容一起存储在 FTS 索引表中,表格式类似于这样:

这种方式的优劣势跟前一种方式恰好相反,优势是搜索速度快而且搜索方式简单,劣势是扩展性差且需要更细致的配置。
因为 iOS 微信以前是使用第二种表格式,而且微信的搜索业务已经稳定不会有大变化,我们现在更加追求搜索速度,所以我们还是继续使用第二种表格式来存储全文搜索的数据。
1.2 避免冗余索引内容
FTS 索引表默认对表中的每一列的内容都建倒排索引,即便是数字内容也会按照文本来处理,这样会导致我们保存在 FTS 索引表中的非文本搜索内容也建了索引,进而增大索引文件的大小、索引更新的耗时和搜索的耗时,这显然不是我们想要的。
FTS5 支持给索引表中的列添加UNINDEXED约束,这样 FTS5 就不会对这个列建索引了,所以给可搜索文本内容之外的所有列添加这个约束就可以避免冗余索引。
1.3 降低索引内容的大小
前面提到,倒排索引主要保存文本中每个Token对应的行号(rowid)、列号和字段中的每次出现的位置偏移,其中的行号是 SQLite 自动分配的,位置偏移是根据业务的实际内容,这两个我们都决定不了,但是列号是可以调整的。
在 FTS5 索引中,一个Token在一行中的索引内容的格式是这样的:


从中可以看出,如果我们把可搜索文本内容设置在第一列的话(多个可搜索文本列的话,把内容多的列放到第一列),就可以少保存列分割符0x01和列号,这样可以明显降低索引文件大小。
所以我们最终的表格式是这样:


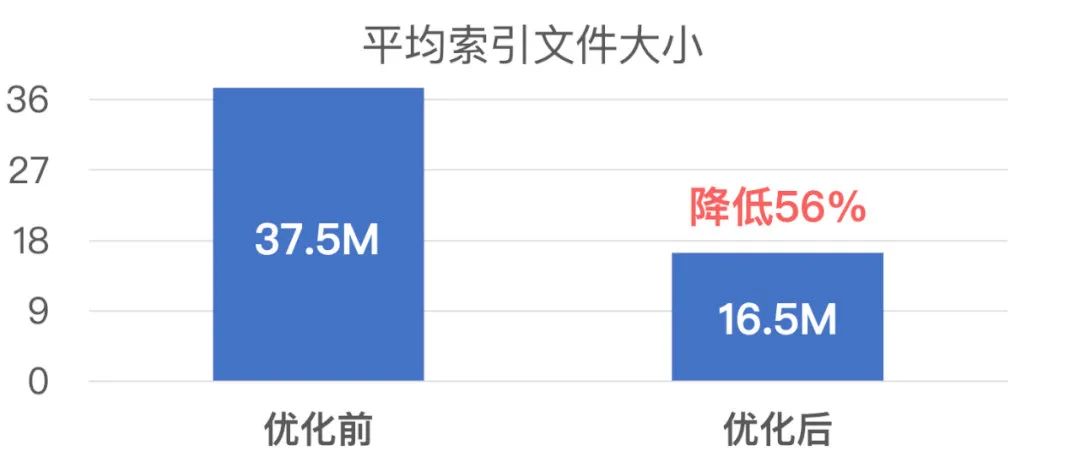
1.4 索引文件大小优化数据
下面是 iOS 微信优化前后的平均每个用户的索引文件大小对比:

2. 索引更新逻辑优化
为了将全文搜索逻辑和业务逻辑解耦,iOS 微信的 FTS 索引是不保存在各个业务的数据库中的,而是集中保存到一个专用的全文搜索数据库,各个业务的数据有更新之后再异步通知全文搜索模块更新索引。整体流程如下:
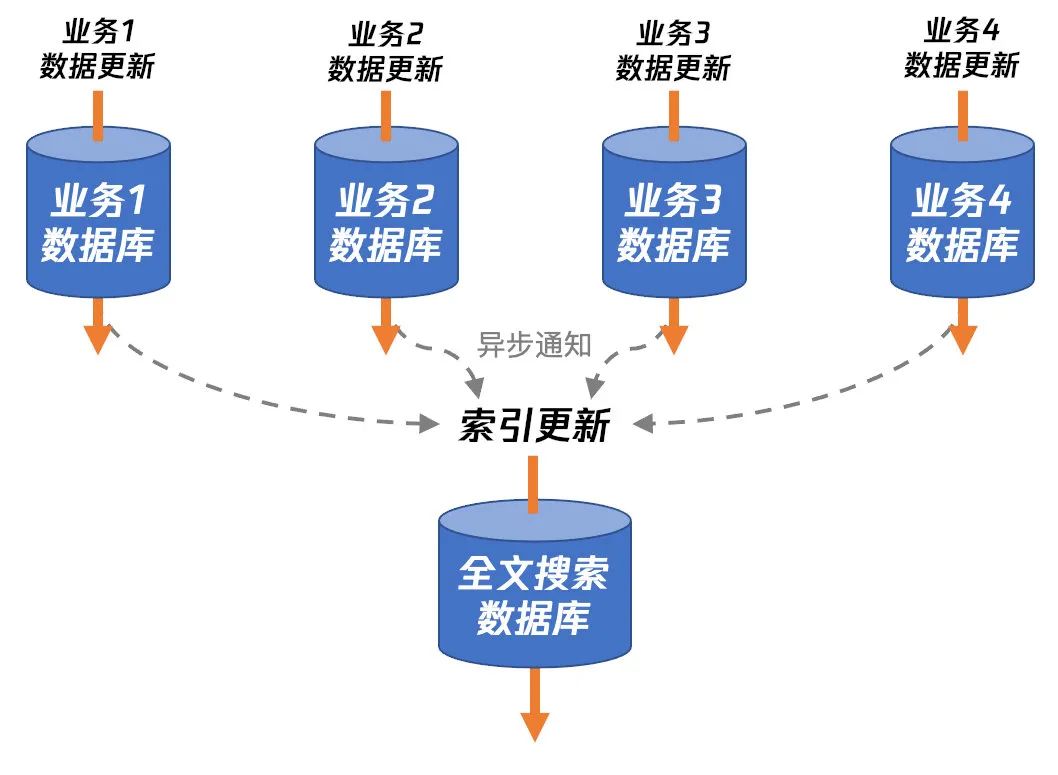
这样做既可以避免索引更新拖慢业务数据更新的速度,也能避免索引数据更新出错甚至索引数据损坏对业务造成影响,让全文搜索功能模块能够充分独立。
2.1 保证索引和数据的一致
业务数据和索引数据分离且异步同步的好处很多,但实现起来也很难,最难的问题是如何保证业务数据和索引数据的一致,也即要保证业务数据和索引数据要逐条对应,不多不少。曾经 iOS 微信在这里踩了很多坑,打了很多补丁都不能完整解决这个问题,我们需要一个更加体系化的方法来解决这个问题。
为了简化问题,我们可以把一致性问题可以拆成两个方面分别处理,一个是保证所有业务数据都有索引,这个用户的搜索结果就不会有缺漏;第二个是保证所有索引都对应一个有效的业务数据,这样用户就不会搜到无效的结果。
要保证所有业务数据都有索引,首先要找到或者构造一种一直增长的数据来描述业务数据更新的进度,这个进度数据的更新和业务数据的更新能保证原子性,而且根据这个进度的区间能拿出业务数据更新的内容,这样我们就可以依赖这个进度来更新索引。在微信的业务中,不同业务的进度数据不同,聊天记录是使用消息的rowid,收藏是使用收藏跟后台同步的updateSequence,而联系人找不到这种一直增长的进度数据,我们是通过在联系人数据库中标记有新增或有更新的联系人的微信号来作为索引更新进度。进度数据的使用方法如下:

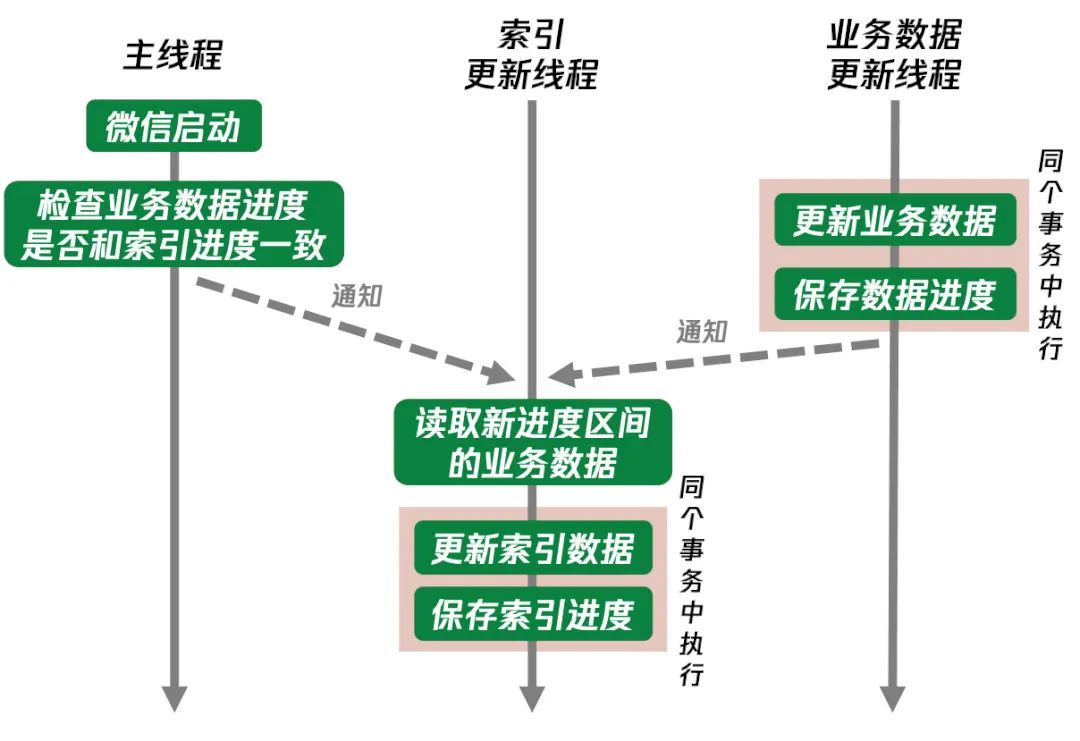
无论业务数据是否保存成功、更新通知是否到达全文搜索模块、索引数据是否保存成功,这套索引更新逻辑都能保证保存成功的业务数据都能成功建到索引。这其中的一个关键点是数据和进度要在同个事务中一起更新,而且要保存在同个数据库中,这样才能保证数据和进度的更新的原子性(WCDB 创建的数据库因为使用WAL模式而无法保证不同数据库的事务的原子性)。还有一个操作图中没有画出,具体是微信启动时如果检查到业务进度小于索引进度,这种一般意味着业务数据损坏后被重置了,这种情况下要删掉索引并重置索引进度。
对于每个索引都对应有效的业务数据,这就要求业务数据删除之后索引也要必须删掉。现在业务数据的删除和索引的删除是异步的,会出现业务数据删掉之后索引没删除的情况。这种情况会导致两个问题,一个是冗余索引会导致搜索速度变慢,但这个问题出现概率很小,这个影响可以忽略不计;第二个问题是会导致用户搜到无效数据,这个是要避免的。因为要完全删掉所有无效索引成本比较高,所以我们采用了惰性检查的方法来解决这个问题,具体做法是搜索结果要显示给用户时,才检查这个数据是否有效,无效的话不显示这个搜索结果并异步删除对应的索引。因为用户一屏能看到的数据很少,所以检查逻辑带来的性能消耗也可以忽略不计。而且这个检查操作实际上也不算是额外加的逻辑,为了搜索结果展示内容的灵活性,我们也要在展示搜索结果时读出业务数据,这样也就顺带做了数据有效性的检查。
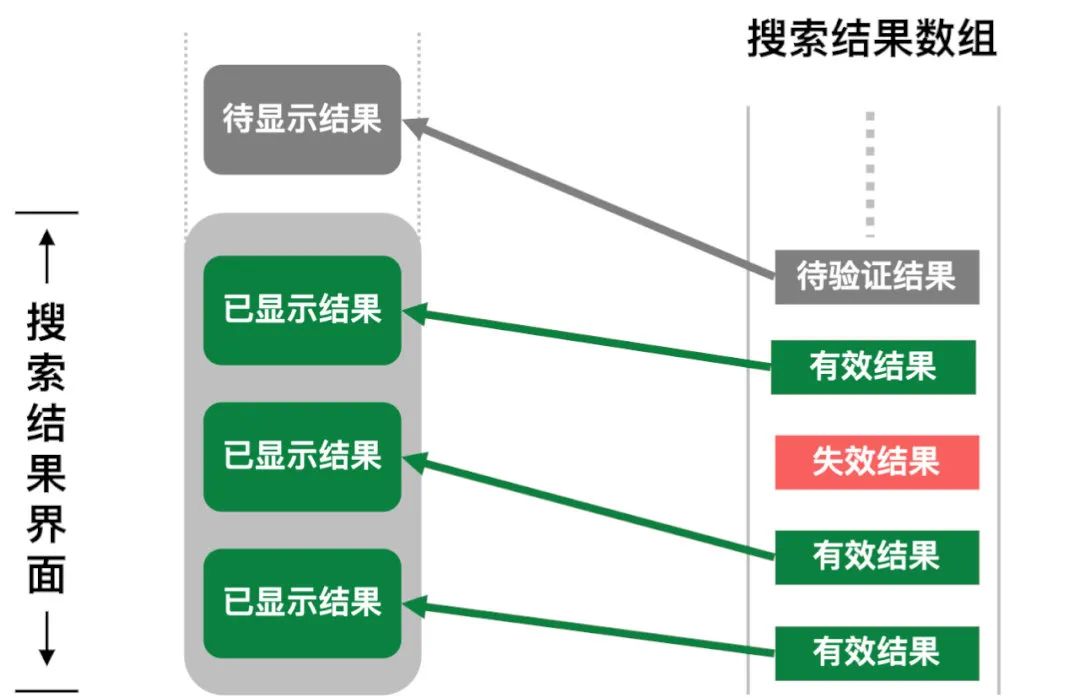
2.2 建索引速度优化
索引只有在搜索的时候才会用到,它的更新优先级并没有业务数据那么高,可以尽量攒更多的业务数据才去批量建索引。批量建索引有以下三个好处:
减少磁盘的写入次数,提高平均建索引速度。
在一个事务中,建索引 SQL 语句的解析结果可以反复使用,可以减少 SQL 语句的解析次数,进而提高平均建索引速度。
减少生成 Segment 的数量,从而减少Merge Segment带来的读写消耗。
当然,也不能保留太多业务数据不建索引,这样用户要搜索时会来不及建索引,从而导致搜索结果不完整。有了前面的Segment自动Merge机制,索引的写入速度非常可控,只要控制好量,就不用担心批量建索引带来的高耗时问题。我们综合考虑了低端机器的建索引速度和搜索页面的拉起时间,确定了最大批量建索引数据条数为 100 条。同时,我们会在内存中 cache 本次微信运行期间产生的未建索引业务数据,在极端情况下给没有来得及建索引的业务数据提供相对内存搜索,保证搜索结果的完整性。因为 cache 上一次微信运行期间产生的未建索引数据需要引入额外的磁盘 IO,所以微信启动后会触发一次建索引逻辑,对现有的未建索引业务数据建一次索引。总结一下触发建索引的时机有三个:
未建索引业务数据达到 100 条。
进入搜索界面。
微信启动。
2.3 删除索引速度优化
索引的删除速度经常是设计索引更新机制时比较容易忽视的因素,因为被删除的业务数据量容易被低估,会被误以为是低概率场景,但实际被用户删除的业务数据可能会达到 50%,是个不可忽视的主场景。而且 SQLite 是不支持并行写入的,删除索引的性能也会间接影响到索引的写入速度,会为索引更新引入不可控因素。
因为删除索引的时候是拿着业务数据的 id 去删除的,所以提高删除索引速度的方式有两种:
建一个业务数据id到 FTS 索引的rowid的普通索引。
在 FTS 索引表中去掉业务数据Id那一列的UNINDEXED约束,给业务数据Id添加倒排索引。
这里倒排索引其实没有普通索引那么高效,有两个原因:
倒排索引相比普通索引还带了很多额外信息,搜索效率低一些。
如果需要多个业务字段才能确定一条倒排索引时,倒排索引是建不了联合索引的,只能匹配其中一个业务字段,其他字段就是遍历匹配,这种情况搜索效率会很低。
2.4 索引更新性能优化数据
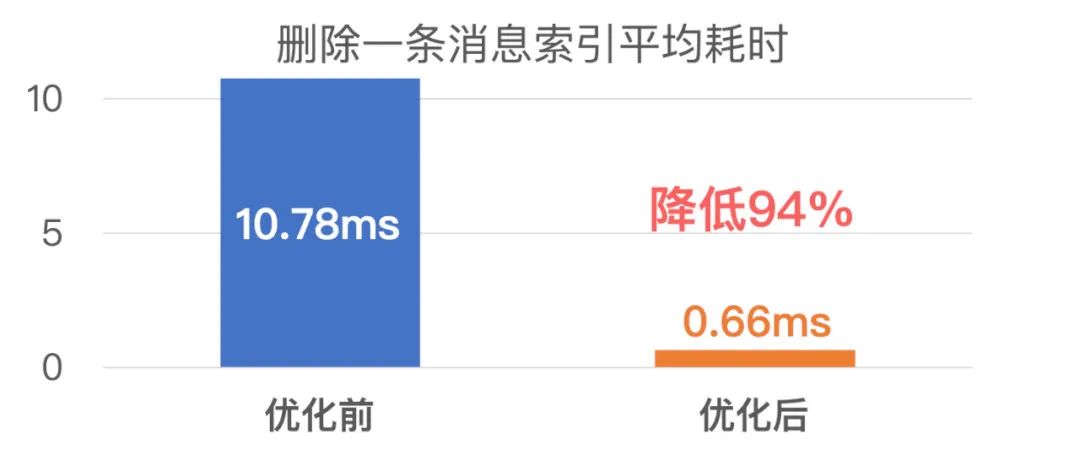
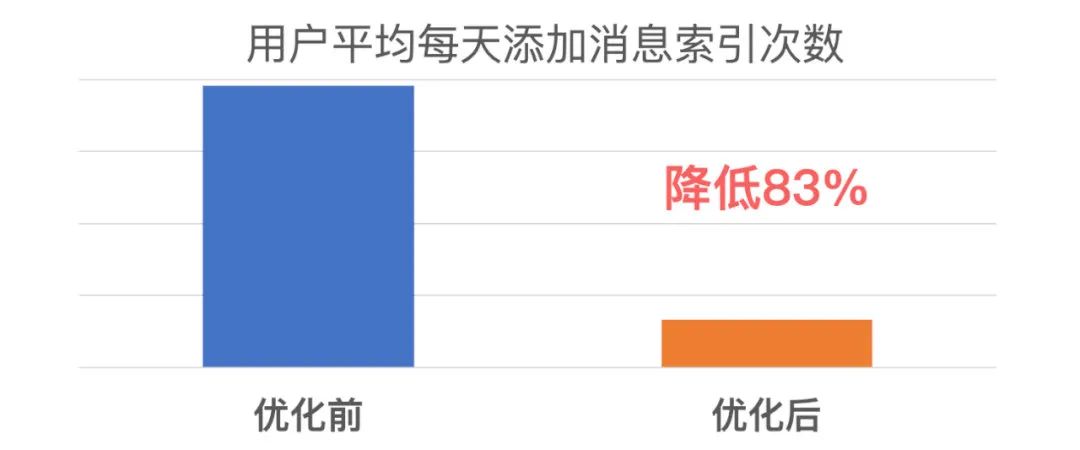
聊天记录的优化前后索引性能数据如下:

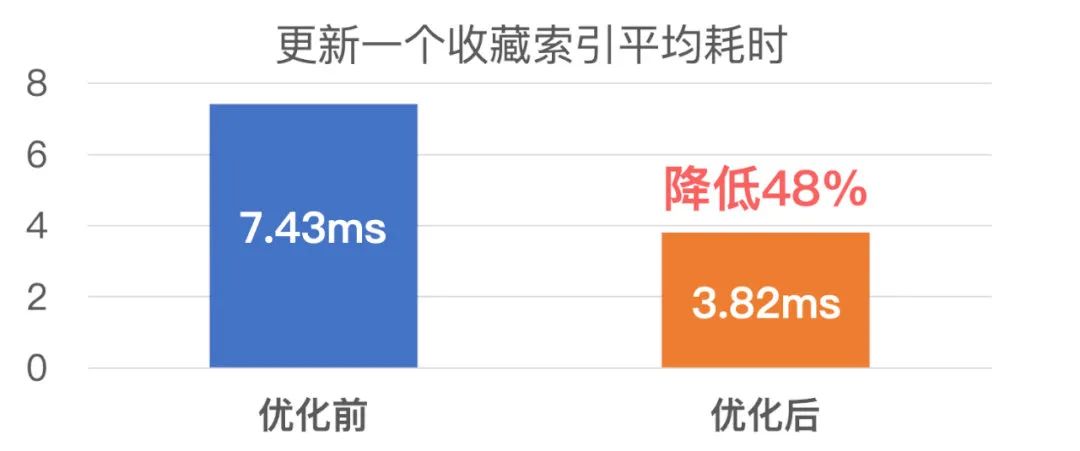
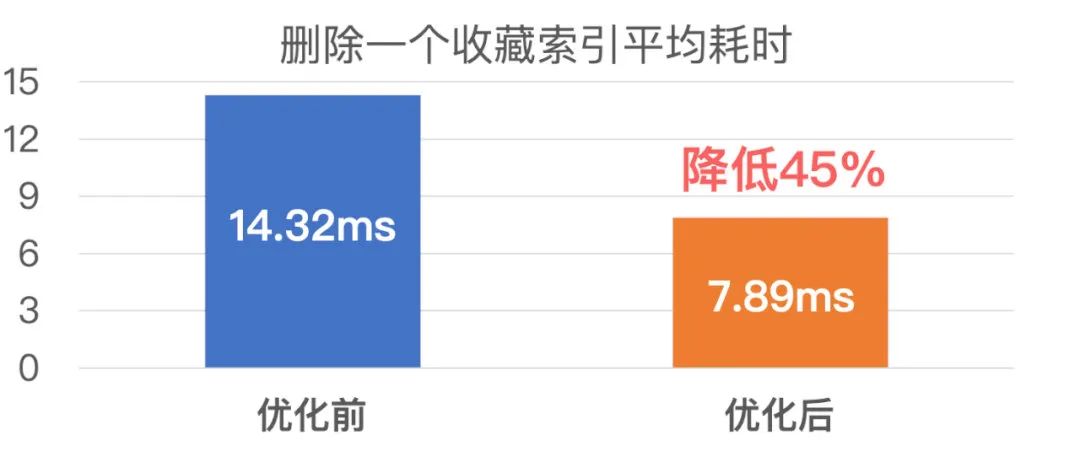
收藏的优化前后索引性能数据如下:

3. 搜索逻辑优化
用户在 iOS 微信的首页输入内容搜索时,搜索的整体流程如下:

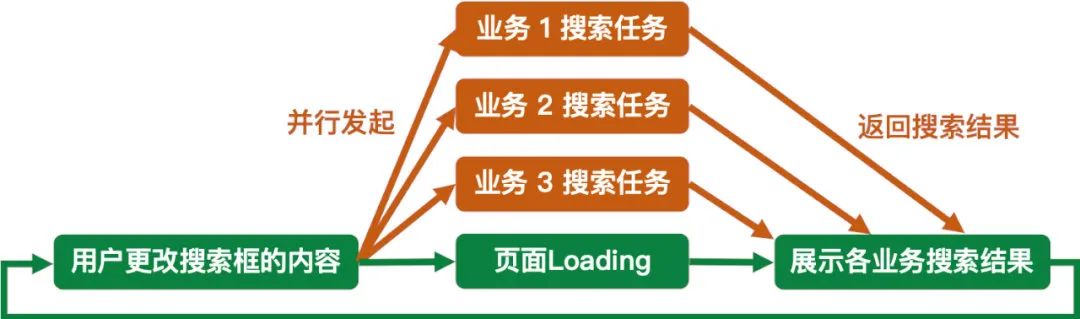
用户变更搜索框的内容之后,会并行发起所有业务的搜索任务,各个搜索任务执行完之后才再将搜索结果返回到主线程给页面展示。这个逻辑会随着用户变更搜索内容而继续重复。
3.1 单个搜索任务支持并行执行
虽然现在不同搜索任务已经支持并行执行,但是不同业务的数据量和搜索逻辑差别很大,数据量大或者搜索逻辑复杂的任务耗时会很久,这样还不能充分发挥手机的并行处理能力。我们还可以将并行处理能力引入单个搜索任务内,这里有两种处理方式:
对于搜索数据量大的业务(比如聊天记录搜索),可以将索引数据均分存储到多个 FTS 索引表(注意这里不均分的话还是会存在短板效应),这样搜索时可以并行搜索各个索引表,然后汇总各个表的搜索结果,再进行统一排序。这里拆分的索引表数量既不能太多也不能太少,太多会超出手机实际的并行处理能力,也会影响其他搜索任务的性能,太少又不能充分利用并行处理能力。以前微信用了十个 FTS 表存储聊天记录索引,现在改为使用四个 FTS 表。
对于搜索逻辑复杂的业务(比如联系人搜索),可以将可独立执行的搜索逻辑并行执行。比如在联系人搜索任务中,我们将联系人的普通文本搜索、拼音搜索、标签和地区的搜索、多群成员的搜索并行执行,搜完之后再合并结果进行排序。这里为什么不也用拆表的方式呢?因为这种搜索结果数量少的场景,搜索的耗时主要是集中在搜索索引的环节,索引可以看做一颗 B 树,将一颗 B 树拆分成多个,搜索耗时并不会成比例下降。
3.2 搜索任务支持中断
用户在搜索框持续输入内容的过程中可能会自动多次发起搜索任务,如果在前一次发起的搜索任务还没执行完时,就再次发起搜索任务,那前后两次搜索任务就会互相影响对方性能。这种情况在用户输入内容从短到长的过程中还挺容易出现的,因为搜索文本短的时候命中结果就很多,搜索任务也就更加耗时,从而更有机会撞上后面的搜索任务。太多任务同时执行还会容易引起手机发烫、爆内存的问题。所以我们需要让搜索任务支持随时中断,这样就可以在后一次搜索任务发起的时候,能够中断前一次的搜索任务,避免任务量过多的问题。
搜索任务支持中断的实现方式是给每个搜索任务设置一个CancelFlag,在搜索逻辑执行时每搜到一个结果就判断一下CancelFlag是否置位,如果置位了就立即退出任务。外部逻辑可以通过置位CancelFlag来中断搜索任务。逻辑流程如下图所示:
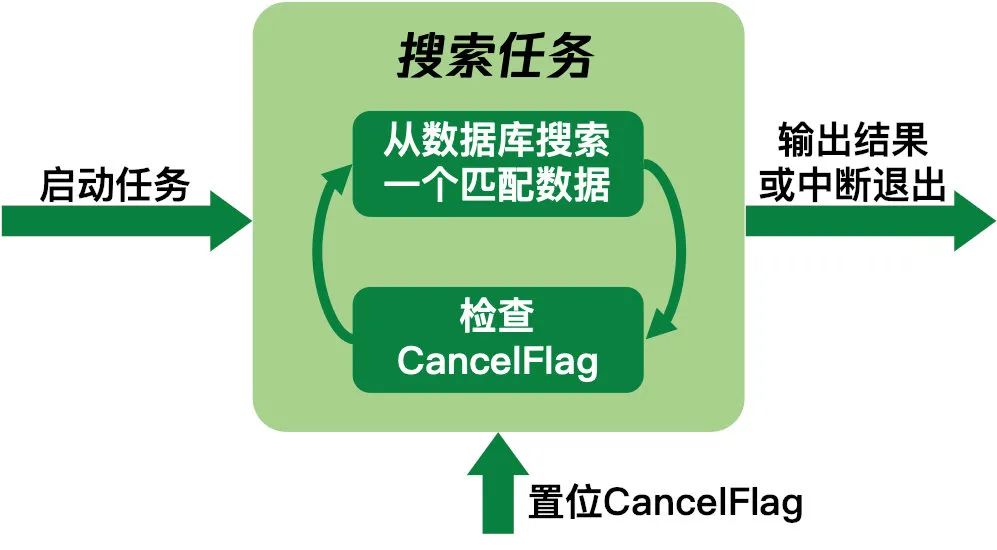
为了让搜索任务能够及时中断,我们需要让检查CancelFlag的时间间隔尽量相等,要实现这个目标就要在搜索时避免使用 OrderBy 子句对结果进行排序。因为 FTS5 不支持建立联合索引,所以在使用OrderBy子句时,SQLite 在输出第一个结果前会遍历所有匹配结果进行排序,这就让输出第一个结果的耗时几乎等于输出全部结果的耗时,中断逻辑就失去了意义。不使用OrderBy子句就对搜索逻辑添加了两个限制:
从数据库读取所有结果之后再排序。我们可以在读取结果时将用于排序的字段一并读出,然后在读完所有结果之后再对所有结果执行排序。因为排序的耗时占总搜索耗时的比例很低,加上排序算法的性能大同小异,这种做法对搜索速度的影响可以忽略。
不能使用分段查询。在全文搜索这个场景中,分段查询其实是没有什么作用的。因为分段查询就要对结果排序,对结果排序就要遍历所有结果,所以分段查询并不能降低搜索耗时(除非按照 FTS 索引的Rowid分段查询,但是Rowid不包含实际的业务信息)。
3.3 搜索读取内容最少化
搜索时读取内容的量也是决定搜索耗时的一个关键因素。FTS 索引表实际是有多个 SQLite 普通表组成的,这其中一些表格存储实际的倒排索引内容,还有一个表格存储用户保存到 FTS 索引表的全部原文。当搜索时读取Rowid以外的内容时,就需要用Rowid到保存原文的表的读取内容,索引表输出结果的内部执行过程如下:
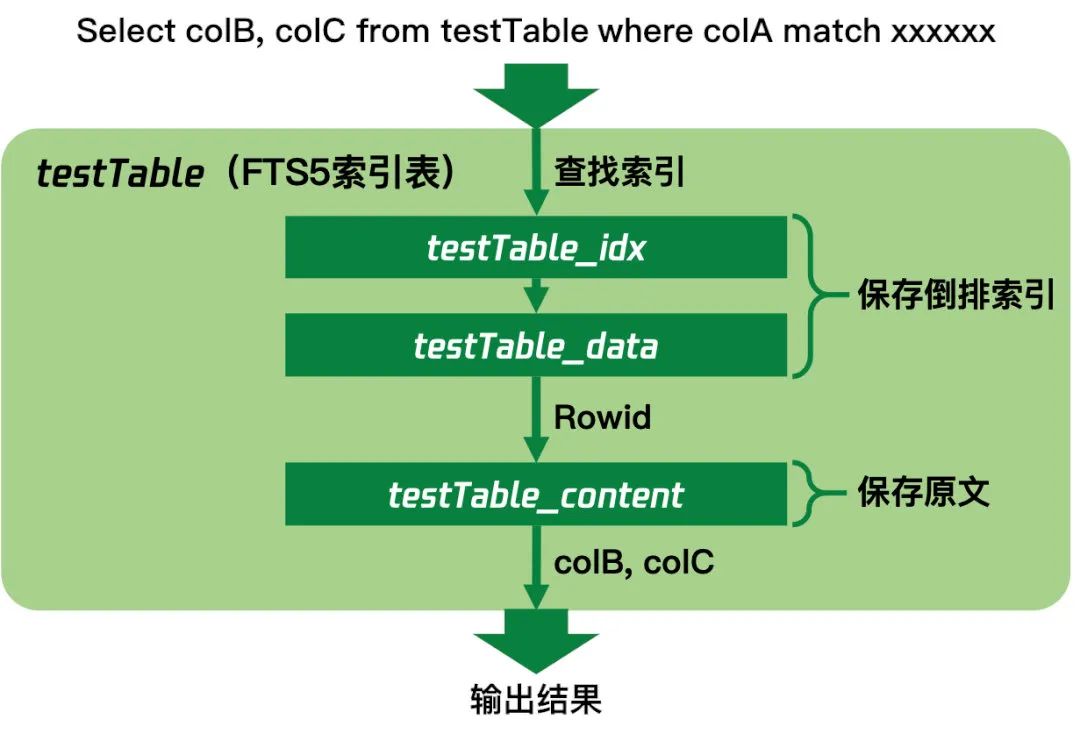
所以读取内容越少输出结果的速度越快,而且读取内容过多也会有消耗内存的隐患。我们采用的方式是搜索时只读取业务数据 id 和用于排序的业务属性,排好序之后,在需要给用户展示结果时,才用业务数据 id 按需读取业务数据具体内容出来展示。这样做的扩展性也会很好,可以在不更改存储内容的情况下,根据各个业务的需求不断调整搜索结果展示的内容。
这里还有一个要特别提一下的地方,就是搜索时尽量不要读取高亮信息(SQLite 的highlight函数有这个能力)。因为要获取高亮字段不仅要将文本的原文读取出来,还要对文本原文再次分词,才能定位命中位置的原文内容,搜索结果多的情况下分词带来的消耗非常明显。那展示搜索结果时如何获取高亮匹配内容呢?我们采用的方式是将用户的搜索文本进行分词,然后在展示结果时查找每个Token在展示文本中的位置,然后将那个位置高亮显示。同样因为用户一屏看到的结果数量是很少的,这里的高亮逻辑带来的性能消耗可以忽略。
当然在搜索规则很复杂的情况下,直接读取高亮信息是比较方便,比如联系人搜索就使用前面提到的SubstringMatchInfo函数来读取高亮内容。这里主要还是因为要读取匹配内容所在的层级和位置用于排序,所以逐个结果重新分词的操作在所难免。
3.4 搜索性能优化数据
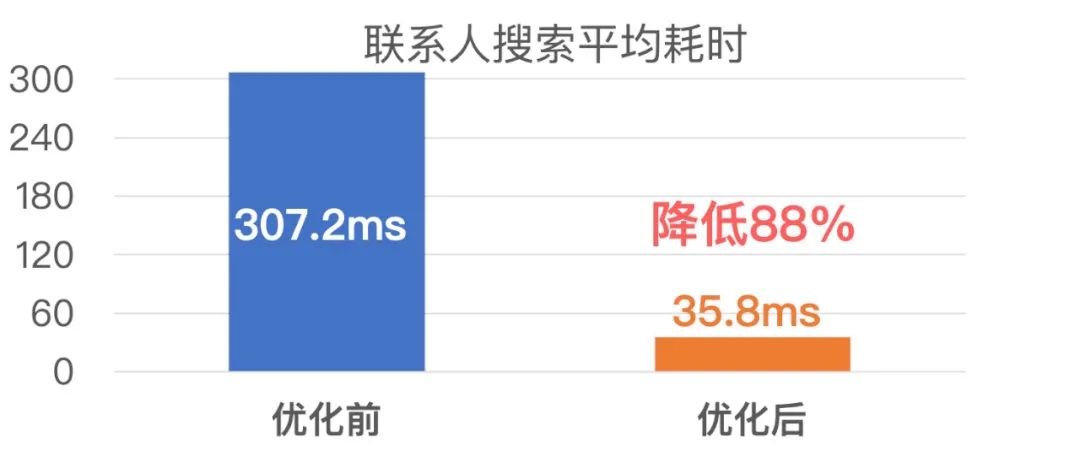
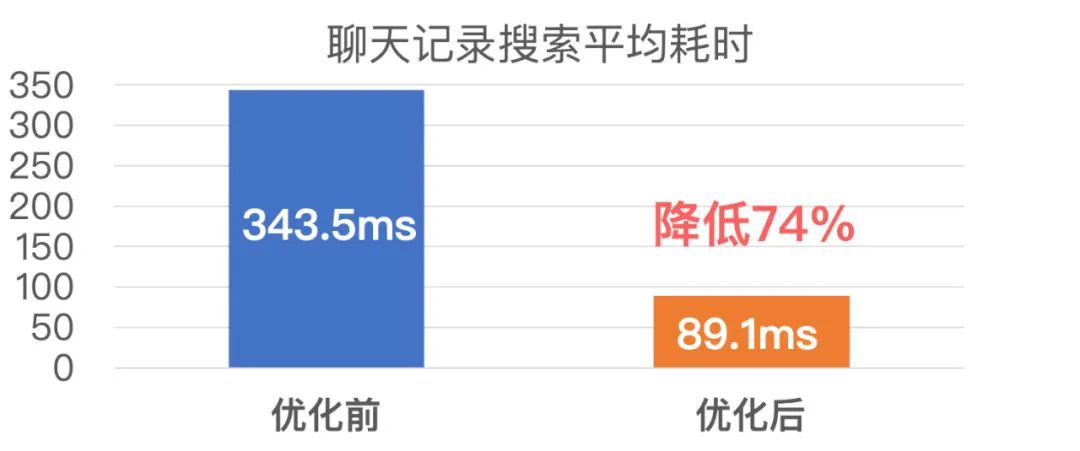
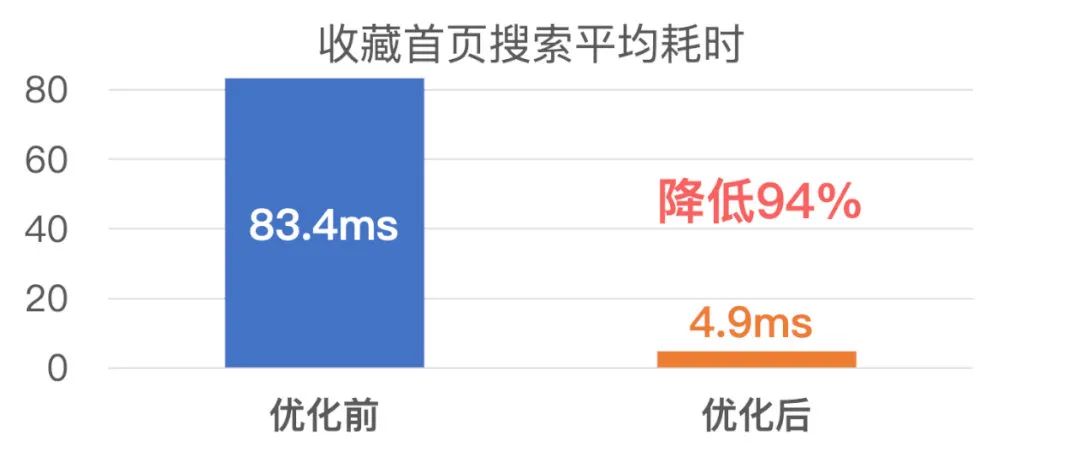
下面是微信各搜索业务优化前后的搜索耗时对比:
四、总结
目前 iOS 微信已经将这套新全文搜索技术方案全量应用到聊天记录、联系人和收藏的搜索业务中。使用新方案之后,全文搜索的索引文件占用空间更小,索引更新耗时更少,搜索速度也更快了,可以说全文搜索的性能得到了全方位提升。

