
去年8月,在世界人工智能大会上,微软宣布由微软亚洲研究院研发的麻将AI系统Suphx成为首个在国际知名专业麻将平台“天凤”上荣升十段的AI系统,其实力超越该平台公开房间顶级人类选手的平均水平。
近日,微软公布了Suphx相关论文,并向媒体解读了Suphx的创新技术和相关领域应用进展。
论文链接:
https://arxiv.org/abs/2003.13590
自发布以来,他们将整个Suphx系统架构进行了重新优化,另一方面他们在算法上也做了很多改进,使Suphx的训练更为高效。
Suphx研究人员微软亚洲研究首席研究员秦涛、高级研究工程师李俊杰介绍,为加快强化学习的速度而引入的“先知教练”技术,用“先知”来引导正常 AI的训练,这两个模型不停的相互学习,其学习效率会更高,即在一开始训练的时候需要获取到部分完美信息。
一个问题是,如果要将先知技术迁移到其他实际的非完美信息应用中,是否也能提供类似Suphx那样的训练条件?
研究人员告诉AI科技大本营(ID:rgznai100),他们在金融行业做的一些尝试,初步效果很不错。“如果今天A股已经闭盘了,那么我们就知道了今天所有的股票信息,当我们回头看昨天做决策的时候,假设知道了今天股票的信息,那这就成了完美信息。那么在这种情况下就可以利用完美信息,把模型训练得更好。正如在麻将AI系统中,通过完美信息可以得到一个非常强大的Teacher Model,这样Student Model也会学的很好。”
此外,他们在物流行业、机器翻译领域也做了一些初步尝试。研究人员称,在机器翻译领域中,完美信息也会很有帮助,“如果知道这句话的上下文,可能它翻译得更好,即完美信息,但实际中不一定每句话都知道它的上下文,但是训练中拿到的完美信息可以帮助将翻译做得更好。”
当然,Suphx还在不断进化,研究人员介绍了其下一阶段的系统迭代计划:
Suphx现在很多时候还是用了高手的数据训练一个模型,然后再到强化学习,但是面对不同的麻将平台及规则,不一定所有的平台都能拿到人类的数据,在这种情况下怎么能不用人的数据直接从0开始,这是他们目前所在做的。
麻将一个很独特的挑战在于其随机因素很多,这对训练和测试都会带来很大影响。比如,测试的时候基本会跑100万场游戏,才能明确比较谁更厉害,这就跟围棋五局三胜的规则很不一样,这种情况下如何加快地完成对弈,得出可信赖的结果,也是他们现在正研究的问题。
另外,他们也在考虑Suphx能针对性地面对不同对手采取一些自适应策略。
以下为微软Suphx团队对的详细技术解读,内容源自微软研究院AI头条:
麻将 AI 面临的挑战
麻将 AI 系统 Suphx 主要基于深度强化学习技术。尽管深度强化学习在一系列游戏 AI 中取得了巨大的成功,但想要将其直接应用在麻将 AI 上殊为不易,面临着若干挑战。
挑战一:麻将的计分规则通常都非常复杂,在如天凤平台等竞技麻将中,计分规则更加复杂。
首先,一轮麻将游戏通常有8局甚至更多,每一局结束后四位玩家都会有这一局的得分(可能为正,可能为负)。当一轮游戏的所有8局(或更多局)都结束后,四位玩家按照所有局的累计得分排名,计算这一轮游戏的点数奖励。在天凤平台上,排在一二名的玩家会得到一定数目的点数,排在第三位的玩家点数不变,排在第四位的玩家会被扣去一定数目的点数 。一位玩家的点数会随着他玩的游戏的增多而变化,当玩家的点数增加到一定程度时会被提高段位,而当玩家的点数扣到0时则会被降低一个段位。因此,为了提高段位,玩家需要尽量多的排在第一位或者第二位,尽量避免被排在第四位。
由于一轮游戏的最终点数是由多局的累计得分决定,所以高手可能会策略性地输掉一些局。例如,如果一位玩家已经在前面7局大比分领先,那么他可能会故意输掉第8局让排在第三或四位的玩家赢得此局,从而确保自己的总分排在第一,最终获得这一轮游戏的最大点数。也就是说,某一局的输赢并不能直接代表玩家打的好不好,所以我们并不能直接使用每局的得分来作为强化学习的奖励反馈信号。
其次,天凤平台上每一轮游戏的计分规则都需要根据赢家手里的牌型来计算得分,牌型有非常多的可能,例如清一色、混一色、门清等等,不同牌型的得分会相差很大。这样的计分规则比象棋、围棋等游戏要复杂得多。麻将高手需要谨慎选择牌型,以在胡牌的概率和胡牌的得分上进行平衡,从而取得第一、二位或者摆脱第四位。
挑战二:从博弈论的角度来看,麻将是多人非完美信息博弈。麻将一共有136张牌,每一位玩家只能看到很少的牌,包括自己的13张手牌和所有人打出来的牌,更多的牌是看不到,包括另外三位玩家的手牌以及墙牌。面对如此多的隐藏未知信息,麻将玩家很难仅根据自己的手牌做出一个很好的决策。
挑战三:麻将除了计分规则复杂之外,打法也比较复杂,需要考虑多种决策类型,例如,除了正常的摸牌、打牌之外,还要经常决定是否吃牌、碰牌、杠牌、立直以及是否胡牌。任意一位玩家的吃碰杠以及胡牌都会改变摸牌的顺序,因此我们很难为麻将构建一棵规则的博弈树(game tree)。即使我们去构建一棵博弈树,那么这棵博弈树也会非常庞大,并且有不计其数的分支,导致以前一些很好的方法,如蒙特卡洛树搜索(MCTS )、蒙特卡洛反事实遗憾最小化(MCCFR )算法等都无法直接被应用。

Suphx 的决策流程及模型架构
Suphx 的打牌策略包含5个需要训练的模型,以应对麻将复杂的决策类型——丢牌模型、立直模型、吃牌模型、碰牌模型以及杠牌模型。另外 Suphx 还有一个基于规则的赢牌模型决定在可以赢牌的时候要不要赢牌。
Suphx 的具体决策流程如下图所示:
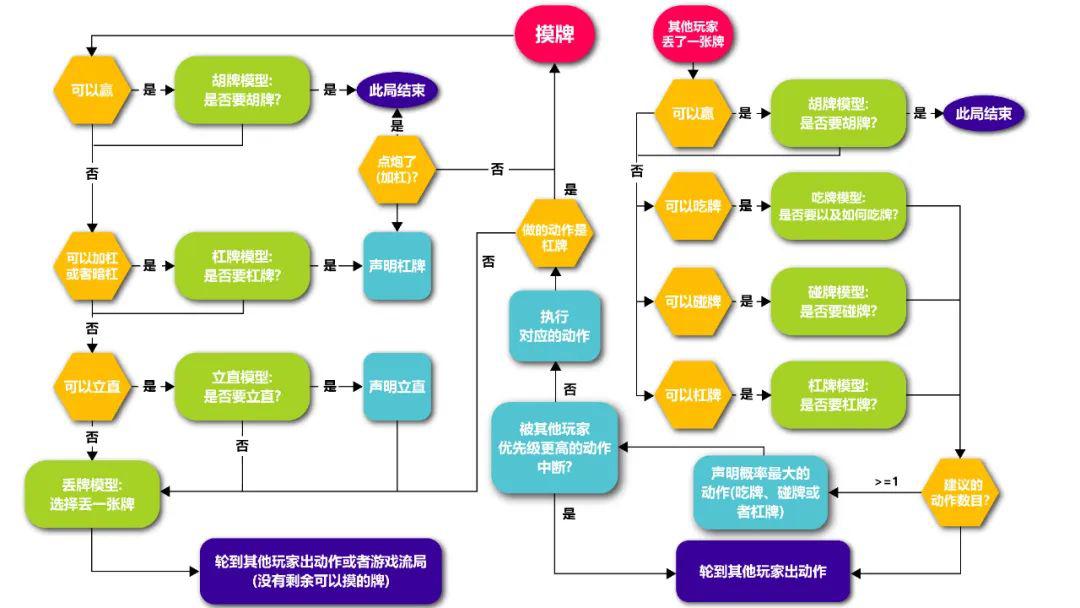
图2:Suphx 决策流程
Suphx 的5个模型都基于深度残差卷积神经网络,它们的大体结构(如图3、图4所示)相似,主要不同在于输入的维度和输出的维度。其中丢牌模型输出有34个节点,代表丢34张牌中任何一张牌的概率,其他的4个模型输出层只有2个节点,代表是否立直、吃牌、碰牌、杠牌的概率。

图3:丢牌模型结构

图4:立直、吃牌、碰牌、杠牌模型结构
这些模型的输入包含了两大类信息:
1. 当前可观测的信息,例如玩家自己的手牌、公开牌(包括丢出来的牌、碰的牌、明杠的牌),以及每个玩家的累计得分、座位、段位等等。
2. 对将来进行预测的信息,比如打某张牌还需要拿几张牌才能胡牌、能够赢多少分、胡牌概率有多大,等等。
需要指出的是,卷积神经网络 CNN 比较适合处理图像数据,但是麻将本身并不是天然的图像数据,因此我们需要对麻将的这些信息进行编码,使得 CNN 能够进行处理。图5展示了我们用一个4x34的矩阵来编码玩家的手牌。
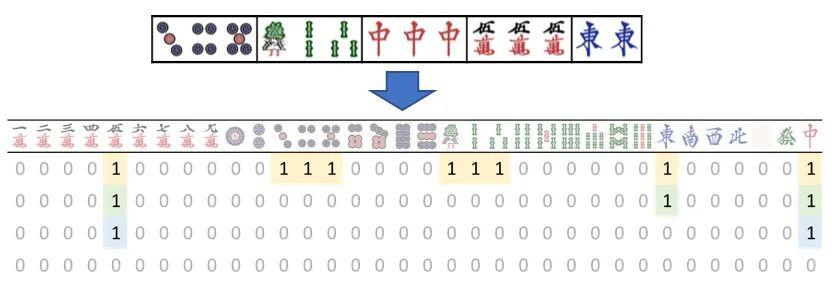
图5:手牌信息的矩阵表达
实际上,在 Suphx 研发的初期,我们采用了决策树算法 LightGBM,其在监督学习模仿人类玩家的行为上表现的不错,但是不适合强化学习,因此后来我们转而使用 CNN。
Suphx 训练算法
Suphx 训练过程分为三个主要步骤:首先使用来自天凤平台的高手打牌记录,通过监督学习来训练这5个模型,然后使用自我博弈强化学习以及我们设计的两个技术解决麻将本身的独特性所带来的挑战,最后我们在实战时采用在线策略自适应算法来进一步提高 Suphx 的能力。
下面我们将重点介绍 Suphx 学习算法中的一些关键环节:
分布式强化学习
Suphx 的整个训练过程十分复杂,需要多 GPU 和多 CPU 协同,因此我们采用了分布式架构(图6所示)。架构包括一个参数服务器以及多个自我博弈节点,每个节点里包含了多个麻将的模拟器以及多个推理引擎来进行多个策略之间的博弈(即打麻将)。每个自我博弈节点定期将打牌的记录发送给参数服务器,参数服务器会利用这些打牌记录来训练提高当前策略。每过一段时间,自我博弈节点就会从参数服务器拿回最新的策略,用来进行下一阶段的自我博弈。
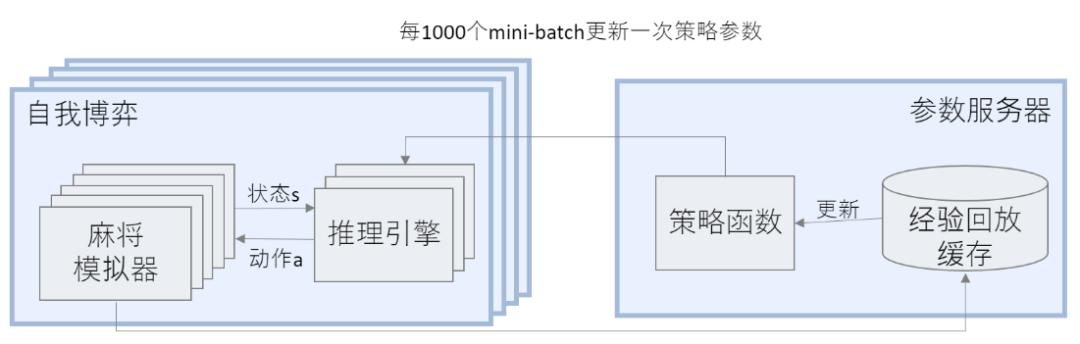
图6:分布式训练
我们发现,强化学习训练对策略的熵很敏感。如果熵太小,强化学习训练收敛速度快,自我博弈并不能显著提高策略;如果熵太大,强化学习训练就会变得不稳定,训练过程中的策略变化会很剧烈。所以,我们对强化学习训练过程中的策略熵进行了正则化处理,要求熵既不能太大又不能太小。
全局奖励预测
如前文所述,麻将的计分规则很复杂——玩家每局有得分,一轮游戏根据多局累计分数的排名计算点数。然而,无论是每局得分还是一轮游戏的最终点数都不适合用来做强化学习训练的反馈信号。
由于一轮游戏中有多局,以一轮游戏结束的最终奖励点数作为反馈信号不能区分打得好的局和打得差的局。因此,我们需要对每局都单独提供强化学习的训练信号。
然而,即使每局分数都是单独计算的,也未必能反映出一局打的好坏,特别是对于顶级职业选手来说。例如,在一轮游戏的最后一两局中,累计得分排位第一的选手在累计分数领先较大的情况下,通常会变得比较保守,会有意识地让排位第三或第四的选手赢下这一局,不让排第二位的玩家赢,这样就可以稳稳地保住总排位第一。也就是说,某一局得分为负不一定意味着策略不好。
因此,为了给强化学习训练提供有效的信号,我们需要将最终的游戏奖励适当地归因到每一轮的游戏中。为此,我们引入了一个全局奖励预测器,它可以基于本局的信息和之前的所有局信息预测出最终的游戏奖励。在 Suphx 中,奖励预测器是一个递归神经网络 (GRU),如图7所示。
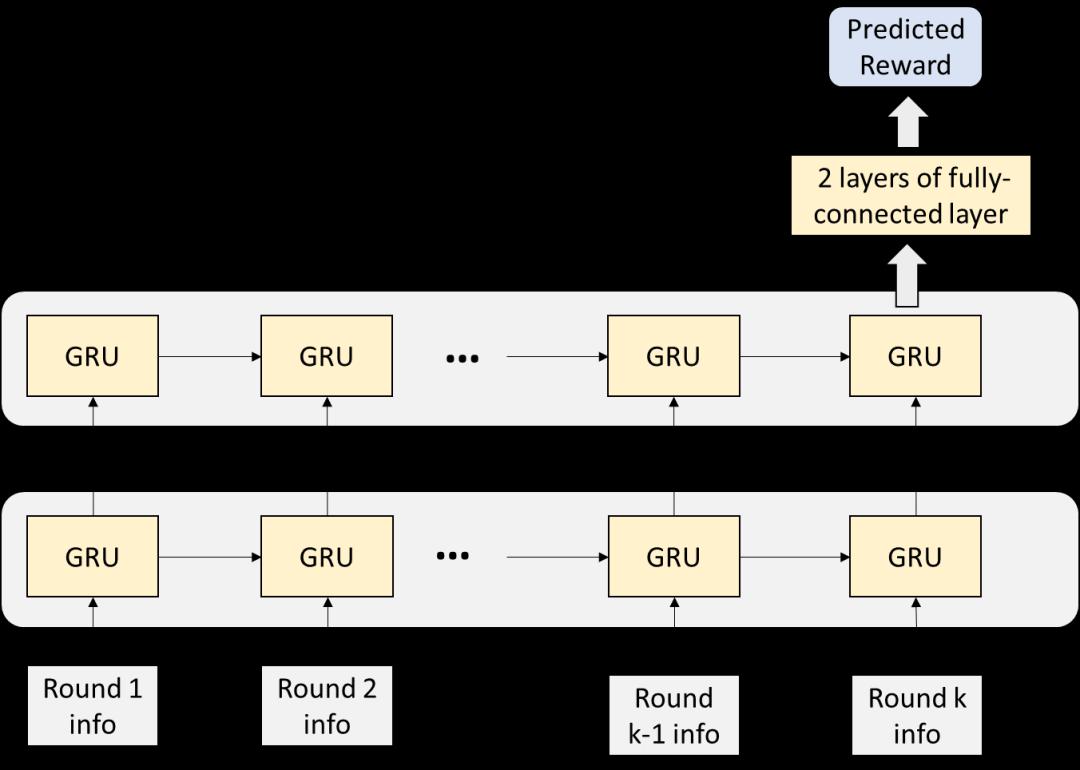
图7:全局奖励预测器
该奖励预测器的训练数据来自于高手玩家在天凤平台的历史记录,而训练过程则是最小化预测值和最终游戏奖励之间的平方误差。预测器训练好后,对于自我博弈生成的游戏,我们用当前局预测的最终奖励和上一局预测的最终奖励之间的差值作为该局强化学习训练的反馈信号。
先知教练
麻将中存在着丰富的隐藏信息,如其他玩家的手牌、墙牌等,如果不能获得这些隐藏信息,那么就很难确保某个动作(例如丢三万)的好坏,这也是麻将之所以很难的一个根本原因。在这种情况下,虽然 Suphx 可以通过强化学习来提高策略,但学习速度会非常慢。
为了加快强化学习训练的速度,我们引入了一个“先知”,它可以看到所有的信息,包括(1)玩家自己的私有手牌,(2)所有玩家的公开牌,(3)其他公共信息, (4)其他三个玩家的私有手牌,(5)墙牌。只有(1)(2)和(3)是正常的玩家可以获得的,而(4)和(5)是只有“先知”才能获得的额外的 "完美 "信息。

图8:左边为正常可观测信息,右边为完全信息(包括对手手牌墙牌这些“完美”信息)
有了这些“不公平”的完美信息,“先知”在经过强化学习训练后,很容易成为麻将超级高手,安定段位也很容易就可以超过20段。这里的挑战是,如何利用“先知”来引导和加速 AI 的训练。
实验表明,简单的知识萃取(knowledge distillation)或者模仿学习(imitation learning)并不能很好地把“先知”的“超能力”转移到 AI 系统上——对于一个只能获取有限信息的正常 AI 来说,它很难模仿一个训练有素的“先知”的行为,因为“先知”的能力太强,远远超出了普通 AI 的能力。比如,“先知”看到了其他玩家的手牌,知道每个玩家胡什么牌,所以它可以打出绝对安全的牌,避免因为丢牌使得其他玩家胡牌,然而正常的 AI 并没有这些信息,它可能完全不能理解为什么“先知”会打这张牌,所以也不能学到这种行为。因此,我们需要一个更聪明的方法,用“先知”来引导正常 AI 的训练。

在 Suphx 中,我们的做法如下:
首先,通过强化学习训练“先知”,使用包括完美信息在内的所有特征来训练“先知”。在这一过程中需要控制“先知”的学习进度,不能让其过于强大。
然后,我们通过加 mask 逐渐丢掉完美特征,使“先知”最终过渡到正常 AI。
接着,我们继续训练正常 AI,并进行一定数量的迭代。持续训练的过程中采用了两个技巧:一,将学习率衰减到十分之一;二,我们采用了拒绝采样,即如果自我博弈生成的样本和当前模型的行为相差太大,我们便会抛弃这些样本。根据我们的实验,如果没有这些技巧,持续训练会不稳定,也不会带来进一步的改进。
参数化的蒙特卡洛策略自适应
对一个麻将高手来说,初始手牌不同时,他的策略也会有很大的不同。例如,如果初始手牌好,他会积极进攻,以获得更多的得分;如果初始手牌不好,他会倾向防守,放弃胡牌,以减少损失。这与此前的围棋 AI 和星际争霸等游戏 AI 有很大的不同。所以,如果我们能够在对战过程中对线下训练的策略进行调整,那么我们就可以得到更强的麻将 AI。
蒙特卡洛树搜索(MCTS)是围棋等游戏 AI 中一种成熟的技术,以提高对战时的胜率。然而遗憾的是,如前所述,麻将的摸牌、打牌顺序并不固定,很难建立一个规则的博弈树。因此,MCTS 不能直接应用于麻将 AI。在 Suphx 中,我们设计了一种新的方法,命名为参数蒙特卡洛策略自适应(pMCPA)。
当初始的手牌发到麻将 AI 手中时,我们会调整离线训练好的策略,使其更适应这个给定的初始手牌,具体过程为:
模拟:随机采样三个对手的手牌和墙牌,然后利用离线训练的策略将这一局模拟打完。总共做 K 次。
调整:利用这 K 次打牌的过程和得分进行梯度更新,微调策略。
打牌:使用微调后的策略与其他玩家进行对战。
我们的实验表明,相对麻将隐藏信息集的平均大小10的48+次方倍而言,模拟的次数 K 的数量不需要很大,pMCPA 也并不需要为这一局手牌收集所有可能后续状态的统计数据。由于 pMCPA 是一种参数化的方法,所以微调更新后的策略可以帮助我们将从有限的模拟中获得的知识推广泛化到未见过的状态。
在线实战
Suphx 已在天凤平台特上房和其他玩家对战了5000多场,达到了该房间目前的最高段位10段,其安定段位达到了8.7段(如图9所示),超过了平台上另外两个知名 AI 的水平以及顶级人类选手的平均水平。
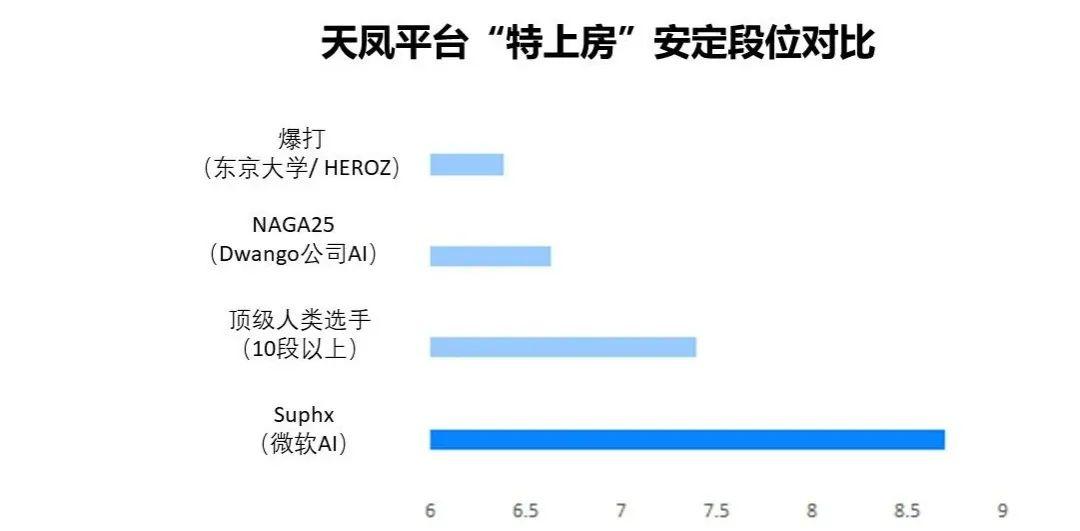
图9:天凤平台“特上房”安定段位对比
下表展示了 Suphx 在这些对战中的一些统计数据,包括1/2/3/4位率、胡牌率以及点炮率。我们发现 Suphx 特别擅长防守,它的4位率和点炮率(deal-in rate)尤其低。
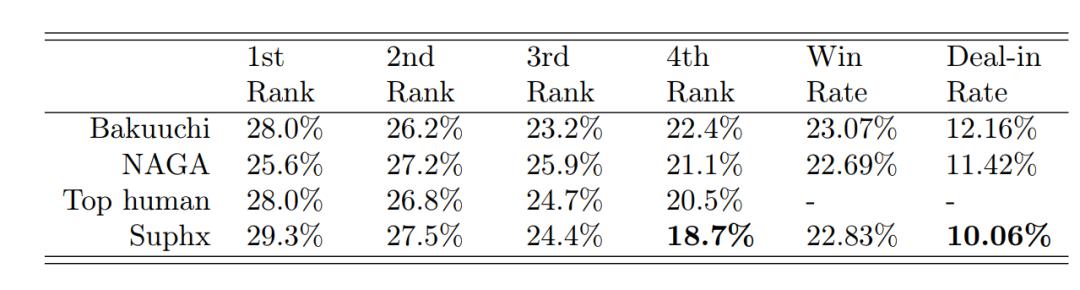
注:上表格中的 Bakuuchi 即东京大学/HEROZ 研发的麻将 AI “爆打”
Suphx 可以说是“另辟蹊径”, 具有鲜明的个人风格,创造了许多新的策略和打法,例如它特别擅长保留安全牌,倾向于胡混一色等等。下图展示了 Suphx 在天凤平台实战时保留安全牌的一个例子。当前时刻 Suphx(南家)需要丢牌,如果是一个人类玩家高手,在这种情况下会丢北风,但是 Suphx 这个时候会丢掉一张7条,这在人类玩家看起来会觉得很不寻常,因为7条是一张好牌,丢掉7条会使得胡牌的进度变慢。Suphx 之所以丢掉7条而留住北风,是因为北风是一张安全牌,这样在未来某一时刻,如果有人突然立直要胡牌了,Suphx 可以打出北风而不点炮,这样后面还有机会胡牌;如果它在前面已经把北风丢掉,那这个时候为了打出一张安全牌就不得不拆掉手里的好牌,从而大大降低了胡牌的可能。

图10:Suphx(南边位置)保留安全牌北风
许多观看 Suphx 比赛的玩家表示在观战过程中受到了启发,甚至有麻将爱好者将 Suphx 称作“麻将教科书”、“Suphx 老师”,通过学习 Suphx 的打法,帮助他们进一步提升和丰富自己的麻将技巧。“我已经看了 300 多场 Suphx 的比赛,我甚至不再观看人类玩家的比赛了。我从 Suphx 身上学到了很多新技术,它们对于我的三人麻将打法有着非常大的启发,”麻将选手太くないお在社交媒体上表示。去年 6 月太くないお成为世界上第 15 位三人麻将天凤位获得者,也是第一位在四人麻将和三人麻将中均取得天凤位的顶级玩家。
总结和展望
Suphx 可谓是迄今为止最强的麻将 AI 系统,也是天凤平台上首款超越大多数顶尖人类玩家的麻将 AI。我们相信,今天 Suphx 在天凤平台上取得的成绩只是一个开始,未来,我们将为 Suphx 引入更多更新的技术,继续推动麻将 AI 和不完美信息游戏研究的前沿。
同时,我们也期待游戏 AI 的研究可以推动人工智能技术的创新发展,让人工智能真正走进我们的生活,帮助人们解决更加错综复杂的现实挑战。很多现实世界中的问题如金融市场预测、物流优化等与麻将有着相同的特点,包括复杂操作/奖励规则、信息的不完全性等。
我们相信,我们在 Suphx 中为麻将 AI 设计的技术,包括全局奖励预测、先知引导和参数化策略自适应等技术,在现实世界的应用中将大有可为,我们也正在积极推动这些技术的外延及落地。(转载自:AI科技大本营)

