【51CTO.com快译】在软件产品开发的生命周期中,不同的团队需要关注不同的API指标。无论是API产品经理、还是开发工程师,他们在进行API分析研究与报告时,都会自然而然地从自身的职能特点去考察各种关键性的API指标。下面让我们从团队角色出发,一起讨论那些需要关注的十三项API性能指标。

首先我们来看看一个典型的软件企业团队都有哪些不同的职能角色。
基础架构与开发运营
通过正确地分配有限的资源,确保服务器能够正常地运转,以供多个工程团队使用。
应用工程与平台
API开发人员负责根据业务逻辑,向API添加新的功能,并解决应用程序中的问题。他们交付的产品包括:API即服务(API as a Service),与合作伙伴的插件和集成,以及其他丰富的API。
产品管理
API产品经理负责通过API功能的路线图,确保构建出正确的API节点;并通过工程的时间和人员条件的约束,来平衡(内部或外部)用户的需求。
业务与增长
这是一个由市场营销和销售人员组成的,面向市场的团队。他们并不会专注API节点,而是会紧跟客户的兴趣点,以确保他们能够使用到已开发出的API,并从中发现新的销售机会。
基础架构API指标
此类指标主要是应用性能监视(Application Performance Monitoring,APM)工具(如:Datadog之类的基础架构监视公司的产品)所获取。它们主要关注如下方面:
1、正常运行时间(uptime)
正常运行时间是衡量服务可用性的一项最基本的指标,我们有时也称为“黄金标准”。许多企业都会在服务水平协议(SLA)中提及,或重点标注出各种与服务相关的“正常运行时间”标准。如下图所示,我们在某些术语表中常见的“三个九”或“四个九”等,就是用来衡量某个服务系统每年的正常运行时间、与宕机时间之间的关系。
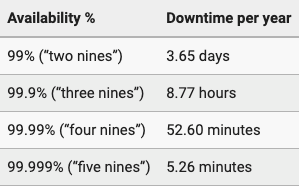
当然,从“四个九”提升到“五个九”,远比从“两个九”变成“三个九”要困难得多,这就是为什么除了关键性的(也是最昂贵的)服务之外,您在SLA中鲜少看到“五个九”的原因。话虽如此,我们仍然可以在减少某些服务的正常运行时间的同时,确保其在中断的极端情况下,不会影响到既定的服务处理。例如:Moesif(一个美国人工智能API服务平台)就被设计为即使其网站和仪表板出现完全中断的情况,也能够继续通过各种SDK收集数据。也就是说,SDK能够在本地排队收集的信息,而不会中断现有的应用。
正常运行时间通常是通过诸如Pingdom或 UptimeRobot的ping服务或综合测试来衡量的。您可以将探测的频率配置为每分钟之类的固定时间间隔,来探测特定节点的/health或/status,以获取诸如:数据备份等其他服务的基本连通性状态。您可以通过Statuspage.io之类的工具,将这些收集到的指标发布到目标网站上。例如:Moesif就使用了基于Lambda构建的开源状态页面(请参见:https://github.com/ks888/LambStatus)。
当然,我们还可以设置并使用一些被称为“综合测试”的复杂ping服务。例如:运行特定的一套测试序列,并判定响应负载中是否包含一定的数值。尽管综合测试可能无法代表用户真实的流量,但是这些调试性的API对于获悉系统的正常运行状态还是非常有意义的。值得说明的是:综合监控是由监控服务触发的一组预定义的API调用,能够检查目标API序列是否符合预期运行状态。
2、CPU使用率
CPU使用率也是非常经典的性能指标之一,它可以从某种程度上反应应用程序的响应能力。如果服务器CPU使用率较高,则可能意味着服务器或虚拟机已经过载,而且可能会带来诸如:大量自旋锁(spinlock)等应用程序的性能错误。
基础架构工程师可以使用CPU使用率(包括内存使用百分比),来规划资源,并衡量整体运行状况。某些类型的应用程序(例如高带宽的代理服务和API网关)本身就会比其他进程具有更高的CPU使用率,特别是在涉及到诸如视频编码、以及机器学习等大量浮点运算的工作负载时。
在本地调试API时,您可以通过Windows上的“任务管理器”(https://en.wikipedia.org/wiki/Task_Manager_(Windows) )或MacBook上的“Activity Monitor”,来轻松地查看系统和进程的CPU使用情况。但是在服务器上,如果您不想使用SSH或运行top命令,那么就需要用到各种APM工具了。通过APM提供的代理,您可以将其嵌入应用程序或服务器中,以捕获诸如CPU和内存使用率之类的指标。当然,您也可以通过执行其他特定功能的应用程序监控,例如:线程分析。
我们在查看CPU使用率时,应当主要关注的是每个虚拟CPU(即物理线程)的使用率。如果出现不平衡的情况,则可能意味着应用程序没有正确地执行进程,或者是线程池的大小配置不正确。
许多APM都能够让您使用不同的名称来标记应用程序,以方便实现汇总。例如:您可能希望对诸如:my-api-westus-vm0、my-api-westus-vm1、my-api-eastus-vm0等每一个VM指标进行分组,同时将它们汇总到一个名为my-API的标签之中。
3、内存使用
与CPU使用率类似,内存使用率也是衡量资源利用率的性能指标。较高的内存使用量可能表明服务器处于过载的状态,因此它往往与配置有关。
通常情况下,大数据查询、大流量处理、以及各种生产环境的数据库,都会消耗比CPU更多的内存。因此,为了减少每个VM在批处理查询时所花费的时间,我们应当分配更多的可用内存,以减少检查点(checkpointing),网络同步,以及对磁盘的分页。
我们在查看内存的使用情况时,还应该查看页面的错误数、以及I/O的操作数。常见的配置错误是:只为应用程序分配了一小部分的可用物理内存。这样就很可能会导致高页面的虚拟内存崩溃。
应用程序的API指标
4、每分钟请求数(RPM)
每分钟请求数(Requests per Minute,RPM)是我们在比较HTTP、或数据库服务器时经常使用的性能指标。由于服务器无法准确地计算出诸如:第三方服务在对数据库进行I/O操作时所引起的延迟,因此某些产品虽然会吹嘘自己拥有较高的RPM,但是您的团队仍然需要以效率为目标设法降低RPM。
通常情况下,您需要将具有多个API调用的某些业务功能,合并为更少的API调用,以减少RPM的数量。例如:您可以在单个请求中,批量处理多个请求,以确保自己具有灵活、实用的分页方案。
与RPM相关的术语包括:每秒请求数(Requests per Second,RPS)和每秒查询数(Queries per Second,QPS)。由于软件产品的RPM可能会在每周、甚至是一天中的每一小时都有所不同,因此您需要灵活地调整自己的API,以适应具体的峰谷值。
5、平均与最大延迟
在跟踪客户的体验时,API的延迟时间是一项非常重要的指标。虽然前文提到的CPU使用率之类的基础架构级指标的增加,可能并不会让用户及时感知到响应能力的下降,但是API的延迟肯定会。有时候,单独地跟踪延迟可能无法使您完全理解它为什么会增加。因此,我们需要通过跟踪API的各种变更,包括:新API版本的发布,新节点加入原有架构等方面,来找出导致延迟增加的根本原因。
由于宏观地检查总体延迟,可能会忽略真正有问题的慢速节点,因此我们需要按照路由、地理位置、以及细分字段来进行排查。例如:某个POST/checkout节点随着时间的推移而延迟加剧,这很有可能是由于某个未被正确索引的SQL表在不断增加所导致。但是,由于针对POST/checkout的调用数量非常少,因此该问题很容易被您的GET/items节点所掩盖,毕竟该节点的调用量远远超过了checkout节点。同理,如果您有用到GraphQL API,那么就需要查看每个GraphQL操作的平均延迟。
尽管许多开发与架构人员也会关注延迟问题,但是他们主要是通过检查一组VM的总体延迟,来确保VM不会过载,而不会深入地研究诸如每条路由等,针对应用程序的特定指标。因此,我们认为应用程序与工程人员更需要关注延迟的相关问题。
6、每分钟错误率
与RPM相似,“每分钟错误”(或简称错误率)是指每分钟产生的带有非200系列代码的API调用数量。通过衡量API的错误率、以及易错性,我们可以进一步了解正在发生的错误类型。例如:500系列错误意味着您的代码存在着问题,而400系列错误则意味着不当的API设计和文档。可见,我们在设计API时,使用适当的HTTP状态代码是非常重要的,具体请参见:https://www.restapitutorial.com/httpstatuscodes.html。
API产品指标
值得注意的是,我们在此所讨论的API,不仅仅是指与微服务和SOA相关的应用接口,也包括那些独立的产品。此类产品正在变得越来越普遍,尤其在与新的合作伙伴开辟调用通道的时候。
那些以API为产品驱动的团队,既需要检查诸如错误和延迟之类的指标,也需要了解API的使用方式,包括为何无法实现其预定的效果等方面。
7、API使用量的增长
对于许多产品经理来说,API的使用率是一项黄金标准,可以衡量API作为产品的转换效果。一个好的API产品不仅应该没有缺陷,而且有着与日俱增的实际使用量。通常情况下,我们可以月为单位衡量API使用量的增长。
8、API专门使用者
当然,一个月内某个API使用的增加量可能仅来自于某一个用户账号,因此我们需要衡量API的月活用户(Monthly Active Users,MAU)或是API的专门使用者(unique consumers)。此类指标可以让您获悉用户的“拉新”和使用量增长的整体状况。同时,许多API平台团队也会将API的MAU与其网站的MAU相关联,以获取完整的产品态势。
9、使用API的头部用户
对于一些专注于B2B业务的公司而言,了解自己的API产品有哪些头部用户是非常必要的。这些少数头部用户通常会为您的公司带来更多的收入和转发推荐,因此您可以据此来调用对应的节点,并对它们采取进一步的细分,以获悉其使用特定节点的频率,和使用时的体验。
10、API的使用与留存
您也许正在疑惑到底是应该在产品和工程上投入更多,还是在增长上烧钱?光看用户的留存与流失是无法给出清晰的参考依据。毕竟有些用户虽然觉得您的API不够友好,但是迫于已经订阅的年度合同,而无法马上退订,但是他们并不会积极地使用您所提供的API。因此,我们需要跟踪的是API作为一种产品,在用户侧的实际使用情况。
11、首次进入时间(TTFHW)
作为一项重要的KPI,首次进入时间(Time to First Hello World,TTFHW),不仅可以跟踪API产品的运行状况,而且可以跟踪开发者的总体体验(developer experience,DX)。
如果您的API是一个吸引第三方开发人员和合作伙伴来使用的开放平台,那么您需要确保他们在首次调用时,就能够顺利流畅运用您提供的API来开发应用。TTFHW主要衡量的是:从首次访问目标网页到通过您的API平台进行首次事务的MVP集成时间。该指标不但适用于API本身,也能考察您的营销效果、以及配套的文档和教程。
12、每种业务交易的API调用
尽管一般而言,各种产品和业务的指标往往是多多益善的,但每一种业务交易的调用次数却是越少越好。该指标直接反映了API的设计水平。如果新的用户需要通过三次不同的调用,才能将数据组合到一起的话,那么这可能意味着该API没有找到正确的节点。因此在设计API时,我们应当考虑到业务交易本身、以及用户想要达到的目标,而不仅仅是能够提供的功能和涉及到的节点。此外,您还可能需要对API采取灵活的过滤和分页操作,具体请参见:https://www.moesif.com/blog/technical/api-design/REST-API-Design-Filtering-Sorting-and-Pagination/?utm_source=dzone&utm_medium=paid&utm_campaign=placed%20article&utm_term=13%20api%20metrics。
13、SDK和版本的采用
许多API平台团队还可能需要维护大量的SDK和集成。与仅以iOS和Android为核心的移动端不同,您的平台上可能拥有十来个、甚至上百个SDK。因此,对它们进行持续维护往往既费时又费力。那么,您可以选择性地将一些关键性的功能部署到那些最受欢迎的SDK之中。同时,在弃用某些节点和功能时,您也需要询问那些头部用户的意见,以做出对于API或SDK的取舍,以及版本的权衡。
结论
对于任何从事API构建和使用的人员来说,跟踪正确的API指标是至关重要的。不同的团队成员对于不同的API指标有着不同的关注点,也更能够从自身专业的角度解决当前和潜在的性能问题。希望上述讨论能够给您和您的团队提供一定的帮助。
原文标题:13 API Metrics That Every Platform Team Should Be Tracking,作者:Derric Gilling

