前段时间老罗和王校长都成为自己的创业公司成了失信人,小五打算上IT桔子看看他们的公司。
意外发现IT桔子出了个死亡公司库,统计了2000-2019年之间比较出名的公司“死亡”数据。

小五利用python将其中的死亡公司数据爬取下来,借此来观察最近十年创业公司消亡史。
获取数据
F12,Network查看异步请求XHR,翻页。
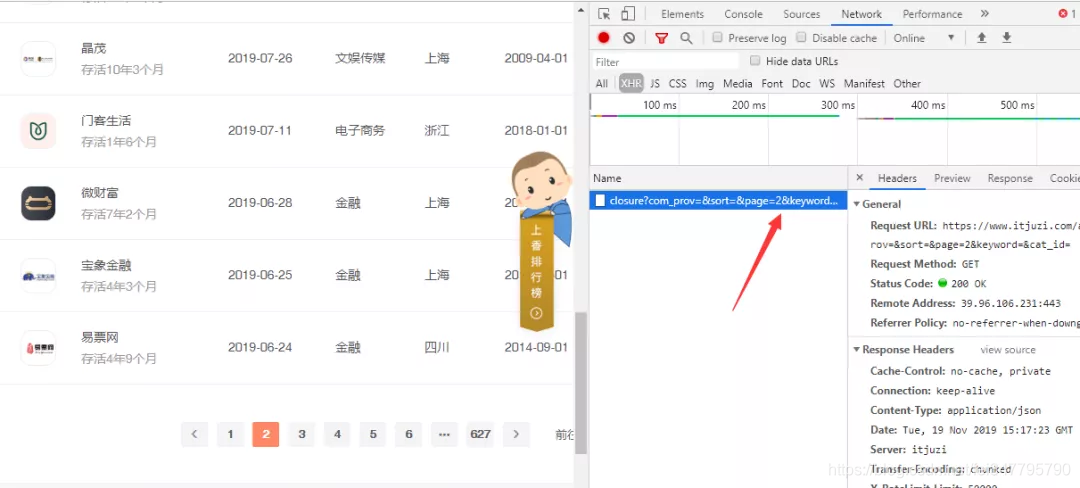
成功找到返回json格式数据的url,
https://www.itjuzi.com/api/closure?com_prov=&fund_status=&sort=&page=1
不了解json的读者可以看【python玩转Json数据】,部分爬虫代码
def main():
data = pd.DataFrame(columns=['com_name','born','close','live_time','total_money','cat_name','com_prov','closure_type'])
for i in range(1,2): #设置爬取N页
url= 'https://www.itjuzi.com/api/closure?com_prov=&fund_status=&sort=&page='+ str(i)
html = requests.get(url=url, headers=headers).content
doc = json.loads(html.decode('utf-8'))['data']['info']
for j in range(10): #一页10个死亡公司
data = data.append({'com_name':doc[j]['com_name'],'born':doc[j]['born'],'cat_name':doc[j]['cat_name'],
'closure_type':doc[j]['closure_type'],'close':doc[j]['com_change_close_date'],'com_prov':doc[j]['com_prov'],
'live_time':doc[j]['live_time'],'total_money':doc[j]['total_money']},ignore_index=True)
time.sleep(random.random())
return data
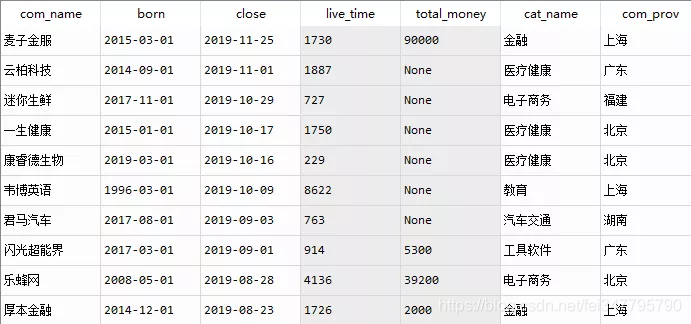
成功获取6271家死亡公司数据。
数说10年生死相
截止 2019 年 11 月 24 日,共有近6271家公司在 IT 桔子数据库中被标注为“已关闭”,我们挑选最近十年(2010-2019)的5765家公司,来看一看这十年,创业公司的消亡。
大家常说1998年是中国互联网元年,2010年是移动互联网的元年。
也难怪,2010年的移动互联网实在是太热闹了。微信、小米、美团、爱奇艺等都在这一年相继成立。
百度在谷歌退出中国后成为最大的受益者,淘宝成为阿里新的增长点,腾讯则宣布QQ同时在线超1亿人。自此,百度、阿里和腾讯正式成为“三巨头”——BAT。除此之外,网易的网游、新浪的微博、搜狐的视频和输入法也开始发力出击,移动互联网的竞争正式拉开帷幕。
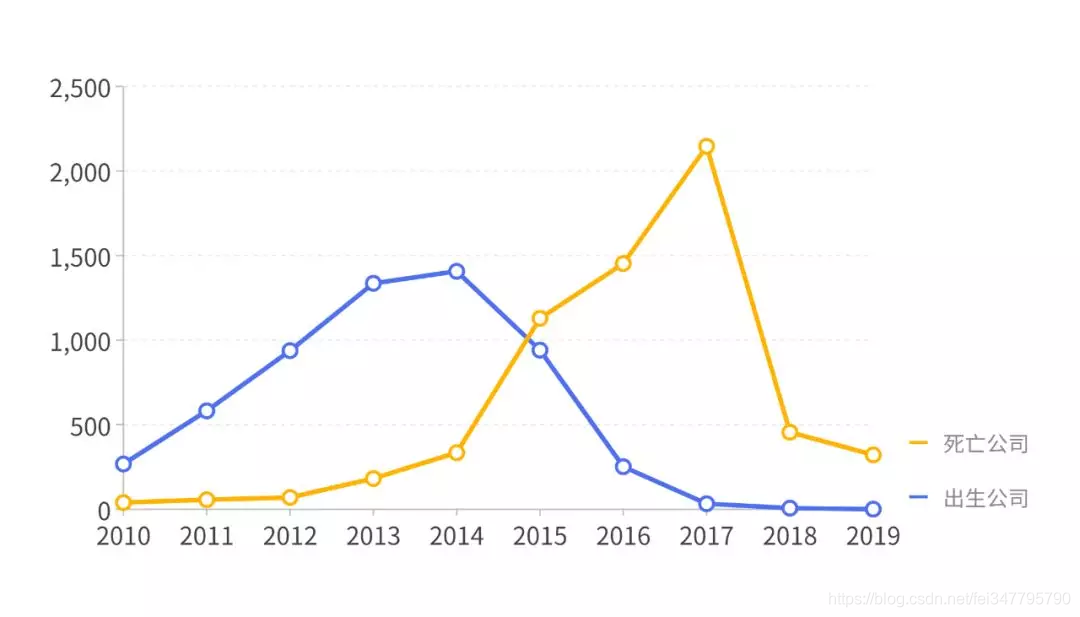
2010 年来,历年出生及死亡的公司数量趋势如下图。
2013、2014 年是公司诞生潮,三年后,正好对应了2016、2017的一波死亡潮。在2017 年,超过 2000 家公司倒闭。
在这十年间,诸多“风口”起起伏伏。网约车、团购、直播、基因检测、共享单车、短视频、比特币、VR|AR、无人货架、人工智能、直播带货……
每一个风口上,都站着数百头“猪”,试图借力分一杯羹。
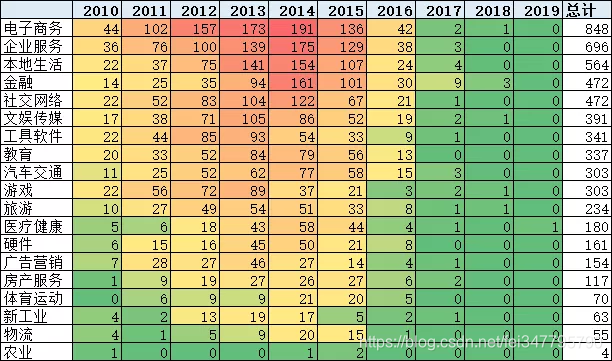
百团大战、垂直电商大战、外卖大战、打车大战、单车大战,在这些著名的战场里,各种桥段令吃瓜群众们目不暇接。有老大老二打架,老三打没了;有老二老三合并,继续和老大抗衡的;也有老大老二合并,将其他家远远甩在后面的……
还有像冲顶大会之类直播答题一样,办起来的时候,各家分庭抗礼来势汹汹,却从2018年的公历新年开始,没有挺到农历新年。
风口消亡的背后,是无数创业公司烧掉的钱,每个公司在一开始,都坚信可以烧倒对手,但烧着烧着把自己烧光了,却再也拿不到融资。
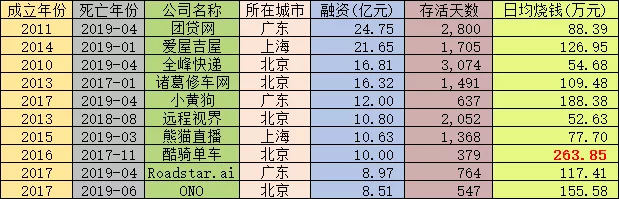
创业公司的消亡,究其原因必然是多方面的,除行业竞争激烈这一核心因素外,最主要的还是商业模式的匮乏。创业者内在对于如何维稳、如何盈利等方面欠缺的了解、思考与准备,不足以在行业稳定后,支撑他在风口来临之初的一腔热血豪情。
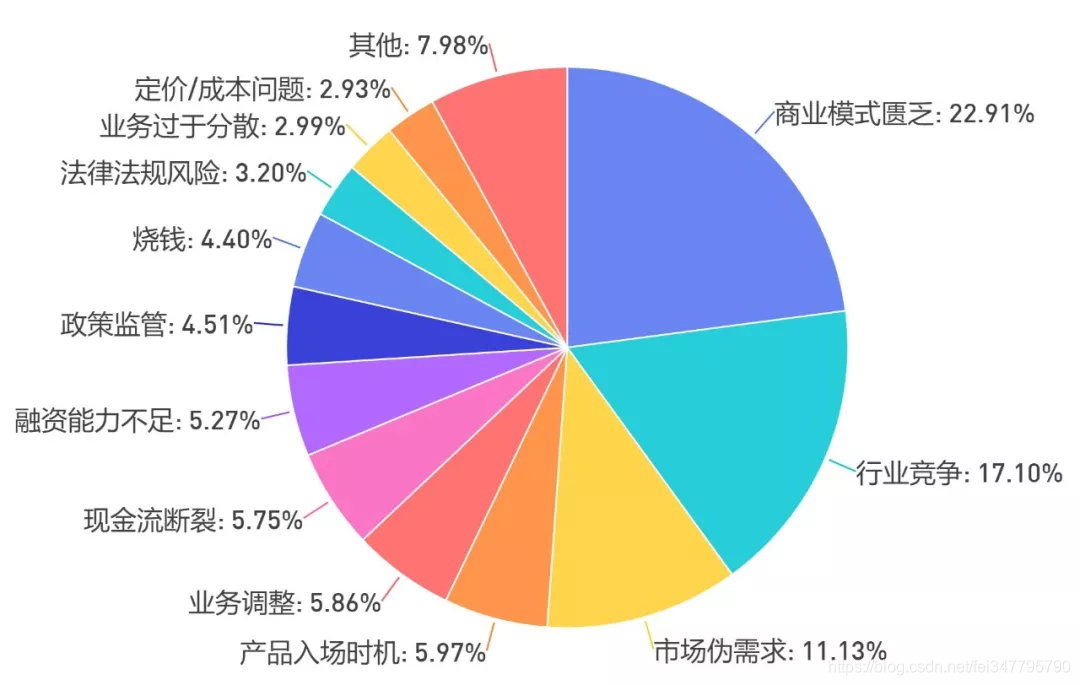
另外,“伪风口”与“伪需求”也曾迷住众多创业公司的眼。“共享经济”衍生出的共享单车、共享充电宝红红火火,但共享电话、共享厕纸、共享篮球什么的,倒也不必。
比较有意思的是,这个死亡公司数据库还加了一个#上香排行榜#,排行第一的果然是大名鼎鼎的“快播”。

还真是有的公司死了,(在人心里)他还活着;
有的公司活着,(在人心里)他已经死去。
代码
1 import requests
2 import json
3 import pandas as pd
4 import time
5 import random
6 from fake_useragent import UserAgent
7 ua = UserAgent()
8 headers = {'User-Agent':ua.random} #伪装请求头
9
10 def main():
11 data = pd.DataFrame(columns=['com_name','born','close','live_time','total_money','cat_name','com_prov','closure_type'])
12 for i in range(1,2): #设置爬取N页
13 url= 'https://www.itjuzi.com/api/closure?com_prov=&fund_status=&sort=&page='+ str(i)
14 html = requests.get(url=url, headers=headers).content
15 doc = json.loads(html.decode('utf-8'))['data']['info']
16 for j in range(10): #一页10个死亡公司
17 data = data.append({'com_name':doc[j]['com_name'],'born':doc[j]['born'],'cat_name':doc[j]['cat_name'],
18 'closure_type':doc[j]['closure_type'],'close':doc[j]['com_change_close_date'],'com_prov':doc[j]['com_prov'],
19 'live_time':doc[j]['live_time'],'total_money':doc[j]['total_money']},ignore_index=True)
20 time.sleep(random.random())
21 return data
22
23 if __name__ == "__main__":
24 final_result = main()
25 #final_result.to_csv("final_result.csv", index_label="index_label",encoding='utf-8-sig')

