今天花一分钟,说说使用truncate与delete批量删除数据的异同。

行数据批量delete时,InnoDB如何处理自增ID的?
这里有一个潜在的大坑。
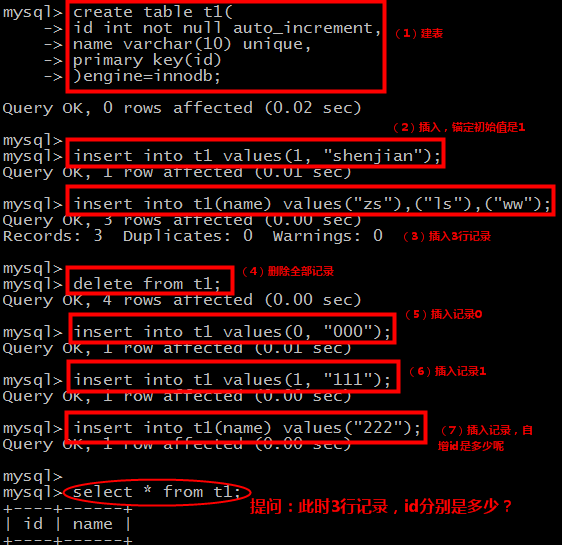
整个实验步骤如上图:
第一步:建表,设定自增列;
第二步:指定id=1插入,锚定第一行是id是1;
第三步:不指定id,依赖自增机制,插入3行;画外音:此时id应该变为2,3,4了?
第四步:delete删除所有记录;画外音:坑就容易出在这里。
第五步:指定id=0插入;
第六步:指定id=1插入;
第七步:不指定id,依赖自增机制,插入1行;
请问,此时表中的三行记录,id分别是多少?
是否符合大家的预期?
今天花1分钟,说说使用truncate与delete批量删除数据的异同。
批量删除数据有三种常见的方法:
(1) drop table:当不需要该表时,可以使用该方法。
(2) truncate table:删除所有数据,同时保留表,速度很快。
画外音:可以理解为,drop table然后再create table。
(3) delete from table:可以删除所有数据,也能保留表,但性能较差。也可以带where条件删除部分数据,灵活性强。
虽然truncate和delete都能够删除所有数据,且保留表,但他们之间是有明显差异的。
(1)
truncate是DDL语句,它不存在所谓的“事务回滚”;
delete是DML语句,它执行完是可以rollback的。
(2)
truncate table返回值是0;
delete from table返回值是被删除的行数。
(3) InnoDB支持一个表一个文件,此时:
truncate会一次性把表干掉,且不会激活触发器,速度非常快;
delete from table则会一行一行删除,会激活触发器,速度比较慢。
画外音:delete数据,是要记录日志的,truncate表不需要记录日志。
(4) 当表中有列被其它表作为外键(foreign key)时:
truncate会是失败;
delete则会成功。
画外音:这类数据删除失败很容易定位问题,因为报错提示简单易懂。
(5) 当表中有自增列时:
truncate会使得自增列计数复原;
delete所有数据后,自增列计数并不会从头开始。
画外音:因此,delete所有数据后,自增列计数的这个行为,往往不是用户想要的,所以是一个潜在坑。
这一分钟,有收获吗?
请根据自己的业务场景,选择删除数据的方式哟。

