在年终岁尾之际,盘一盘大家比较关心的一些数据。今天先来看看各大数据库在过去一年的表现!

图片来自 Pexels
先来看看数据库流行度总体走势:
数据获取
所有的数据都来源自一个数据库流行趋势统计网站:
https://db-engines.com/
Method 1
我们先来看获取数据方法,首先我们可以在下面地址中看到一个包含所有数据库信息的表格:
https://db-engines.com/en/ranking

然后可以进入到每个数据库详情页面中,该数据库历年流行度数据都会在页面加载之后包含在 JavaScript 的变量中:
https://db-engines.com/en/ranking_trend/system/Oracle

所以我们可以通过解析该 JavaScript 代码来获取每个数据库的历年数据,同时为了加快抓取速度,使用了异步请求。
先抓取所有数据库名称信息,通过 Pandas 的 read_html 方法可以方便的读取 HTML 中的 Table 数据:
import pandas as pd mystr = ' Detailed vendor-provided information available' def set_column3(column3): if mystr in column3: column3 = column3.split(mystr)[0] return column3 url = 'https://db-engines.com/en/ranking' tb = pd.read_html(url) db_tb = tb[3].drop(index=[0, 1, 2])[[0, 1, 2, 3, 4, 5, 6, 7]] # 处理数据 db_tb[3] = db_tb[3].apply(set_column3) # 保存数据 db_tb.to_csv('db_tb.csv')异步抓取数据库详细信息:
async def fetch(session, url): async with session.get(url) as response: return await response.text() async def get_db_data(db_name): url = 'https://db-engines.com/en/ranking_trend/system/%s' % db_name async with aiohttp.ClientSession() as session: res = await fetch(session, url) content = BeautifulSoup(res, "html.parser") content.find_all("script") db_data = content.find_all("script")[2].string src_text = js2xml.parse(db_data) src_tree = js2xml.pretty_print(src_text) data_tree = BeautifulSoup(src_tree, 'html.parser') data_tree.find_all('number') data = [] for i in data_tree.find_all('number'): data.append(i['value']) date_list = gen_time('%s-%s' % (data[0], str(int(data[1]) + 1))) date_value = list(zip(date_list, data[3:])) d_data = zip([db_name for i in range(len(date_value))], date_value) await save_data(d_data) def gen_time(datestart, dateend=None): if dateend is None: dateend = time.strftime('%Y-%m', time.localtime(time.time())) datestart=datetime.datetime.strptime(datestart, '%Y-%m') dateend=datetime.datetime.strptime(dateend, '%Y-%m') date_list = list(OrderedDict(((datestart + timedelta(_)).strftime(r"%Y-%m"), None) for _ in range((dateend - datestart).days)).keys()) date_list.append('2019-12') return date_list if __name__ == '__main__': db_tb = pd.read_csv('db_tb.csv') db_name = db_tb['3'].values.tolist() loop = asyncio.get_event_loop() tasks = [get_db_data(name) for name in db_name] loop.run_until_complete(asyncio.wait(tasks)) loop.close()Method 2
下面再来介绍第二种方法,方法更简单,但是抓取时需要处理的地方更多一些。
我们可以直接访问下面的地址,同样的,在页面加载完成后,会返回所有数据库的历年数据信息:
https://db-engines.com/en/ranking_trend

那么我们就可以直接解析此处的 JavaScript 信息,获取对应数据库的数据即可。
不过由于有些数据库的历史数据有缺失,所以需要做特殊处理:
for i in data_tree.find_all('object'): date_list = gen_time('%s-%s' % (year_list[0], str(int(year_list[1]) + 1))) data = [] tmp_list = [] db_name = i.find('string') if i.find('null'): null_num = len(i.find_all('null')) tmp_list = list(zip(date_list[:null_num], ['0' for i in range(null_num + 1)])) date_list = date_list[null_num:] for j in i.find_all('number'): data.append(j['value'])两种方法各有优缺点,小伙伴儿们可以自行选择适合自己的方式。拿到数据之后,我们就可以做统计分析啦。
数据库总榜
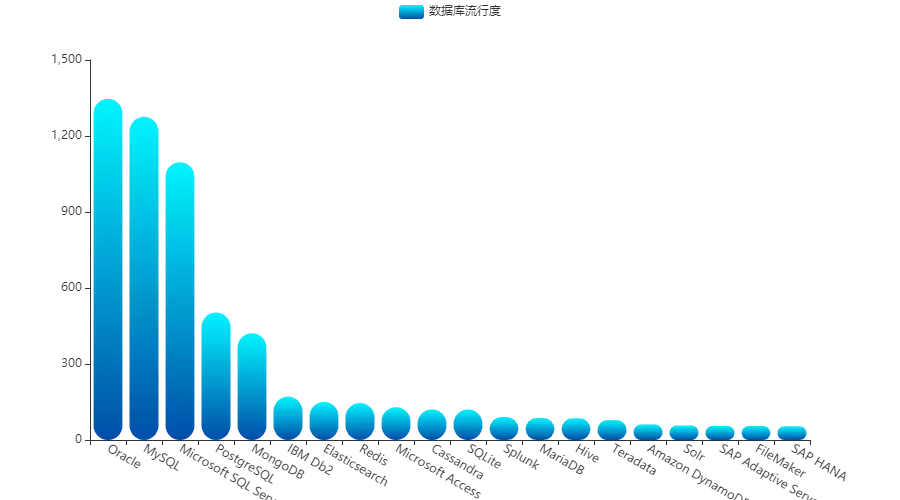
可以看出,关系型数据库还是当今的王者,流行度前四名都被它们所占据,而 Oracle 虽然连年表现不佳,为人诟病,但是依靠多年的积累,仍然牢牢把持着榜首的位置。
MySQL 似乎从来没有令用户失望,也是稳稳的占据二哥的位置。
而唯一挤进前五的非关系型数据库则是 MongoDB,在文档数据库领域,绝对是大哥大!
我们再通过一张散点图来感受下不同数据库之间的差距:
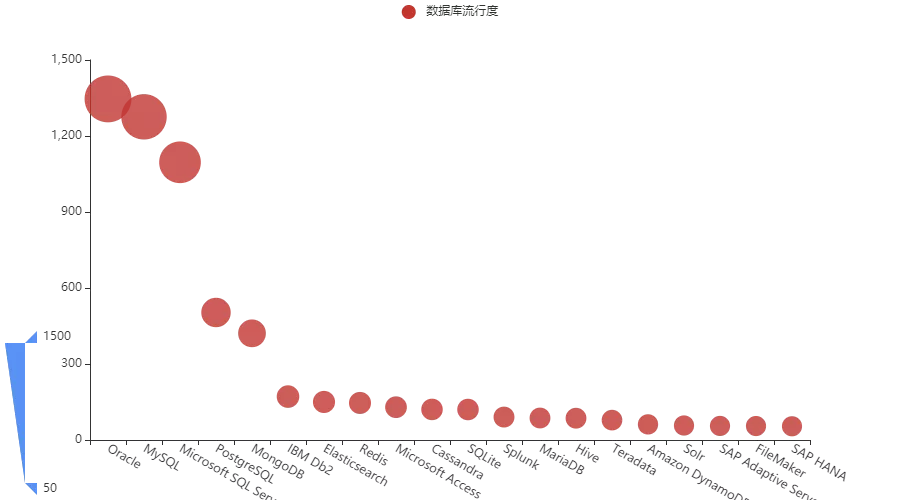
主流数据库榜单
我这里又选取了总榜中的前五名,再加上 key-value 数据库的代表 Redis 和搜索数据库的代表 ES 来作为对比对象。
先来看看它们在 2019 年的整体走势:
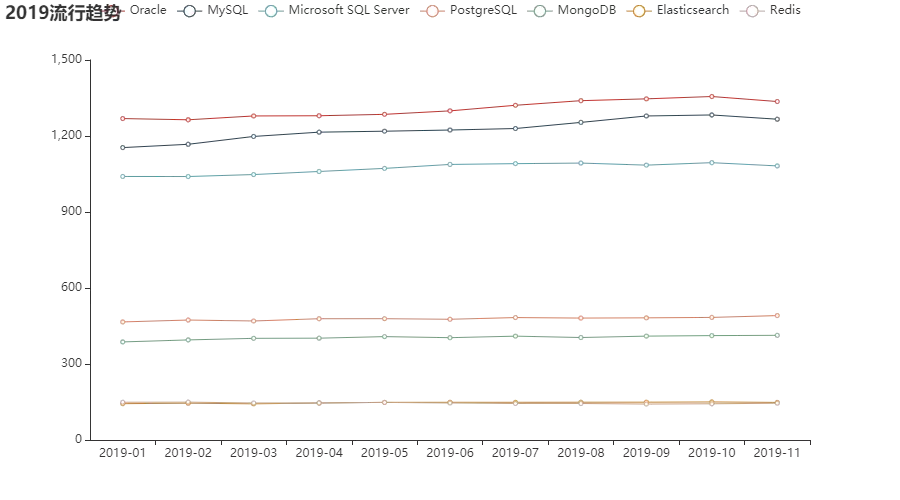
可以看到它们在 2019 年总体表现还是比较平稳的,其中榜首三强都是在年末出现了不同程度的下滑,而与之对应的则是 PG 数据库的增长了。
再来看下这七大数据库今年的增长率:
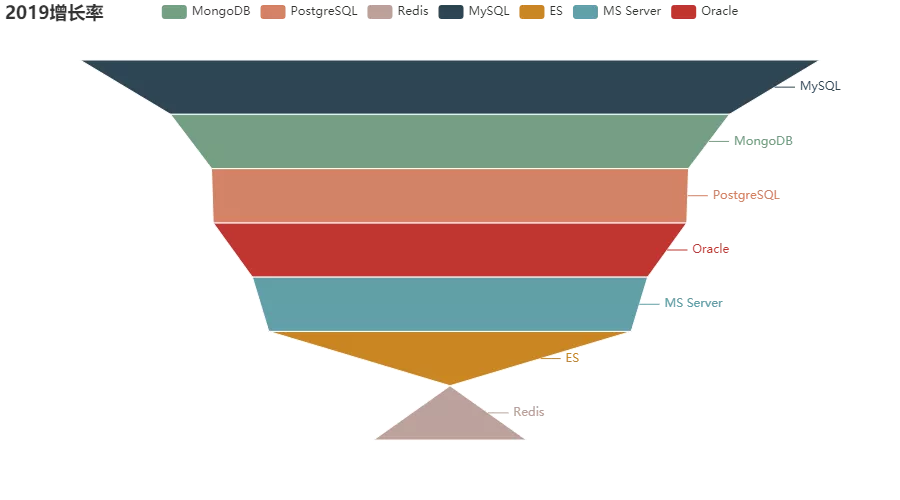
可以看到 MySQL 是增长率最高的数据库,而 Redis 在 2019 年则表现不佳,呈现了负增长的趋势。
下面我们再把时间拉长,看看从 2012 年到现在,各大数据库的表现情况:
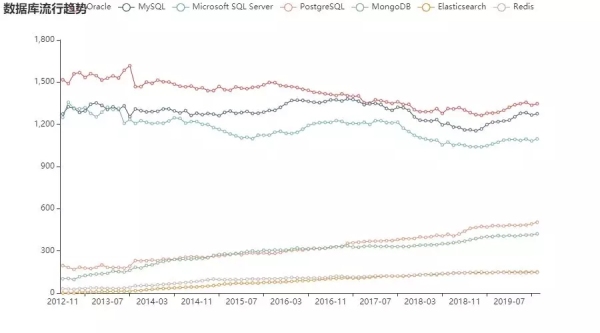
Oracle 和 MS Server 整体来看确实呈现下降的趋势,而 MySQL 则稍稍有些增长。
同时 PostgreSQL 增长比较明显,尤其是从 2017 年开始,流行度超越 MongoDB,相对应的,这个时间段也是榜首三大数据库的下滑期。
接下来再根据不同的数据库类型,来分别查看下各种类型数据库的流行趋势。
关系型数据库
对于关系型数据库,榜首四强实在太强:
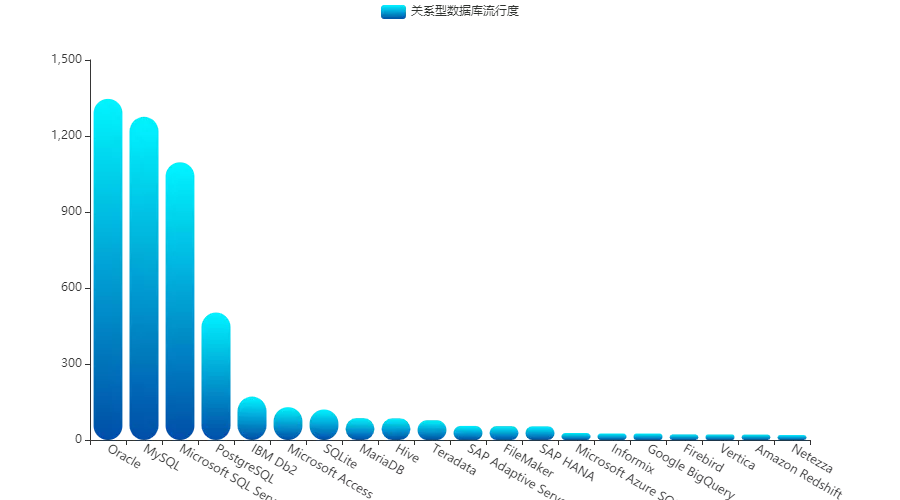
我们去除掉这四种数据库,来看看其他关系型数据库的历年走势:

可以看出,IBM 的 DB2 和微软的 Access 近年都有下滑的趋势,而作为 MySQL 的开源版 MariaDB,则呈现了很强的上升趋势,看来大家拥抱开源的信念不减呢!
Key-Value 数据库
再来看看 K-V 数据库,毫无疑问,近些年 Redis 风光无限,占据了大部分的市场份额。
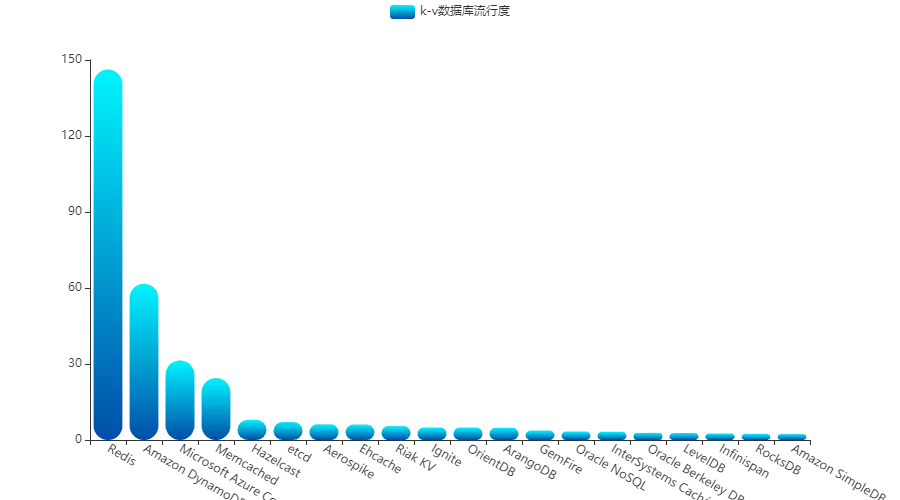
而曾经的王者 Memcached,则因为种种原因,流行度不断下滑:
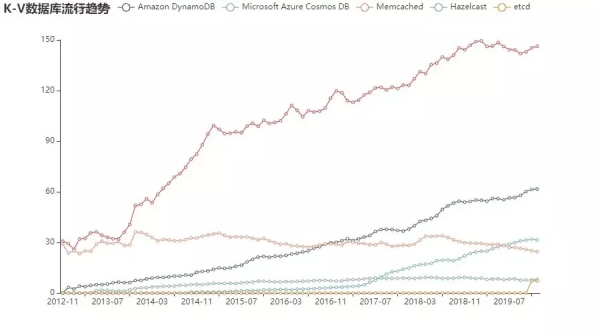
可以看到,2016 年为起点,随着云计算的风起云涌,亚马逊和微软的 K-V 数据库增长迅猛,而 Memcached 则逐渐衰落,但是 Redis 凭借其良好的表现,仍然一路高歌!
文档数据库
现在进入到文档数据库时间,毫无疑问 MongoDB 的地位无可动摇:
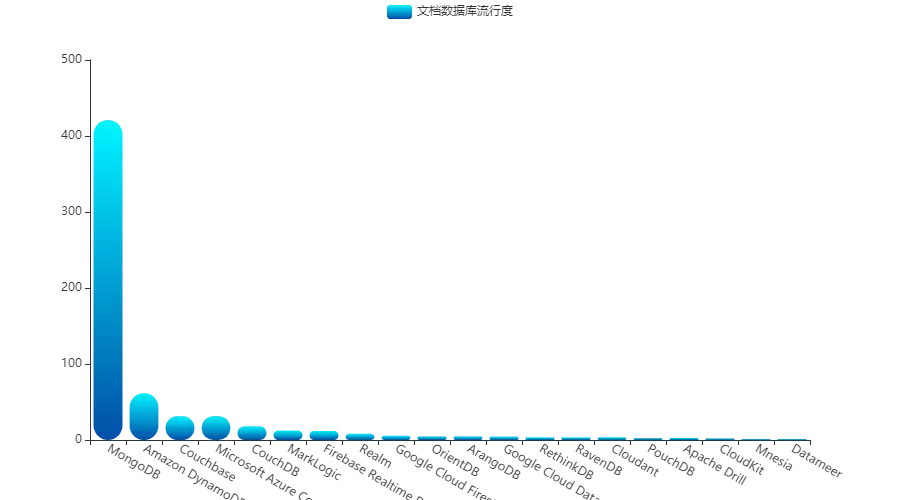
而亚马逊的 Amazon DynamoDB 数据库凭借着云服务的兴起,也成功占有一席之地!
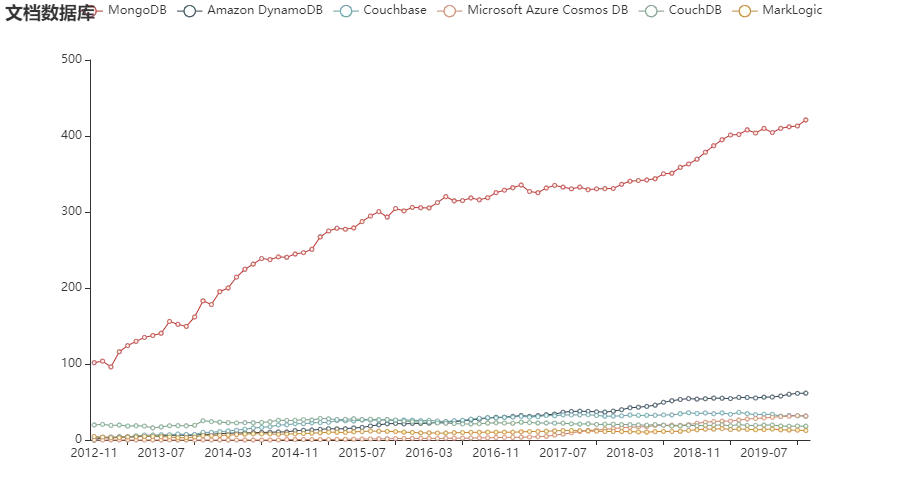
从历年流行度走势图中可以看出,MongoDB 在持续增长的路上,一骑绝尘了。
而 Amazon DynamoDB 则从 2017 年开始慢慢占据市场份额,拉开与其他文档数据库的差距。
时序数据库
时序数据库也有一个霸主,那就是 InfluxDB,不过整体来说,各方势力实力均衡!

Kdb、Prometheus 和 OpenTSDB 等都在各自擅长的领域发挥着不可替代的作用。
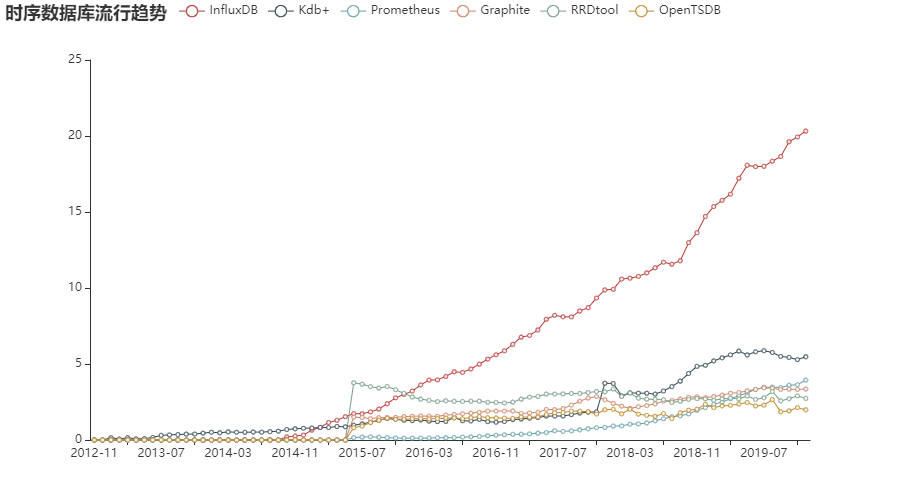
当然啦,InfluxDB 数据库就是那颗最耀眼的星,迅猛的发展趋势,让它成功杀出重围。
而 RRDtool 数据库却多少有些高开低走的味道,不知道什么时候能够看到它王者归来!
图数据库
下面我们再来看看图数据库,它在知识图谱领域是当仁不让的首选数据库类型,尤其是 Neo4j,就算你没有使用过,怎么也听说过它的大名吧!
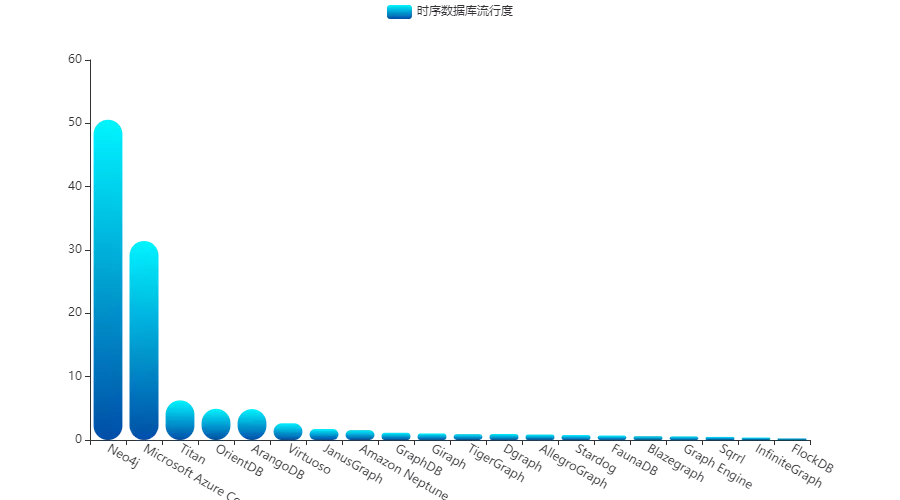
再来看看近些年的流行度走势呢:
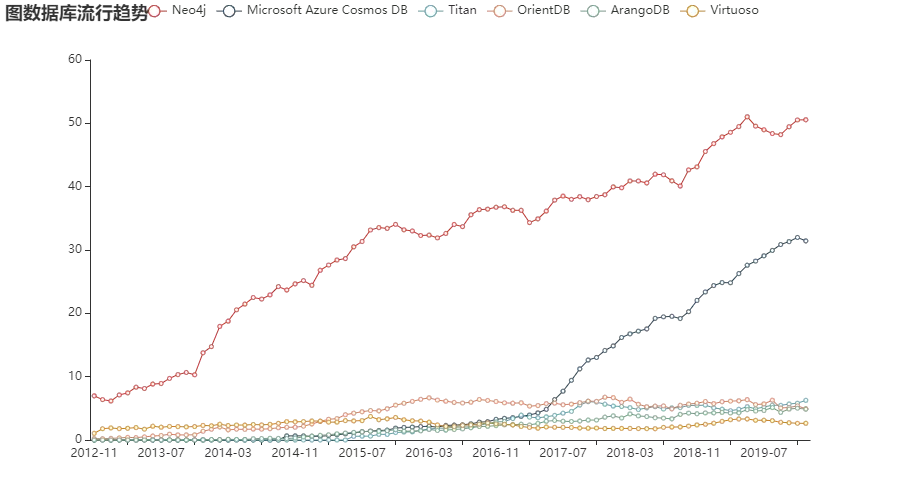
Neo4j 和 Microsoft Azure Cosmos DB 走势迅猛,看来在知识图谱兴起的时代,图数据库也要呈现二分天下的态势了。
搜索数据库
最后我们再来看看搜索数据库的情况:

没有一丝丝疑问,大火的 ES 成功占据榜首,之后就是 Splunk 和 Solr,这三位基本占据了搜索数据库的大部分市场。
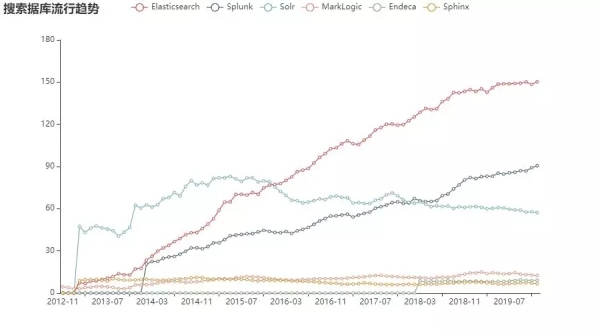
从历年走势中看出,Solr 有些扎心了,随着 ES 和 Splunk 的强势崛起,Solr 似乎慢慢归于平静了。
不过无论是 ES 的耀眼光芒还是 Splunk 的新贵登基,可以预见的是在未来的很长一段时间里,搜索数据库领域仍然会是它们的三足鼎立!
最后再通过一个视频,来看看不同类型数据库的流行度变化情况:
完整代码:
https://github.com/zhouwei713/data_analysis/tree/master/Annual_Ceremony/DB
作者:周萝卜
简介:Python 学习者。爱好爬虫、数据分析及可视化等,个人公众号《萝卜大杂烩》,期待与你相遇!

