如题,自从上周说我们刷好了4.5w的顶会数据,已经过去刚好一周了,在我们团队cc同学
的持续爆肝下,这份有意思的数据,终于可以上线chatpaper.org,供大家免费查阅了!预祝大家速通近三年的AI顶会!另外,目前刚上线,有什么bug,欢迎评论区留言!
Tips: 大家收藏的同时不要忘了点赞!
本贴将详细介绍整个项目的由来和着重介绍顶会论文总结数据库的使用。
1. 简单聊聊开源后上热门的ChatPaper:
1 开发动机
作为一个DRL方向的博士生,GPT3.5API和GPT4的发布,让我有了极大的危机感,AI的进化速度如此迅猛,作为看一篇英文论文,头疼两小时的人类,该怎么不被快速淘汰?

因此我想到,能不能让魔法打败魔法?让AI帮助人类,降低阅读门槛,节省阅读时间,让科研工作者在有限的时间内,借助AI的力量,获得足够多的信息。
于是,我们想到了一个最简洁的方案,就是论文总结。面对海量的论文,我们可以利用AI的强大文本总结能力,快速提取四个核心信息:1. 研究背景;2.过去方案和缺点;3.本文方案和步骤;4.本文实验和性能。相比摘要,一般这样提取的信息量会更加全面。大家可以在文献调研时,快速判断一篇新文章是否需要自己精读,极大降低阅读门槛和时间。
2. 曾在GitHub热榜三天
幸运的是,这个项目刚开源第二天,承蒙GitHub官方看重,挂在热榜第五连续三天,获得了很高的曝光量,截至目前已经获得8125个⭐,也得到了很多同学的支持和反馈。
这个工具算是满足了大家的一个刚需,用于论文阅读前的粗筛。尤其是批量总结,不管是本地文件夹存了很久的论文,还是从ArXiv中,直接就某个关键词,订阅近N天的最新论文。
在此期间,更加幸运的是,有很多非常棒的同学加入维护团队,为了整个项目的完善做出了重要贡献,比如说shiwen同学的ChatReviewer 补齐了我们的审稿和审稿回复功能;荣胜同学使用百万arXiv论文信息,在LLaMA模型上进行微调,做了一个论文题目生成模型 ChatGenTitle。
3. http://ChatPaper.org网站上线
在用户的反馈中,我们得知,不是所有的同学都会配置这个工具。因此我们让同学帮忙配置了一个网站,这样就方便非计算机专业的同学们直接使用。
这个网站之前的功能支持本地PDF的上传,然后返回总结结果,以及提供arxiv的论文链接,网站帮你下载,再总结。由于费用的问题,目前每天仅能支持每个账号2篇的免费额度(没有付费,在其他问题没解决之前,我们也不敢上线付费,敬请谅解,有更多需求的同学,欢迎使用我们开源的脚本)
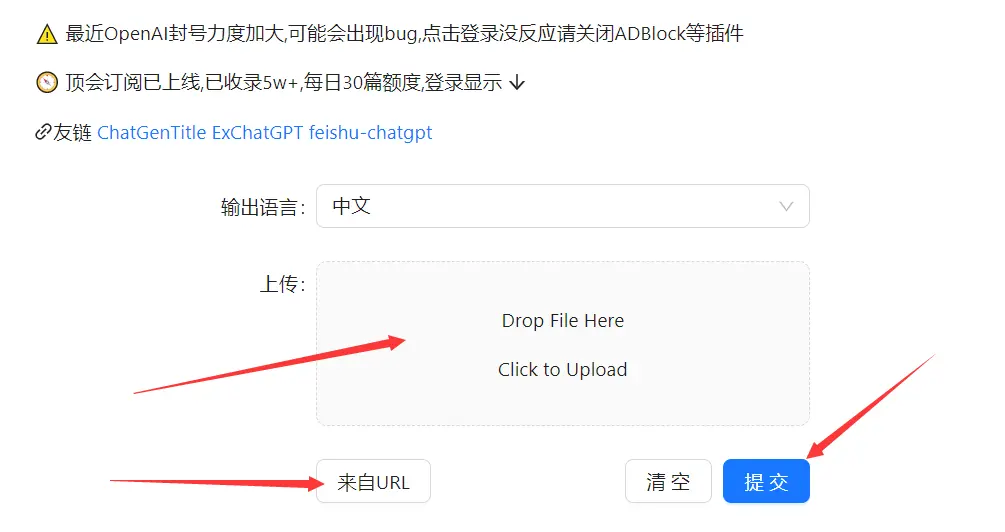
上周已经支持教育邮箱登录,使用起来方便。
4. 顶会论文总结数据库
虽然网站可以让小白用户使用起来更加方便,但是使用体验还比较感人,用的人多了,经常要等好几分钟才能总结一篇。
因此我们又想到,能不能将高价值的论文,提前总结好?大家需要的时候,直接刷就可以了。
而价值最高,阅读频次也高的AI顶会论文自然是上上选。感谢另外一位大佬贡献的项目paper_downloader,让我们得以非常方便的下载好AAAI, ACCV, AISTATS, COLT, CVPR, ECCV, ICCV, ICLR, ICML, IJCAI, JMLR, NIPS 这些顶会论文的PDF。

于是,我们的cc同学
这段时间,先是刷了4.5w的顶会论文总结数据库,然后在谷歌学术上统计基础信息(作者,摘要,引用数等信息,虽然仍然有不全或者错乱的情况,后面会上线编辑反馈的功能),再接着将这些数据,在mingyuan同学的前端帮助下,整理排版好,终于在上周日凌晨上线网站!

5. 使用步骤:
进入我们的网站:chatpaper.org
使用教育邮箱注册账号。[如果无法注册或者登录,可以使用谷歌浏览器的隐私模式]
登录账号[一定要记住密码,我们还没上线 找回密码 的功能 [开发时间实在不够]]
每天有2篇本地或者在线PDF总结的额度;
上传+提交即可,也可以选择输出的语言,换成英文也行;
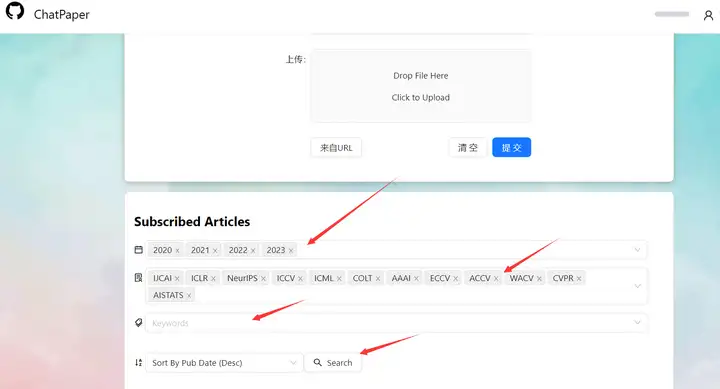
速通顶会论文。只需要将页面往下拉,选择 年份,会议,关键词,和排序,点击search即可速通!
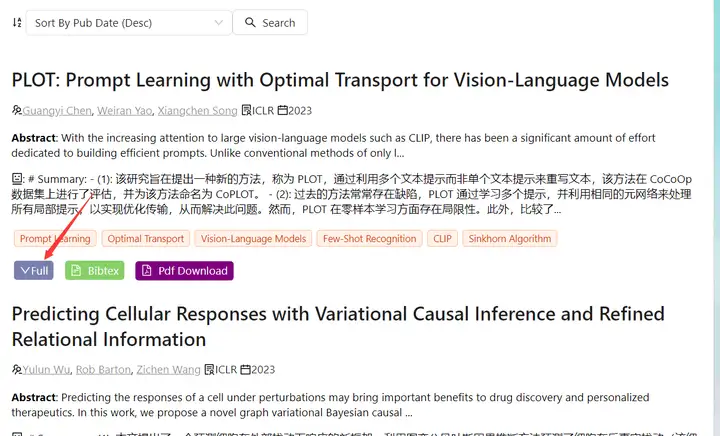
7. 展开总结全文:目前没有给每个总结单独的页面,都是在首页进行展示,需要看总结全文,点击full即可。如果对全文感兴趣,直接点击下载链接。
8. 下一页:拉到页面底部,点击右下角的按键,进入下一页。

6. 关于额度和反爬的讨论:
因为这个数据库的总结,花了我们团队很多钱和精力,我们暂时不太想开源,希望大家能够理解。
然后因为我们开源习惯了,所以还是愿意长期免费提供给大家进行查阅,希望能够给整个社区带来一些价值。
因此我们做了这样一个权衡,每天给用户提供30-40篇的查阅额度[正常情况下,应该算充足?],希望大家手下留情,请不要爬我们的数据[qwq].
如果大家有更好的方案,欢迎评论区留言!
7. 其他的一些AI加速科研的小技巧分享:
我们这个仅适用于初筛,精读论文最好是靠自己阅读原文!人的脑子和大语言模型类似,也需要高质量的长文本输入输出,才会有进步!
精读论文时,可以在大脑清醒的时候,拿走手机,念读出来!除了单词翻译工具,其他的对话工具,都可能会影响你的思路!
GPTs作为某种意义上的条件概率生成模型,输入内容多-输出内容少,更能保证准确性和减少hallucination。
基于关键词的角色扮演:你现在是xx领域的教授xx,请帮我润色下面的论文:[文本内容]
格式化输出:请按照xxx; xxx[yyy]的格式输出/按照latex格式输出
格式化的示例(few-shot):按照论文的经验,提供一个完整的例子,便于LLM举一反三。
可验证的文本生成:对于你懂的,但记不清,或者懂的不多的领域,可以尝试让它实现具体某个任务,事半功倍。 比如代码生成,极大降低查阅文档的时间;建议使用新必应 有报错,把报错信息贴回新必应; 长文本输入输出,建议使用GPT-4.
哈佛博士的教程:GPT可以提供次优选项,让人做选择题,而不用做填空题。 https://twitter.com/kareem_carr/status/1640003536925917185
9. 其他的教程可以参考我之前的帖子:ChatPaper的类似产品:BriefGPT,论文阅读神器SciSpace(Typeset.io)测评,NewBing一分钟速读论文
10. 我们后面正在开源众筹另外一个项目,ChatOpenReview:利用OpenReview的优质审稿数据,微调出一个专业的审稿和审稿回复GPT,欢迎大家一起搞事。
8. 最后:
欢迎大家使用我们的论文总结数据库,欢迎大家点赞和转发这篇帖子,欢迎大家对我们后面的功能开发做反馈,希望我们团队能为咱们的科研社区做点微小的贡献~
转载自知乎 原文地址:https://zhuanlan.zhihu.com/p/620682991

