
神经网络是一种机器学习算法,它可以提高许多用例(项目)的精确度。但是,很多时候我们构建的神经网络的准确性可能不令人满意,或者可能无法让我们排在数据科学竞赛排行榜的头号位置。因此,我们一直在寻找更好的方法来改善模型的性能。并且有很多技术可以帮助我们实现这一目标,本文的目标就是向各位介绍这些技术,希望各位在本文的帮助下能够建立自己的准确度更高的神经网络。
检查是否过度拟合
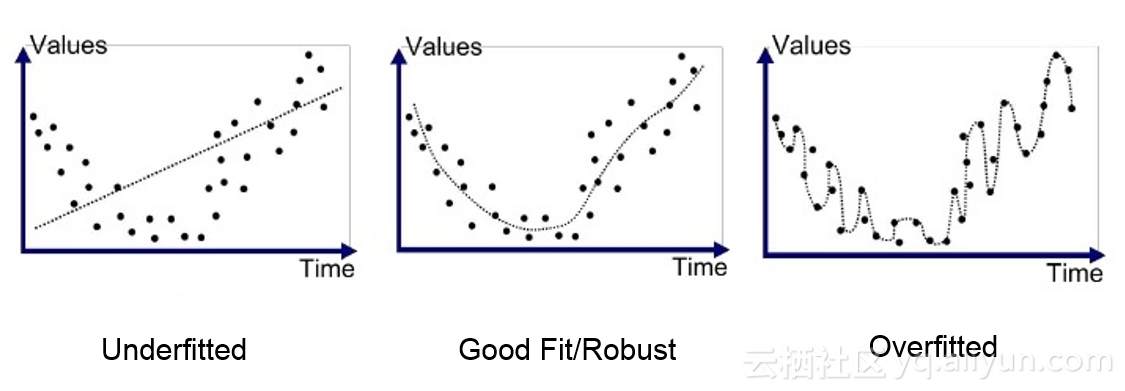
确保你的神经网络在测试数据上表现良好的第一步是验证你的神经网络没有过度拟合。OK,我们先介绍什么是过度拟合?过度拟合发生在你的模型开始记忆训练数据的值而不是从中学习时。更通俗的过度拟合介绍,可以点击查看激活引入非线性,池化预防过拟合(深度学习入门系列之十二)PS:作者新书马上出版——《深度学习之美》。因此,当你的模型遇到一个它以前从未见过的数据时,它无法很好地处理它们。为了让你更好地理解,让我们来看一个类比。我们都会有一个善于背诵的同学,并且假设数学考试即将到来。你和你的朋友,善于记忆,从课本开始学习。你的朋友会记住教科书中的每一个公式,问题和答案,但是另一方面,你比他聪明,所以你决定建立直觉并解决问题,并学习这些公式如何发挥作用。考试日到了,如果试卷中的问题直接出自教科书,那么你可能没有你的朋友做得好,但如果问题不是教科书里面的问题呢,那么你在考试中一定相比你的朋友来说做得更好。
如何识别你的模型是否过度拟合?你可以交叉检查训练的准确性和测试的准确性。如果训练的准确性远远高于测试的准确性,那么你可以假设你的模型已经过度拟合。你还可以绘制图表上的预测点来验证,有一些技巧可以避免过度拟合:
· 数据正规化(L1或L2);
· Dropout——随机丢弃神经元之间的连接,迫使网络找到新的路径并推广;
· 提早停止——减少神经网络的训练,从而减少测试集中的错误。
超参数调整
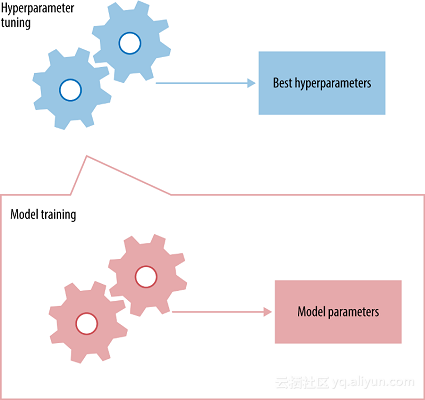
超参数是你必须初始化到网络的值,这些值在训练时无法通过网络获知。例如:在卷积神经网络中,一些超参数是核的大小、神经网络中的层数、激活函数、损失函数、使用的优化器(梯度下降,RMSprop)、批量大小、要训练的纪元数量等。
每个神经网络都具有其最佳的超参数集合,因为这会提高神经网络的准确性。你可能会问,“有那么多的超参数,我该如何选择每个使用的参数?”,告诉你一个不幸的消息,没有直接的方法来确定每个神经网络的最佳超参数集合,所以它主要是通过反复试验获得的。但是,对于刚刚提到的一些超参数有一些最佳实践:
· 学习率——选择最佳学习率非常重要,因为它决定了你的网络是否收敛到最低值。选择最高学习率几乎不会让你达到最低标准,因为你很有可能超越它。因此,你总是在最低点附近,但从来没有收敛到它。选择一个小的学习率可以帮助神经网络收敛到最小值,但需要大量的时间。因此,你必须对网络进行更长时间的训练。较小的学习率也会使网络容易陷入局部最小化,即由于学习率较低,网络将会收敛到局部最小值,并且无法退出。因此,在设定学习率时一定要小心。
· 网络体系结构——没有标准体系结构可以在所有测试案例中为你提供高精度。你必须尝试,尝试不同的体系结构,然后从结果中获得推论,然后再试一次。我建议的一个想法是使用经过验证的架构,而不是构建自己的架构。例如:对于图像识别任务,你有VGG net,Resnet,Google的Inception网络等等。这些都是开源的,并且已经证明是非常准确的,因此,你可以复制他们的架构并调整它们以达到你的目的。
· 优化器和Loss function——有无数的选项供你选择。事实上,如果需要,甚至可以定义自定义丢失函数。但常用的优化器是RMSprop,随机梯度下降和Adam,这些优化器似乎适用于大多数用例。如果你的用例是分类任务,那么常用的损失函数是分类交叉熵。如果你正在执行回归任务,均方误差是最常用的损失函数。随意试验这些优化器的超参数,以及不同的优化器和损失函数。
· 批处理大小和历元数量——同样,对于所有用例都没有批处理大小和历元的标准值。你必须尝试并尝试不同的,在一般情况下,批量值设置为8,16,32 ...历元的数量取决于开发人员的偏好和他/她拥有的计算能力。
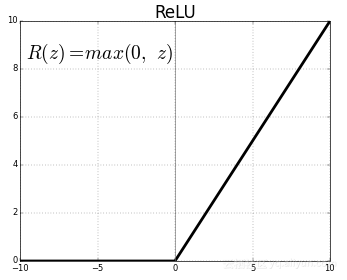
· 激活函数——激活函数将非线性功能输入映射到输出。激活函数非常重要,选择正确的激活函数可帮助你的模型更好地学习。如今,整流线性单元(ReLU)是最广泛使用的激活函数,因为它解决了渐变消失的问题。早期的Sigmoid和Tanh是使用最广泛的激活函数。但是,他们遭遇了消失梯度的问题,即在反向传播期间,当它们到达开始层时,梯度会减少。这阻止了神经网络扩大到更多层次的更大尺寸。ReLU能够克服这个问题,因此允许神经网络具有大尺寸。
算法集合

如果单个神经网络不如你所希望的那样准确,你可以创建一个神经网络集合并结合它们的预测能力。你可以选择不同的神经网络架构,并对数据的不同部分进行训练,并将它们集成并使用其集体预测能力来获得测试数据的高精度。假设你正在建造一只猫和狗的分类器,0猫和1狗。当组合不同的猫和狗分类器时,集合算法的准确性会根据各个分类器之间的Pearson相关性而增加。让我们看一个例子,拿3个模型并测量他们的个人准确性。
Ground Truth: 1111111111Classifier 1: 1111111100 = 80% accuracy Classifier 2: 1111111100 = 80% accuracy Classifier 3: 1011111100 = 70% accuracy
三种模型的Pearson相关性很高,因此,将它们合并不会提高准确性。如果我们用多数投票合奏上述三个模型,我们得到以下结果。
Ensemble Result: 1111111100 = 80% accuracy
现在,让我们看看三个模型的输出之间Pearson相关性非常低。
Ground Truth: 1111111111 Classifier 1: 1111111100 = 80% accuracy Classifier 2: 0111011101 = 70% accuracy Classifier 3: 1000101111 = 60% accuracy
当我们把这三个比较弱的学习者合并时,我们得到以下结果。
Ensemble Result: 1111111101 = 90% accuracy
正如你在上面看到的,一个具有低Pearson相关性的弱学习者集合能够胜过它们之间具有高Pearson相关性的集合。
缺乏数据
运用上述所有的技术后,如果你的模型在测试数据集中仍然表现不佳,则可能归因于缺乏训练数据。有许多用例可用的训练数据量受到限制,如果你无法收集更多数据,则可以使用数据增强技术。

如果你正在处理图像数据集,则可以通过剪切图像、翻转图像、随机裁剪图像等来增加训练数据的新图像。这可以为神经网络训练提供不同的示例。
文章原标题《how-to-increase-the-accuracy-of-a-neural-network》,
译者:虎说八道,审校:袁虎。文章为简译,更为详细的内容,请查看原文。

