摘要: 本文主要讲述了如何管理机器学习应用方面的棘手问题
应用机器学习是有挑战性的。
在机器学习领域,你必须要在没有正确答案的问题上做出很多决定!例如:
· 用什么框架?
· 用什么数据作为输入,要输出什么数据?
· 用什么算法?
· 用什么算法配置?
这些问题对于初学者来说是一个严峻的挑战。
读完本文之后,你将了解:
· 如何形成一个明确的学习问题。
· 当给你的问题设计一个学习系统的时候,有四个决策点需要考虑。
· 你可以用三个决策来明确地来应对在实践中设计学习系统的难题。
概述
本文分成了如下六个部分:
1、适定的学习问题
2、选择训练数据
3、选择目标函数
4、选择目标函数的表达形式
5、选择学习算法
6、如何设计学习系统
适定的学习问题
我们可以将应用机器学习领域中的一般学习任务定义为一个程序,它可以根据特定的性能测量从一些任务中学习经验。
Tom Mitchell在他1997年《Machine Learning》一书中做了清晰的阐述:
一个计算机程序是从某一类任务T和性能测量结果P中学习经验E的,如果它在T中的任务表现为P,则用经验E来改进。
我们以这个作为对那些我们可能感兴趣的学习任务类型的一般定义,例如预测建模等应用机器学习。Tom列举了几个例子来说明这一点,如下所示:
· 学习识别口语
· 学习无人驾驶
· 学习天体结构分类
· 学习世界级的双陆棋
我们用上面的定义来定义自己的预测建模问题。一旦定义了,任务就会变成设计一个学习系统来应对。
设计一个学习系统,如:一个机器学习应用,涉及了四个设计选择:
1、选择训练数据
2、选择目标函数
3、选择表达形式
4、选择学习算法
对于一个给定的问题并提供了无限的资源,可能有最好的一组选择,但是我们没有无限的时间来计算资源,以及领域内的或者是学习系统的知识。
因此,尽管我们能准备一个适定的学习问题的描述,设计这个最有可能的学习系统还是很困难的。我们最好就是用知识,技巧,和可用的资源通过设计的选择来进行我们的工作。
让我们更详细地看一下每一个设计选择
选择训练数据
你必须选择学习系统将要用到的数据作为学习经验。
这是过去观测到的数据
现有的训练经验类型对研究人员的成败有着重大影响。
对于学习问题,你必须经常收集需要的数据。
这个意思是:
· 清除文件
· 查询数据
· 执行文件
· 整理不同资源
· 合并实体
你需要一次性获取到所有的数据,并且变成一个标准化的形式,这样一个观测就代表了一个结果是可用的实体。
选择目标函数
下一步,你必须选择一个学习问题的框架
机器学习实际上是一个学习从输入(X)到输出(y)的映射函数(f)的问题
Y=f(x)
这个函数能被用在将来预测最可能输出结果的新数据上。
学习系统的目标是准备一个函数,提供了可用资源,将输入映射到输出。这是一个称为函数近似的问题。这个结果将是一个近似值,意味着有误差。我们将尽力减小这个误差,但是一些误差将一直在数据中存在并进行干扰。
这一步是关于精确地选择输入什么数据到这个函数,例如:输入特征或者输入变量还有预测什么,例如:输出变量。
我经常将此称为学习问题的框架,选择输入和输出本质上即是选择目标函数的类型,就是我们将寻求相近的函数。
选择目标函数的表达形式
下一步,你必须选择你希望用来映射函数的表达形式
考虑这个作为你希望能用来做预测的最终模型的类型。你必须选择这个模型的形式,选择是否你喜欢的数据结构。
现在我们已经详述了这个理想的目标函数V,必须选择一个表达形式,学习程序将用来描述将要学习的函数V。
例如:
· 也许你的项目需要一个易于理解并向利益相关方解释的决策树。
· 也许你的利益相关方倾向于一个线性模型,统计人员能很容易地解释。
· 也许你的利益相关方不关心除了模型表现以外的任何事,因此所有的模型表达形式都是可以争取的。
表示的选择将限制学习算法的类型,您可以使用这些算法来学习映射函数。
选择一个学习算法
最后,你必须选择学习算法,该学习算法执行输入输出数据并且学习你倾向的表达式的。
如果在表达形式的选择上面没有什么限制,那么经常是这样,然后你可能评价一系列不同的算法和表达式。
如果在表达形式的选择上面有一些严格的限制,例如:一个加权和线性模型或者一个决策树,那么算法的选择将被限于能操作特定表达形式的那些。
算法的选择可以利用自身的限制,例如像数据标准化那样的特定数据的准备转换。
如何设计学习系统
开发一个学习系统是有挑战性的。
从这个方式上没人能告诉你每个决定的最佳答案;对于你指定的学习问题,最好的答案是未知的。
Mitchell描述了在设计一个下棋学习系统所做的选择的时候,帮助澄清了这一点。
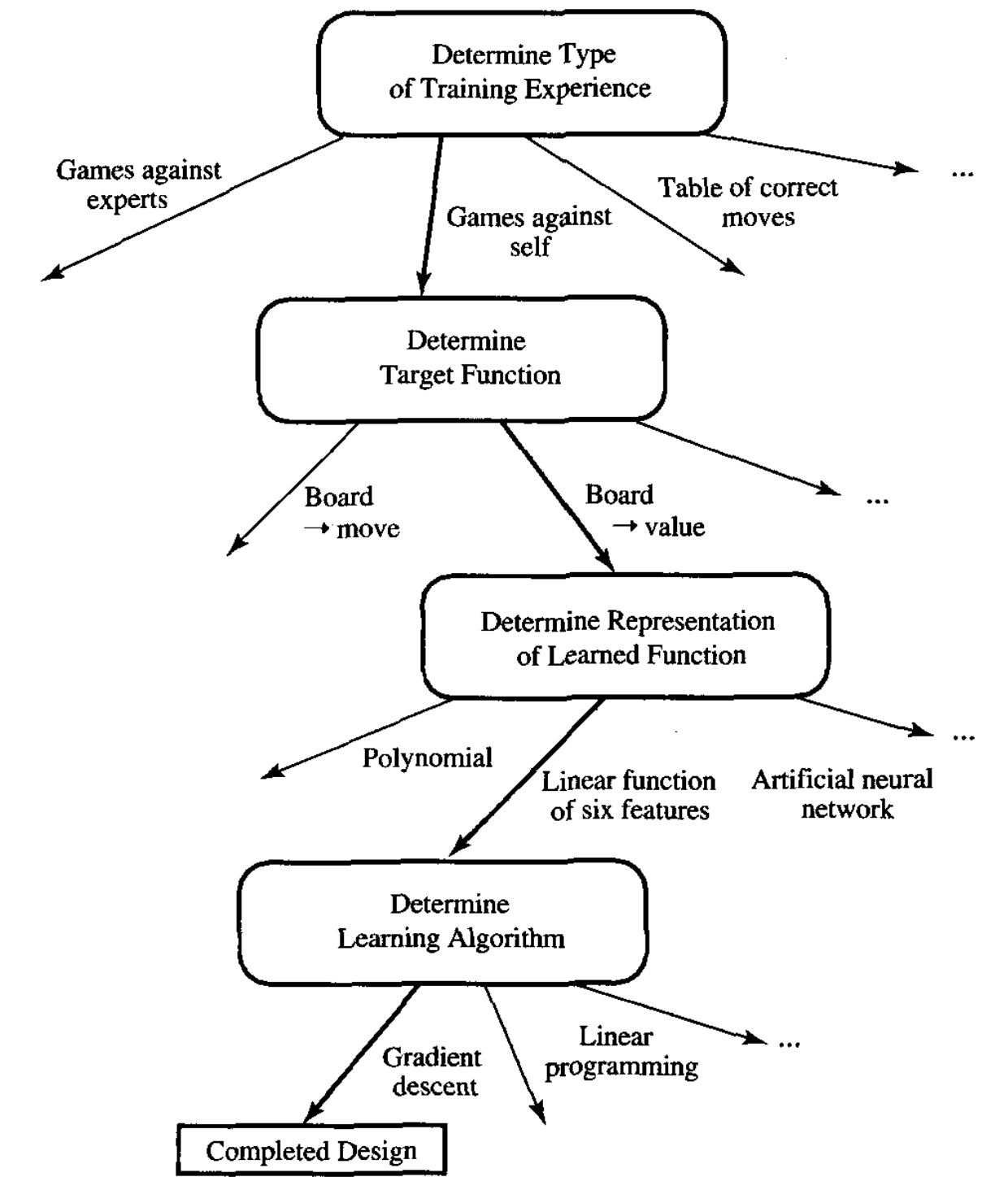
在设计一个下棋学习系统时的选择描述。
来自“Machine Learning”, 1997。
Mitchell说:
在许多方法上,这些设计选择已经约束了学习任务。我们已经限定了能被用来获取到一个线性评估函数的知识类型。除此之外,我们还限定了评估函数依赖于仅仅提供的这六个特定的板特征(board features)。如果这个正确的目标函数V能真正的被这些特殊特征的线性组合所表示,那么我们的程序会有一个好的机会来学习它。如果相反,那么我们希望最好是它将学习一个比较理想的近似值,因为一个程序肯定永远也学不到它至少不能表示的东西。
通常地,你不能通过分析的方法计算出这些选择的答案,例如用什么数据,用什么算法,用什么算法配置。
这里是你能在实践中用到的三个策略:
1、复制:看文献或者向专家学习与你的问题相同或相近的问题,并且复制学习系统的设计。很可能你不是第一个致力于给定类型问题的人。在最坏的情况下,复制的设计给你的设计提供了一个起点。
2、查找:在每个决策点列出可用的选项,并且对每一个进行经验评估,看看哪个对你的具体数据最有效。这可能是在应用机器学习中最健壮和最实用的成果
3、设计:通过上面的复制和查找方法,在完成了许多项目之后,你将为了如何设计及其学习系统而形成了一个直觉。
开发学习系统不是一个科学而是一个工程。
开发新的机器学习算法和描述它们如何工作与为什么工作是一门科学,并且在开发学习系统时,这通常不是必需的。
开发一个学习系统与开发软件非常的相似。你必须结合过去工作中设计的成果副本,能显示出有用的那些原型,还有为了得到最好的结果而开发一个新系统的时候的设计经验。
推荐阅读阅读:
Machine Learning, 1997书中相关问题解释的更全面。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Why Applied Machine Learning Is Hard》
作者: Jason Brownlee
译者:奥特曼,审校:袁虎。
文章为简译,更为详细的内容,请查看原文

