这篇文章将通过一个真实的线上事故,系统性地介绍:在微服务架构下,该如何正确理解并设置 RPC 接口的超时时间,让大家在开发服务端接口时有更全局的视野。

图片来自 Pexels
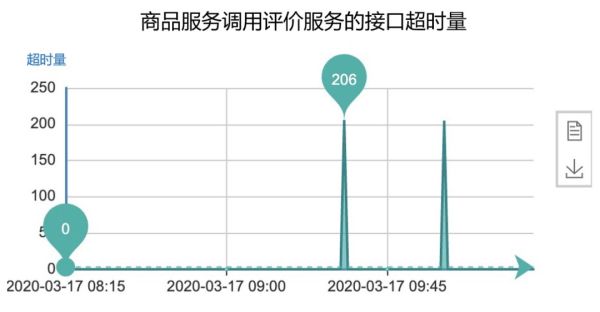
上面这张监控图,对于服务端的研发同学来说再熟悉不过了。在日常的系统维护中,“服务超时”应该属于监控报警最多的一类问题。
尤其在微服务架构下,一次请求可能要经过一条很长的链路,跨多个服务调用后才能返回结果。
当服务超时发生时,研发同学往往要抽丝剥茧般去分析自身系统的性能以及依赖服务的性能,这也是为什么服务超时相对于服务出错和服务调用量异常更难调查的原因。
本篇文章将分成以下四个部分:
从一次 RPC 接口超时引发的线上事故说起
超时的实现原理是什么?
设置超时时间到底是为了解决什么问题?
应该如何合理的设置超时时间?
从一次 RPC 接口超时引发的线上事故说起
事故发生在电商 APP 的首页推荐模块,某天中午突然收到用户反馈:APP 首页除了 banner 图和导航区域,下方的推荐模块变成空白页了(推荐模块占到首页 2/3 的空间,是根据用户兴趣由算法实时推荐的商品 list)。
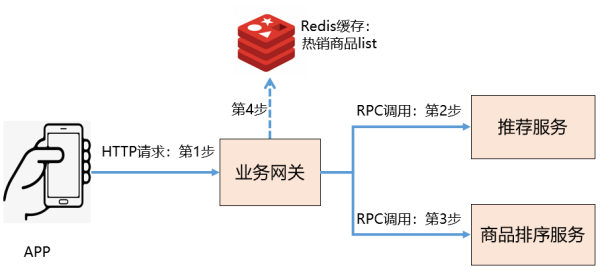
上面的业务场景可以借助上图的调用链来理解:
APP 端发起一个 HTTP 请求到业务网关。
业务网关 RPC 调用推荐服务,获取推荐商品 list。
如果第 2 步调用失败,则服务降级,改成 RPC 调用商品排序服务,获取热销商品 list 进行托底。
如果第 3 步调用失败,则再次降级,直接获取 Redis 缓存中的热销商品 list。
粗看起来,两个依赖服务的降级策略都考虑进去了,理论上就算推荐服务或者商品排序服务全部挂掉,服务端都应该可以返回数据给 APP 端。
但是 APP 端的推荐模块确实出现空白了,降级策略可能并未生效,下面详细说下定位过程。
问题定位过程
第 1 步:APP 端通过抓包发现:HTTP 请求存在接口超时(超时时间设置的是 5 秒)。
第 2 步:业务网关通过日志发现:调用推荐服务的 RPC 接口出现了大面积超时(超时时间设置的是 3 秒)。
错误信息如下:

第 3 步:推荐服务通过日志发现:Dubbo 的线程池耗尽。
错误信息如下:

通过以上 3 步,基本就定位到了问题出现在推荐服务,后来进一步调查得出:是因为推荐服务依赖的 Redis 集群不可用导致了超时,进而导致线程池耗尽。
详细原因这里不作展开,跟本文要讨论的主题相关性不大。
降级策略未生效的原因分析
下面再接着分析下:当推荐服务调用失败时,为什么业务网关的降级策略没有生效呢?理论上来说,不应该降级去调用商品排序服务进行托底吗?
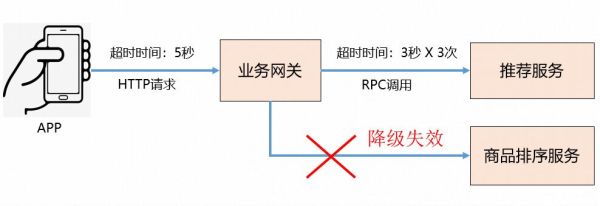
最终跟踪分析找到了根本原因:APP 端调用业务网关的超时时间是 5 秒,业务网关调用推荐服务的超时时间是 3 秒,同时还设置了 3 次超时重试。
这样当推荐服务调用失败进行第 2 次重试时,HTTP 请求就已经超时了,因此业务网关的所有降级策略都不会生效。
下面是更加直观的示意图:
解决方案
解决方案如下:
将业务网关调用推荐服务的超时时间改成了 800ms(推荐服务的 TP99 大约为 540ms),超时重试次数改成了 2 次。
将业务网关调用商品排序服务的超时时间改成了 600ms(商品排序服务的 TP99 大约为 400ms),超时重试次数也改成了 2 次。
关于超时时间和重试次数的设置,需要考虑整个调用链中所有依赖服务的耗时、各个服务是否是核心服务等很多因素。这里先不作展开,后文会详细介绍具体方法。
超时的实现原理是什么?
只有了解了 RPC 框架的超时实现原理,才能更好地去设置它。不论是 Dubbo、Spring Cloud 或者大厂自研的微服务框架(比如京东的 JSF),超时的实现原理基本类似。
下面以 Dubbo 2.8.4 版本的源码为例来看下具体实现。熟悉 Dubbo 的同学都知道,可在两个地方配置超时时间:分别是 Provider(服务端,服务提供方)和 Consumer(消费端,服务调用方)。
服务端的超时配置是消费端的缺省配置,也就是说只要服务端设置了超时时间,则所有消费端都无需设置,可通过注册中心传递给消费端。
这样:一方面简化了配置,另一方面因为服务端更清楚自己的接口性能,所以交给服务端进行设置也算合理。
Dubbo 支持非常细粒度的超时设置,包括:方法级别、接口级别和全局。如果各个级别同时配置了,优先级为:消费端方法级>服务端方法级>消费端接口级>服务端接口级>消费端全局>服务端全局。
通过源码,我们先看下服务端的超时处理逻辑:
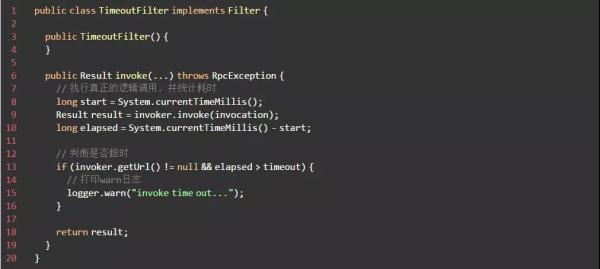
可以看到,服务端即使超时,也只是打印了一个 warn 日志。因此,服务端的超时设置并不会影响实际的调用过程,就算超时也会执行完整个处理逻辑。
再来看下消费端的超时处理逻辑:
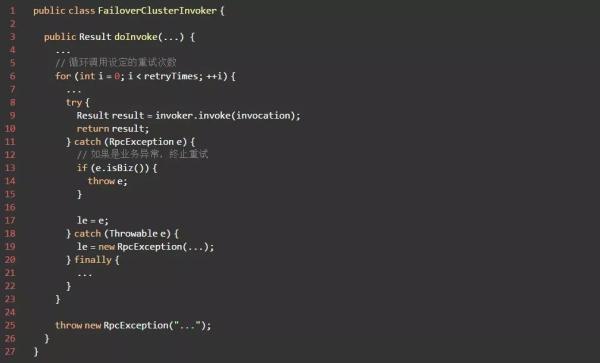
FailoverCluster 是集群容错的缺省模式,当调用失败后会切换成调用其他服务器。
再看下 doInvoke 方法,当调用失败时,会先判断是否是业务异常,如果是则终止重试,否则会一直重试直到达到重试次数。
继续跟踪 Invoker 的 Invoke 方法,可以看到在请求发出后通过 Future 的 get 方法获取结果。
源码如下:

进入方法后开始计时,如果在设定的超时时间内没有获得返回结果,则抛出 TimeoutException。
因此,消费端的超时逻辑同时受到超时时间和超时次数两个参数的控制,像网络异常、响应超时等都会一直重试,直到达到重试次数。
设置超时时间是为了解决什么问题?
RPC 框架的超时重试机制到底是为了解决什么问题呢?从微服务架构这个宏观角度来说,它是为了确保服务链路的稳定性,提供了一种框架级的容错能力。
微观上如何理解呢?可以从下面几个具体 case 来看:
①Consumer 调用 Provider,如果不设置超时时间,则 Consumer 的响应时间肯定会大于 Provider 的响应时间。
当 Provider 性能变差时,Consumer 的性能也会受到影响,因为它必须无限期地等待 Provider 的返回。
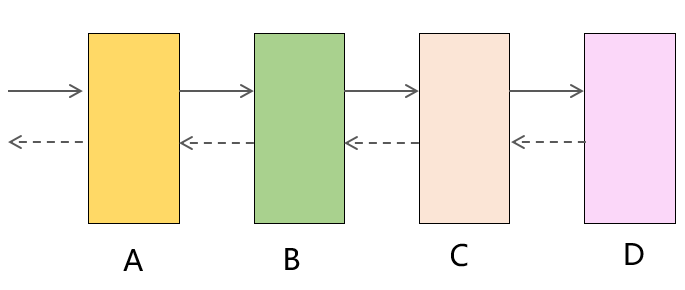
假如整个调用链路经过了 A、B、C、D 多个服务,只要 D 的性能变差,就会自下而上影响到 A、B、C,最终造成整个链路超时甚至瘫痪,因此设置超时时间是非常有必要的。
②假设 Consumer 是核心的商品服务,Provider 是非核心的评论服务,当评价服务出现性能问题时,商品服务可以接受不返回评价信息,从而保证能继续对外提供服务。
这样情况下,就必须设置一个超时时间,当评价服务超过这个阈值时,商品服务不用继续等待。
③Provider 很有可能是因为某个瞬间的网络抖动或者机器高负载引起的超时,如果超时后直接放弃,某些场景会造成业务损失(比如库存接口超时会导致下单失败)。
因此,对于这种临时性的服务抖动,如果在超时后重试一下是可以挽救的,所以有必要通过重试机制来解决。
但是引入超时重试机制后,并非一切就完美了。它同样会带来副作用,这些是开发 RPC 接口必须要考虑,同时也是最容易忽视的问题:
①重复请求:有可能 Provider 执行完了,但是因为网络抖动 Consumer 认为超时了,这种情况下重试机制就会导致重复请求,从而带来脏数据问题,因此服务端必须考虑接口的幂等性。
②降低 Consumer 的负载能力:如果 Provider 并不是临时性的抖动,而是确实存在性能问题,这样重试多次也是没法成功的,反而会使得 Consumer 的平均响应时间变长。
比如正常情况下 Provider 的平均响应时间是 1s,Consumer 将超时时间设置成 1.5s,重试次数设置为 2 次。
这样单次请求将耗时 3s,Consumer 的整体负载就会被拉下来,如果 Consumer 是一个高 QPS 的服务,还有可能引起连锁反应造成雪崩。
③爆炸式的重试风暴:假如一条调用链路经过了 4 个服务,最底层的服务 D 出现超时,这样上游服务都将发起重试。
假设重试次数都设置的 3 次,那么 B 将面临正常情况下 3 倍的负载量,C 是 9 倍,D 是 27 倍,整个服务集群可能因此雪崩。
应该如何合理的设置超时时间?
理解了 RPC 框架的超时实现原理和可能引入的副作用后,可以按照下面的方法进行超时设置:
设置调用方的超时时间之前,先了解清楚依赖服务的 TP99 响应时间是多少(如果依赖服务性能波动大,也可以看 TP95),调用方的超时时间可以在此基础上加 50%。
如果 RPC 框架支持多粒度的超时设置,则:全局超时时间应该要略大于接口级别最长的耗时时间,每个接口的超时时间应该要略大于方法级别最长的耗时时间,每个方法的超时时间应该要略大于实际的方法执行时间。
区分是可重试服务还是不可重试服务,如果接口没实现幂等则不允许设置重试次数。注意:读接口是天然幂等的,写接口则可以使用业务单据 ID 或者在调用方生成唯一 ID 传递给服务端,通过此 ID 进行防重避免引入脏数据。
如果 RPC 框架支持服务端的超时设置,同样基于前面3条规则依次进行设置,这样能避免客户端不设置的情况下配置是合理的,减少隐患。
如果从业务角度来看,服务可用性要求不用那么高(比如偏内部的应用系统),则可以不用设置超时重试次数,直接人工重试即可,这样能减少接口实现的复杂度,反而更利于后期维护。
重试次数设置越大,服务可用性越高,业务损失也能进一步降低,但是性能隐患也会更大,这个需要综合考虑设置成几次(一般是 2 次,最多 3 次)。
如果调用方是高 QPS 服务,则必须考虑服务方超时情况下的降级和熔断策略。(比如超过 10% 的请求出错,则停止重试机制直接熔断,改成调用其他服务、异步 MQ 机制、或者使用调用方的缓存数据)
总结
最后,再简单总结下:RPC 接口的超时设置看似简单,实际上有很大学问。不仅涉及到很多技术层面的问题(比如接口幂等、服务降级和熔断、性能评估和优化),同时还需要从业务角度评估必要性。
知其然知其所以然,希望这些知识能让你在开发 RPC 接口时,有更全局的视野。

