写出整洁的代码,是每个程序员的追求。《clean code》指出,要想写出好的代码,首先得知道什么是肮脏代码、什么是整洁代码;然后通过大量的刻意练习,才能真正写出整洁的代码。

图片来自 Pexels
WTF/min 是衡量代码质量的唯一标准,Uncle Bob 在书中称糟糕的代码为沼泽(wading),这只突出了我们是糟糕代码的受害者。
国内有一个更适合的词汇:屎山,虽然不是很文雅但是更加客观,程序员既是受害者也是加害者。
对于什么是整洁的代码,书中给出了大师们的总结:
Bjarne Stroustrup:优雅且高效;直截了当;减少依赖;只做好一件事
Grady booch:简单直接
Dave thomas:可读,可维护,单元测试
Ron Jeffries:不要重复、单一职责,表达力(Expressiveness)
其中,我最喜欢的是表达力(Expressiveness)这个描述,这个词似乎道出了好代码的真谛:用简单直接的方式描绘出代码的功能,不多也不少。
命名的艺术
坦白的说,命名是一件困难的事情,要想出一个恰到好处的命名需要一番功夫,尤其我们的母语还不是编程语言所通用的英语。
不过这一切都是值得了,好的命名让你的代码更直观,更有表达力。好的命名应该有下面的特征:
①名副其实
好的变量名告诉你:是什么东西,为什么存在,该怎么使用,如果需要通过注释来解释变量,那么就先得不那么名副其实了。
下面是书中的一个示例代码,展示了命名对代码质量的提升:
# bad code def getItem(theList): ret = [] for x in theList: if x[0] == 4: ret.append(x) return ret # good code def getFlaggedCell(gameBoard): '''扫雷游戏,flagged: 翻转''' flaggedCells = [] for cell in gameBoard: if cell.IsFlagged(): flaggedCells.append(cell) return flaggedCells
②避免误导
不要挂羊头卖狗肉,不要覆盖惯用缩略语!
这里不得不吐槽前两天才看到的一份代码,居然使用了 l 作为变量名;而且,user 居然是一个 list(单复数都没学好!!)
③有意义的区分
代码是写给机器执行,也是给人阅读的,所以概念一定要有区分度:
# bad def copy(a_list, b_list): pass # good def copy(source, destination): pass
④使用读的出来的单词
如果名称读不出来,那么讨论的时候就会像个傻鸟。
⑤使用方便搜索的命名
名字长短应与其作用域大小相对应!
⑥避免思维映射
比如在代码中写一个 temp,那么读者就得每次看到这个单词的时候翻译成其真正的意义。
注释
有表达力的代码是无需注释的:
The proper use of comments is to compensate for our failure to express ourself in code.
注释的适当作用在于弥补我们用代码表达意图时遇到的失败,这听起来让人沮丧,但事实确实如此。
The truth is in the code,注释只是二手信息,二者的不同步或者不等价是注释的最大问题。
书中给出了一个非常形象的例子来展示,用代码来阐述,而非注释:
bad // check to see if the employee is eligible for full benefit if ((employee.flags & HOURLY_FLAG) && (employee.age > 65)) good if (employee.isEligibleForFullBenefits())
因此,当想要添加注释的时候,可以想想是否可以通过修改命名,或者修改函数(代码)的抽象层级来展示代码的意图。
当然,也不能因噎废食,书中指出了以下一些情况属于好的注释:
法务信息
对意图的注释,为什么要这么做
警示
TODO 注释
放大看似不合理之物的重要性
其中个人最赞同的是第 2 点和第 5 点,做什么很容易通过命名表达,但为什么要这么做则并不直观,特别涉及到专业知识、算法的时候。
另外,有些第一感觉“不那么优雅”的代码,也许有其特殊愿意,那么这样的代码就应该加上注释,说明为什么要这样,比如为了提升关键路径的性能,可能会牺牲部分代码的可读性。
最坏的注释就是过时或者错误的注释,这对于代码的维护者(也许就是几个月后的自己)是巨大的伤害,可惜除了 code review,并没有简单易行的方法来保证代码与注释的同步。
函数
①函数的单一职责
一个函数应该只做一件事,这件事应该能通过函数名就能清晰的展示。判断方法很简单:看看函数是否还能再拆出一个函数。
函数要么做什么 do_sth,要么查询什么 query_sth。最恶心的就是函数名表示只会 query_sth,但事实上却会 do_sth,这使得函数产生了副作用。
比如书中的例子:
public class UserValidator { private Cryptographer cryptographer; public boolean checkPassword(String userName, String password) { User user = UserGateway.findByName(userName); if (user != User.NULL) { String codedPhrase = user.getPhraseEncodedByPassword(); String phrase = cryptographer.decrypt(codedPhrase, password); if ("Valid Password".equals(phrase)) { Session.initialize(); return true; } } return false; } }②函数的抽象层级
每个函数一个抽象层次,函数中的语句都要在同一个抽象层级,不同的抽象层级不能放在一起。
比如我们想把大象放进冰箱,应该是这个样子的:
def pushElephantIntoRefrige(): openRefrige() pushElephant() closeRefrige()
函数里面的三句代码在同一个层级(高度)描述了要完成把大象放进冰箱这件事顺序相关的三个步骤。
显然,pushElephant 这个步骤又可能包含很多子步骤,但是在 pushElephantIntoRefrige 这个层级,是无需知道太多细节的。
当我们想通过阅读代码的方式来了解一个新的项目时,一般都是采取广度优先的策略,自上而下的阅读代码,先了解整体结构,然后再深入感兴趣的细节。
如果没有对实现细节进行良好的抽象(并凝练出一个名副其实的函数),那么阅读者就容易迷失在细节的汪洋里。
某种程度看来,这个跟金字塔原理也很像:
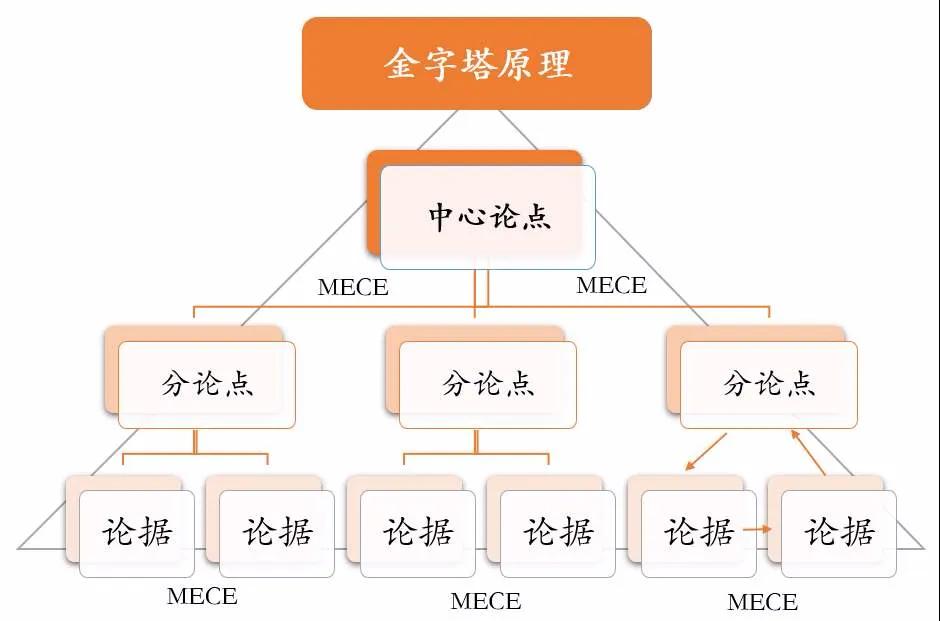
每一个层级都是为了论证其上一层级的观点,同时也需要下一层级的支持;同一层级之间的多个论点又需要以某种逻辑关系排序。
pushElephantIntoRefrige 就是中心论点,需要多个子步骤的支持,同时这些子步骤之间也有逻辑先后顺序。
③函数参数
函数的参数越多,组合出的输入情况就愈多,需要的测试用例也就越多,也就越容易出问题。
输出参数相比返回值难以理解,这点深有同感,输出参数实在是很不直观。从函数调用者的角度,一眼就能看出返回值,而很难识别输出参数。输出参数通常逼迫调用者去检查函数签名,这个实在不友好。
向函数传入Boolean(书中称之为 Flag Argument)通常不是好主意。尤其是传入True or False后的行为并不是一件事情的两面,而是两件不同的事情时。
这很明显违背了函数的单一职责约束,解决办法很简单,那就是用两个函数。Dont repear yourself。
在函数这个层级,是最容易、最直观实现复用的,很多 IDE 也难帮助我们讲一段代码重构出一个函数。
不过在实践中,也会出现这样一种情况:一段代码在多个方法中都有使用,但是又不完全一样,如果抽象成一个通用函数,那么就需要加参数、加 if else 区别。这样就有点尴尬,貌似可以重构,但又不是很完美。
造成上述问题的某种情况是因为,这段代码也违背了单一职责原则,做了不只一件事情,这才导致不好复用,解决办法是进行方法的细分,才能更好复用。
也可以考虑 template method 来处理差异的部分。
测试
非常惭愧的是,在我经历的项目中,测试(尤其是单元测试)一直都没有得到足够的重视,也没有试行过 TDD。正因为缺失,才更感良好测试的珍贵。
我们常说,好的代码需要有可读性、可维护性、可扩展性,好的代码、架构需要不停的重构、迭代,但自动化测试是保证这一切的基础,没有高覆盖率的、自动化的单元测试、回归测试,谁都不敢去修改代码,只能任其腐烂。
即使针对核心模块写了单元测试,一般也很随意,认为这只是测试代码,配不上生产代码的地位,以为只要能跑通就行了。
这就导致测试代码的可读性、可维护性非常差,然后导致测试代码很难跟随生产代码一起更新、演化,最后导致测试代码失效。所以说,脏测试等同于没测试。
因此,测试代码的三要素:
可读性
可读性
可读性
对于测试的原则、准则如下:
没有测试之前不要写任何功能代码
只编写恰好能够体现一个失败情况的测试代码
只编写恰好能通过测试的功能代码
测试的 FIRST 准则:
快速(Fast)测试应该够快,尽量自动化。
独立(Independent)测试应该应该独立。不要相互依赖
可重复(Repeatable)测试应该在任何环境上都能重复通过。
自我验证(Self-Validating)测试应该有 bool 输出。不要通过查看日志这种低效率方式来判断测试是否通过。
及时(Timely)测试应该及时编写,在其对应的生产代码之前编写。

