如何在 DataOps、MLOps 和 AIOps 之间进行选择?大数据团队应该采取哪种 Ops?
两年前,由于我领导的运维团队效率低下,我“赢得”了耻辱的勋章。我具有数据科学和机器学习的背景,因此,我们想当然的从工程团队的同事那里学来了 DevOps。
至少我们是这么认为的。
这在当时对我们来说是不可思议的,因为我们的数据科学家就坐在数据工程师的旁边。我们遵循了所有好的敏捷实践——每天开站会,讨论阻碍我们的因素,并没有那种“隔墙扔砖”的状态。我们密切合作,我们的科学家和工程师彼此相爱。但进展很缓慢,团队成员很沮丧。
过了两年,我终于理解了 DevOps 的真正含义。它在数据团队中是如此的相同,又是如此的不同。
在讨论以数据为中心的 Ops 之前,让我们先从软件开始。它们有太多的相似之处和对比了,请耐心听我说……
自从 2000 年末 DevOps 普及以来,软件行业就一直痴迷于各种 Ops 术语。十年前,从软件开发到部署的方式早已推陈出新。软件工程师开发应用程序,然后将其交给运维工程师。应用程序在部署过程中经常会出现故障,并在团队之间造成重大摩擦。
DevOps 实践的目的是使部署过程更加顺畅。其理念是将自动化视为构建和部署软件应用程序的一等公民。
这种方式彻底改变了整个行业。许多组织开始通过组建跨职能的团队来管理整个 SDLC。团队会搭建基础设施(基础设施工程师),开发应用程序 (软件工程师),构建 CI/CD 管道(DevOps 工程师),部署应用程序(每个工程师),然后持续监控和观察应用程序 (站点可靠性工程师)。
在一个大型的团队中,不同的工程师都有各自的主要职能。但在较小的团队中,一名工程师往往要扮演多种角色。理想的情况是让许多团队成员能够履行多项职能,这样就可以消除瓶颈和对关键人员的依赖。所以实际上……
DevOps 与其说是一项工作职能,不如说是一种实践或文化。在构建任何软件时都应该采用它。
随着 DevOps 的兴起,各种 Ops 也应运而生了。
软件开发世界中存在的各种 Ops,作者制作
SecOps 以安全为核心,GitOps 致力于持续交付,NetOps 确保网络能够支持数据流,ITOps 专注于软件交付之外的运维任务。但总的来说,这些 Ops 的基石都是源于 DevOps 承诺的愿景:
“以最低的错误率,尽可能快的速度交付软件”
五年前,所有人都鼓吹“数据是新石油”(Data is the new Oil)。世界各地的领导者开始投入大量资源,组建大数据团队来挖掘这些宝贵的资产。对这些团队来说,交付的压力是巨大的——毕竟,我们怎么能辜负“新石油”的承诺呢?随着业务的快速扩张,分析团队也经历了同样的悲痛。
然后我们实现了所有的一切。
数据科学家成为了 21 世纪最性感的职业。我们正处于数据和分析的黄金时代。每个高管都有一个仪表盘。这个仪表盘包含了来自整个组织的数据和嵌入的预测模型。每个客户都有一个基于其行为的个性化推荐。
但是,现在添加一个新功能需要花费数周甚至数月的时间。数据模式很混乱,没有人知道我们使用的活跃用户定义是来自信贷团队的还是来自营销团队的。我们在将模型投入生产时变得谨慎,因为我们不确定它会带来什么破坏。
因此,以数据为中心的社区站在了一起,承诺不会因为管理不善而导致效率低下。从那时起,各种以数据为中心的 Ops 也应运而生了……

在以数据为中心的团队中诞生的各种 Ops: DataOps、MLOps、AIOps,由作者制作
DataOps vs MLOps vs DevOps(以及 AIOps?)
注:在本文中,分析团队是指使用 SQL/PowerBI 来生成业务洞察力的传统 BI 团队。AI 团队是指使用大数据技术构建高级分析和机器学习模型的团队。有时他们是同一个团队,但我们会将他们分开,这样能更容易地解释相应概念。
为了理解所有这些不同的 Ops,让我们来看一下数据是如何在组织中流动的:
通过客户与软件程序的交互产生数据。
软件将数据存储在应用程序的数据库中。
分析团队根据这些来自不同团队的应用程序数据库构建 ETL。
分析团队为业务用户构建报表和仪表盘,以协助他们做出以数据为驱动的决策。
然后,数据工程师将原始数据、合并了的数据集(来自分析团队)和其他非结构化的数据集整合到某种形式的数据湖中。
然后,数据科学家利用这些海量的数据集建立模型。
然后,这些模型利用用户生成的新数据进行预测。
然后,软件工程师将预测结果呈现给用户,
这样的循环不断进行下去……
我们知道,DevOps 的诞生是由于开发团队和运维团队之间产生了摩擦。因此,可以想象一下,在运维、软件、分析和 AI4 个团队之间进行交互会有多痛苦。
为了说明这些不同的 Ops 是如何解决上述过程的,这里有一个图表,它绘制了每个工作职能在整个时间轴上所执行的一些任务。
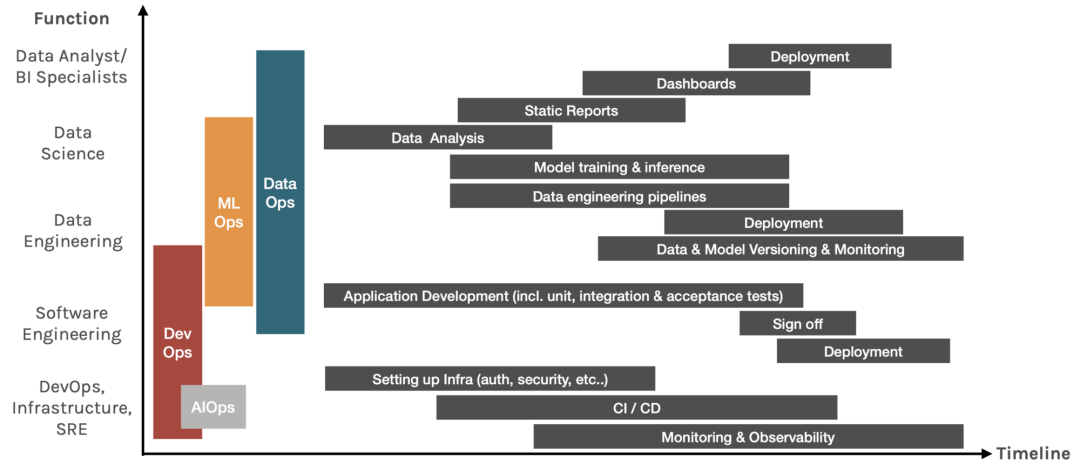
每个工作职能在时间轴上所执行的任务图,由作者生成
理想情况下,应在项目开始时采用 X-Ops 文化,并在整个过程中实施。
总体而言之,以下就是每种 Ops 的具体含义:
DevOps 更快地交付软件
一系列旨在消除开发和运维团队之间障碍的实践,以便更快地构建和部署软件。它通常会被工程团队所采用,包括 DevOps 工程师、基础设施工程师、软件工程师、站点可靠性工程师和数据工程师。
DataOps 更快地交付数据
一系列旨在提高数据分析质量并缩短分析周期的实践。DataOps 的主要任务包括数据标记、数据测试、数据管道编排、数据版本控制和数据监控。分析和大数据团队是 DataOps 的主要操作者,但是任何生成和使用数据的人都应该采用良好的 DataOps 实践。这包括数据分析师、BI 分析师、数据科学家、数据工程师,有时还包括软件工程师。
MLOps 更快地交付机器学习模型
一系列设计、构建和管理可重现、可测试和可持续的基于 ML 的软件实践。对于大数据 / 机器学习团队,MLOps 包含了大多数 DataOps 的任务以及其他特定于 ML 的任务,例如模型版本控制、测试、验证和监控。
附加:AIOps 利用 AI 的功能增强了 DevOps 工具
有时人们错误地将 MLOps 称为 AIOps,但它们是完全不同的。以下说明来自 Gartner(高德纳,美国咨询公司):
AIOps 平台利用大数据、现代机器学习以及其他先进的分析技术,直接或间接地增强 IT 运维(监控、自动化和服务台),具有前瞻性、个性化以及动态的洞察力。
因此,AIOps 通常是利用 AI 技术来增强服务产品的 DevOps 工具。AWS Cloud Watch 提供的报警和异常检测是 AIOps 的一个很好的例子。
是原则不是工作角色
存在的一种误解是:为了达到这些 Ops 所承诺的效率,需要从选择正确的技术开始。事实上,技术并不是最重要的。
DataOps、MLOps 和 DevOps 的实践必须是与语言、框架、平台和基础设施无关的。
每个人都有不同的工作流程,该工作流程应该由相应的原则来决定,而不是你想要尝试的技术,或者最流行的技术。技术先行的陷阱是,如果你想用锤子,那么一切对你来说都像是钉子。
所有的 Ops 都具有相同的 7 个首要原则,但是每个原则又都有其细微的差别:
1. 合规
DevOps 通常会担心网络和应用程序的安全性。在 MLOps 领域,金融和医疗保健等行业通常需要模型的可解释性。DataOps 需要确保数据产品符合 GDPR/HIPPA 等法规。
工具:PySyft 能够解耦模型训练过程中的私有数据,AirClope 能够匿名化数据。Awesome AI Guidelines 能够基于 AI 的原则、标准和规范进行管理。
2. 迭代开发
该原则源于敏捷方法论,它专注于以可持续的方式不断地产生业务价值。产品经过迭代设计、构建、测试和部署,以最大程度地实现快速失败并不断学习。
3. 可重现性
软件系统通常是确定性的:代码每次都应该以完全相同的方式运行。因此,为了确保可重现性,DevOps 只需跟踪代码即可。
然而,机器学习模型经常会因为数据漂移而被重新训练。为了重现结果,MLOps 需要对模型进行版本控制,DataOps 需要对数据进行版本控制。当被审计师问到“产生这个特定的结果,需要使用哪个模型,需要使用哪些数据来训练该模型”时,数据科学家需要能够回答这个问题。
工具:实验跟踪工具,比如 KubeFlow、MLFlow、SageMaker,它们都具有将元数据链接到实验运行中的功能。Pachyderm 和 DVC 可用于数据版本控制。
4. 测试
软件测试包括单元测试、集成测试和回归测试。DataOps 需要进行严格的数据测试,包括模式变更、数据漂移、特征工程后的数据验证等。从 ML 的角度来看,模型的准确性、安全性、偏差 / 公平性、可解释性都需要测试。
工具:像 Shap、Lime 这样的库可用于可解释性,fiddler 可用于解释性监控,great expectation 可用于数据测试。
5. 持续部署
机器学习模型的持续部署由三个组件构成:
第一个组件是触发事件,即触发器是数据科学家的手动触发器、日历计划事件和阈值触发器吗?
第二个组件是新模式的实际再培训。生成模型的脚本、数据和超参是什么?它们的版本以及它们之间的联系。
最后一个组件是模型的实际部署,它必须由具有预警功能的部署管道进行编排。
工具: 大多数的工作流管理工具都具有此功能,比如 AWS SageMaker、AzureML、DataRobot 等。开源工具有 Seldon、Kubeflow 等。
6. 自动化
自动化是 DevOps 的核心价值,实际上有很多专门针对自动化各个方面的工具。以下是一些机器学习项目相关的资源:
Awesome Machine Learning
https://github.com/josephmisiti/awesome-machine-learning
Awesome Production Machine Learning
https://github.com/ethicalml/awesome-production-machine-learning
7. 监控
软件应用程序需要监控,机器学习模型和数据管道也需要监控。对于 DataOps 来说,重要的是监控新数据的分布,以发现是否有任何数据和 / 或概念的漂移。在 MLOps 领域,除了模型降级之外,如果你的模型具有公共 API,那么监控对抗性攻击也是至关重要的。
工具: 大多数工作流管理框架都具有某种形式的监控。其他流行的工具包括用于监控度量指标的 Prometheus,用于数据和模型监控的 Orbit by Dessa。
结论
采用正确的 X-Ops 文化来加快数据和机器学习驱动的软件产品的交付。请记住,原则胜过技术:
培养跨学科技能: 培养 T 型个人和团队(弥合差距,协调问责制)
尽早实现自动化(足够): 集中在一个技术栈上并实现自动化(减小工程过程的开销)
以终为始: 在解决方案设计上提前投资,以减少从 PoC 到生产的摩擦
原文链接:
https://towardsdatascience.com/what-the-ops-are-you-talking-about-518b1b1a2694

