有许多指标可用来衡量模型的性能,具体取决于您要进行的机器学习的类型。 在本文中,我们将研究分类和回归模型的性能指标,并讨论哪种指标可以进行更好的优化。 有时要看的指标会根据最初要解决的问题而有所不同。
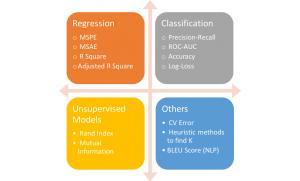
机器学习指标的示例
分类问题的优化
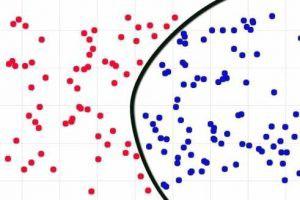
分类表示例
1.真实肯定(召回)
真实肯定率(也称为召回率)是二进制/非二进制分类问题中的首选性能指标。 在大多数情况下(即使不是所有时间),我们只对正确预测一个类感兴趣。 例如,如果您正在预测糖尿病,则比起预测此人没有糖尿病,您将更关心预测此人是否患有糖尿病。 在这种情况下,阳性类别为"此人患有糖尿病",阴性类别为"此人未患有糖尿病"。 这只是预测肯定类别的准确性(这不是准确性性能指标。有关更多详细信息,请参见下面的数字4)
2. ROC曲线(接收机工作特性曲线)
ROC曲线显示分类模型在不同阈值(分类到特定类的可能性)下的性能。 它绘制了真假阳性率和假阳性率。 降低阈值将增加您的真实肯定率,但会牺牲您的错误肯定率,反之亦然。
3. AUC(曲线下面积)
AUC也称为" ROC曲线下的面积"。 简单地说,AUC会告诉您正确分类的可能性。 较高的AUC代表更好的模型。
4.准确性
默认情况下,精度是第一要注意的事情。 但是,真正的数据科学家知道准确性太误导了。 一种更好的称呼方法是预测所有类别的平均准确性。 就像我在True True Rate中提到的那样,它是最理想的指标。 准确度将取"真正值"和"真负值"之和的平均值。 在不平衡分类问题中,大多数情况下,否定类比肯定类的代表更多,因此您更有可能具有很高的真实否定率。 然后,准确度将偏向负面类别的准确预测,这可能不会引起任何人的兴趣。
机器学习中的回归优化
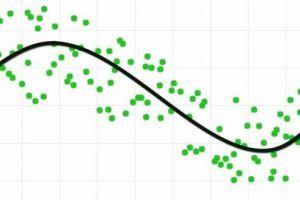
回归图示例
5.错误
该错误通常会在R旁边被忽略,它告诉我们更多有关拟合值相对于回归线(即拟合值与优秀拟合线之间的平均距离)的精度的信息。 在计算模型的置信度和预测间隔时,这一点尤为重要。 由于使用响应变量的自然单位,因此更易于解释,而R没有单位,并且仅在0到1之间。
误差有不同类型,例如"均值绝对误差"和"均方根误差"。每种误差都有其优缺点,必须单独对待以评估模型。
6. R2
现在,尽管"标准误差"很重要,但R已成为良好回归模型的实际度量。 它告诉我们模型解释了因变量和自变量之间的差异。 较高的R会给出更好的模型,但是,如果过高(接近99%)有时会导致过度拟合的风险。 由于相关性与因果关系的争论可能会给R带来不合逻辑的高R,因此R可能会产生误导。
用户的目标会影响模型的性能,因此请谨慎选择
精度并非始终是分类问题中的优秀度量,R对于回归而言可能并非最佳。 无疑,它们都是最容易理解的,尤其是对于非技术利益相关者而言(这也许是首先构建模型的较大原因)。 比较好的方法可能是考虑各种性能指标并考虑您的初始目标。 模型的性能始终取决于用户的目标。 从一个人的角度来看,表现不佳对于另一个人而言可能并非如此。

