4.What you can cram into a single vector: Probing sentence embeddings for linguistic properties,作者:ALEXIS CONNEAU,KRUSZEWSKI,GUILLAUME LAMPLE,LOÏCBARRAULT,MARCO BARONI
论文摘要
尽管最近在训练高质量的句子嵌入上做出了很多的努力,但是大家仍然对它们所捕捉的内容缺乏了解。基于句子分类的‘Downstream’tasks通常用于评估句子表示的质量。然而任务的复杂性使得它很难推断出句子表示中出现了什么样的信息。在本文将介绍10个probing tasks,旨在捕捉句子的简单语言特征,并用它们来研究由三种不同编码器产生的句子嵌入,这些编码器以八种不同的方式进行训练,揭示了编码器和训练方法的有趣特性。
总结
Facebook AI研究团队试图更好地理解句子嵌入所捕获的内容。因为任务的复杂性不允许我们直接获得理解。因此,论文介绍了10个旨在捕捉句子简单语言特征的探究任务。通过这些探测任务获得的结果可以揭示编码器和训练方法的一些有趣特性。
论文的核心思想是什么?
· 我们有许多句子嵌入方法,表现出非常好的表现,但我们仍然缺乏对它们如何捕获的内容的理解。
· 研究人员通过引入10个探测任务来研究由3种不同编码器(BiLSTM-last,BiLSTM-max和Gated ConvNet)生成的嵌入来解决这个问题,这些编码器以8种不同的方式进行训练。
· 探测任务测试句子嵌入保留的程度:
1. 表面信息(句子中的单词数、单词内容);
2. 句法信息(词序、句子的层次结构、最高成分的顺序);
3. 语义信息(主句动词的时态、主语和宾语的数量、随机替换的单词)。
什么是关键成就?
· 对现代句子编码器进行广泛的评估。
· 揭示编码器和训练方法的一些有趣属性:
1. 由于自然语言输入的冗余,Bag-of-Vectors所擅长得捕获句子级属性令人惊讶。
2. 相似性能的不同编码器架构可导致不同的嵌入。
3. 卷积架构的整体探测任务性能与最佳LSTM架构的性能相当。
4. BiLSTM-max在探测任务中优于BiLSTM。此外,即使没有经过任何训练,它也能实现非常好的性能。
未来的研究领域是什么?
· 将探测任务扩展到其他语言和语言域。
· 调查多任务训练如何影响探测任务的性能。
· 通过引入的探测任务,找到更多具有语言意识的通用编码器。
什么是可能的商业应用?
1、更好地理解不同预训练编码器捕获的信息将有助于研究人员构建更多具有语言意识的编码器。反过来,这将改善将会被应用在NLP系统中。
你在哪里可以得到实现代码?
1、GitHub上提供了本研究论文中描述的探测任务。
5.SWAG:一个用于给定信息的常识推理的大规模对抗性数据集,作者:ROWAN ZELLERS,YONATAN BISK,ROY SCHWARTZ,YEJIN CHOI
论文摘要
人类可以因为一些描述从而推断出下面要发生什么,例如“她打开汽车的引擎盖”,“然后,她检查了发动机”。在本文中,我们介绍并整理了基础常识推理。我们提出SWAG,一个新的数据集,包含113k多项选择问题,涉及丰富的基础推理。为了解决许多现有数据集中发现的注释工件和人类偏见的反复出现的挑战,我们提出了一种新颖的过程,它通过迭代训练一组风格分类器构建一个去偏见的数据集,并使用它们来过滤数据。为了解释对抗性过滤,我们使用最先进的语言模型来大量过滤一组不同的潜在反事实。实证结果表明,虽然人类可以高精度地解决由此产生的推理问题(88%),但各种竞争模型仍在努力完成我们的任务。
总结
当你读到“他将生鸡蛋面糊倒入锅中时,他…”你可能会这样选择“提起锅并移动它来搅拌。”我们可以发现,答案并不明显,这需要常识推理。SWAG是支持研究自然语言推理(NLI)与常识推理大规模数据集。它是使用一种新颖的方法——对抗性过滤创建的,它可以以最经济有效的方式构建未来的大规模数据集。
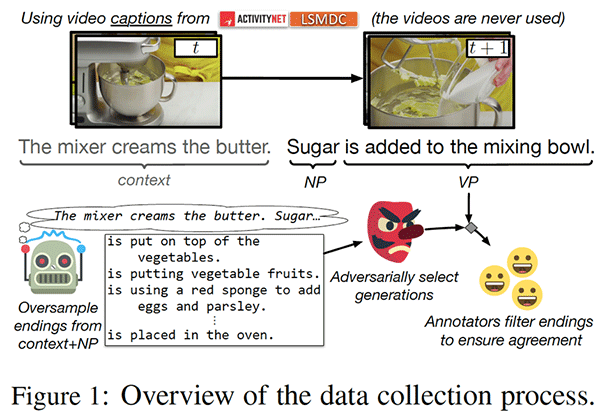
论文的核心思想是什么?
· SWAG包含113K多项选择题,大多是视频字幕:
1、上下文的句子来自于视频字幕。
2、正确的答案是实际视频中的下一个字幕。
3、使用对抗过滤(AF)生成错误的答案。
· Adversarial Filtering背后的想法:
1、大量生成错误答案,然后选择哪些看起来像真正答案的回答。
2、过滤模型确定哪些回答似乎是机器生成的。这些回答被删除并替换为模型认为是人为编写的新回答。
· 最后,整个数据集由众包工作者验证。
什么关键成就?
· 提出一个新的具有挑战性的大规模数据集来测试NLI系统。
· 引入Adversarial Filtering,这种方法可用于经济高效地构建大型数据集,具有以下几个优点:
1、句子的多样性不受人类创造力的限制;
2、数据集创建者可以在数据集构建期间任意提高难度;
3、人类不会写回答但只会验证它们,这样更经济;
AI社区的想法是什么?
· 该论文在2018年一个自然语言处理领域领先的会议上被发表。
· 即使在此重要的NLP会议上发布之前,该数据集也是通过Google的新BERT模型解决的,该模型的准确度达到了86.2%并且非常接近人类的准确度(88%)。
未来的研究领域是什么?
1ã使用更好的Adversarial Filtering和语言模型创建更具对抗性的SWAG版本。
什么是可能的商业应用?
1ã该数据集可以帮助构建具有常识推理的NLI系统,从而改善Q&A系统和会话AI的开发。
你在哪里可以获得实现代码?
1、SWAG数据集可在GitHub上获得。
6.(ELMO词向量模型)作者:MATTHEW E. PETERS,MARK NEUMANN,MOHIT IYYER,MATT GARDNER,CHRISTOPHER CLARK,KENTON LEE,LUKE ZETTLEMOYER
论文摘要
本文推出了一种新的基于深度学习框架的词向量表征模型,这种模型不仅能够表征词汇的语法和语义层面的特征,也能够随着上下文语境的变换而改变。简单来说,本文的模型其实本质上就是基于大规模语料训练后的双向语言模型内部隐状态特征的组合。实验证明,新的词向量模型能够很轻松的与NLP的现有主流模型相结合,并且在六大NLP任务的结果上有着巨头的提升。同时,作者也发现对模型的预训练是十分关键的,能够让下游模型去融合不同类型的半监督训练出的特征。
总结
艾伦人工智能研究所的团队引入了一种新型的深层语境化词汇表示:语言模型嵌入(ELMo)。在ELMO增强模型中,每个单词都是根据使用它的整个上下文进行矢量化的。将ELMo添加到现有NLP系统可以实现:
1:相对误差减少范围从6-20%;
2:显著降低训练模型所需的时期数量;
3:显著减少达到基线性能所需的训练数据量。
论文的核心思想是什么?
· 生成词嵌入作为深度双向语言模型(biLM)的内部状态的加权和,在大文本语料库上预训练。
· 包括来自biLM的所有层的表示,因为不同的层表示不同类型的信息。
· 基于角色的ELMo表示,以便网络可以使用形态线索来“理解”在训练中看不到的词汇外令牌。
取得了什么关键成就?
· 将ELMo添加到模型中会创造新的记录,在诸如问答、文本蕴涵、语义角色标记、共指解析、命名实体提取、情绪分析等NLP任务中相对误差降低6-20%。
· 使用ELMo增强模型可显著着降低达到最优性能所需的训练次数。因此,具有ELMo的语义角色标签(SRL)模型仅需要10个时期就可以超过在486个训练时期之后达到的基线最大值。
· 将ELMo引入模型还可以显著减少实现相同性能水平所需的训练数据量。例如,对于SRL任务,ELMo增强模型仅需要训练集的1%即可获得与具有10%训练数据的基线模型相同的性能。
AI社区对其的评价?
· 该论文被NAACL评为优秀论文,NAACL是世界上最具影响力的NLP会议之一。
· 本文介绍的ELMo方法被认为是2018年最大的突破之一,也是NLP未来几年的主要趋势。
未来的研究领域是什么?
1、通过将ELMos与不依赖于上下文的词嵌入连接起来,将此方法合并到特定任务中。
可能的商业应用的范围是什么?
ELMo显著提高了现有NLP系统的性能,从而增强了:
1. 聊天机器人将更好地理解人类和回答问题;
2. 对客户的正面和负面评论进行分类;
3. 查找相关信息和文件等;
你在哪里可以得到实现代码?
艾伦研究所提供英语和葡萄牙语预训练的ELMo模型,你还可以使用TensorFlow代码重新训练模型。
7.用于低资源神经机器翻译的元学习,作者:JIATAO GU,WANG WANG,YUN YUN,KYUNGHYUN CHO,VICTOR OK LI
论文摘要
在本文中,我们建议扩展最近引入的模型:不可知元学习算法(MAML),用于低资源神经机器翻译(NMT)。我们将低资源翻译构建为元学习问题,并且我们学习基于多语言高资源语言任务来适应低资源语言。我们使用通用词汇表示来克服不同语言的输入输出不匹配的问题。我们使用十八种欧洲语言(Bg,Cs,Da,De,El,Es,Et,Fr,Hu,It,Lt,Nl,Pl,Pt,Sk,Sl,Sv和Ru)评估所提出的元学习策略,源任务和五种不同的语言(Ro,Lv,Fi,Tr和Ko)作为目标任务。我们证实了,所提出的方法明显优于基于多语言迁移学习的方法,这能够使我们只用一小部分训练样例来训练有竞争力的NMT系统。例如,通过通过16000个翻译单词(约600个并行句子),用所提出的方法在罗马尼亚语-英语WMT'16上实现高达22.04 BLEU。
总结
香港大学和纽约大学的研究人员使用模型无关的元学习算法(MAML)来解决低资源机器翻译的问题。特别是,他们建议使用许多高资源语言对来查找模型的初始参数,然后,这种初始化允许仅使用几个学习步骤在低资源语言对上训练新的语言模型。
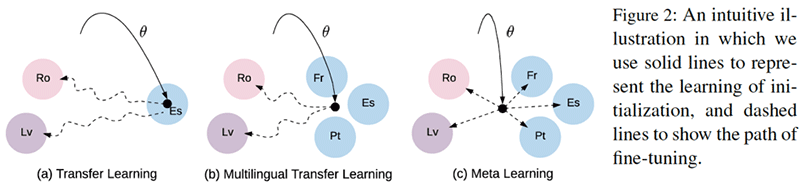
论文的核心思想是什么?
· 介绍了一种新的元学习方法MetaNMT,该方法假设使用许多高资源语言对来找到良好的初始参数,然后从找到的初始参数开始在低资源语言上训练新的翻译模型。
· 只有在所有源和目标任务之间共享输入和输出空间时,元学习才能应用于低资源机器翻译。然而,由于不同的语言具有不同的词汇。为了解决这个问题,研究人员使用键值存储网络动态地构建了针对每种语言的词汇表。
关键成就是什么?
· 为极低资源语言找到了神经机器翻译的新方法,其中:
1、能够在高资源和极低资源语言对之间共享信息;
2、仅使用几千个句子来微调低资源语言对上的新翻译模型;
· 实验证明:
1、元学习始终比多语言迁移学习好;
2、元学习验证集语言对的选择会影响结果模型的性能。例如,当使用罗马尼亚语-英语进行验证时,芬兰语-英语受益更多,而土耳其语-英语则更喜欢拉脱维亚语-英语的验证。
AI社区对它的看法?
· 该论文在自然语言处理领域领先的会议EMNLP上被发表。
· 所提出的方法获得了Facebook的低资源神经机器翻译奖。
未来的研究领域是什么?
· 半监督神经机器翻译的元学习或单语语料库的学习。
· 当学习多个元模型且新语言可以自由选择适应的模型时,进行多模态元学习。
什么是可能的商业应用?
· MetaNMT可用于改善可用并行语料库非常小的语言对的机器翻译结果。
你在哪里可以得到实现代码?
1、MetaNMT的PyTorch实施可以在Github上找到。
文章原标题《WE SUMMARIZED 14 NLP RESEARCH BREAKTHROUGHS YOU CAN APPLY TO YOUR BUSINESS》作者:Mariya Yao
译者:虎说八道,审校:袁虎。

