
【51CTO.com快译】毋庸置疑,数据不但可以帮助企业在决策的过程中消除各种猜测,而且能够让用户团队使用由数据驱动的证据,来决定要构建哪些产品,添加哪些功能,以及需要改进哪些计划与目标。不过,数据感知力并非简单等于洞察驱动力,后者往往需要找到一种近乎实时的数据分析方法。
如今,作为可扩展类型的数据存储库,云数据仓库能够让企业通过存储和分析大量结构化、以及半结构化的数据,来寻找并发现洞察驱动力,进而为企业即将推出的各种产品、营销策略和工程决策,提供全面的业务信息。
当然,选择云数据仓库的提供商往往是一件具有挑战性的工作。用户必须根据他们的需求,综合评估数据仓库的成本、性能、处理实时负载的能力、以及其他方面。在此,我们将分析当前四大流行云数据仓库:Snowflake、Amazon Redshift、Google BigQuery和Azure Synapse Analytics,综合比较它们优缺点,并深入探讨您在选择云数据仓库时需要考虑的各项因素。
什么是数据仓库?
数据仓库是一个系统,它将来自各种源头的数据导入一个中央存储库中,并为后续的快速检索做好准备。数据仓库通常包含了从事务系统、操作数据库、以及其他来源,提取到的结构化和半结构化的数据。数据工程师和分析师可以将这些数据用于商业智能、以及其他各种目的。
数据仓库既可以被部署在本地、又可以在云端、还可以两者混合起来实施。在本地部署的方案中,由于其需要拥有物理服务器,因此用户会时常诟病于购买更多的硬件。这会让数据仓库的扩展性,变得更加高昂且具有挑战性。相比之下,其云端在线存储方案的成本较低,且具备自动化的扩展能力。
何时该使用数据仓库
数据仓库可被用于多项任务。例如,您可以使用它,将历史数据存储在一个作为单一事实源的统一环境中,以便整个组织的用户可以依据该存储库,来执行日常任务。
同时,数据仓库可以统一、并分析来自Web、客户关系管理(CRM)、移动设备、以及其他应用程序的数据流。通过将它们转换为可使用的格式,用户可以采用各种分析工具,充分利用各种SQL查询服务,提高对于存储数据的业务理解和洞察力。例如,通过使用Google Analytics(GA),企业可以了解到客户会如何与他们的应用程序、或网站进行互动。为了突破在深度洞察上的限制,GA还能够与已存储在Salesforce、Zendesk、Stripe等平台上的数据仓库相连接,将所有数据存储在一处,通过分析和比较不同的变量,进而生成富有洞察力和可视化的数据视图。
只使用数据库不够吗?
传统观点认为,除非您拥有TB或PB的复杂数据集,否则您可能只需使用诸如PostgreSQL之类的OLTP数据库即可搞定。然而,云计算使得数据仓库对于更小的数据量具有了成本效益。例如,BigQuery对于首个TB量级的查询处理是免费的。此外,无服务器类云数据仓库的总拥有成本,也会使得分析变得更加简单。

BigQuery的定价方案
时下流行的云数据仓库
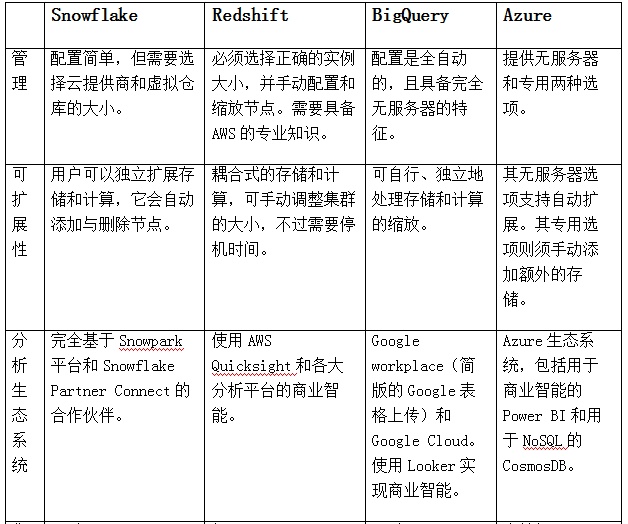
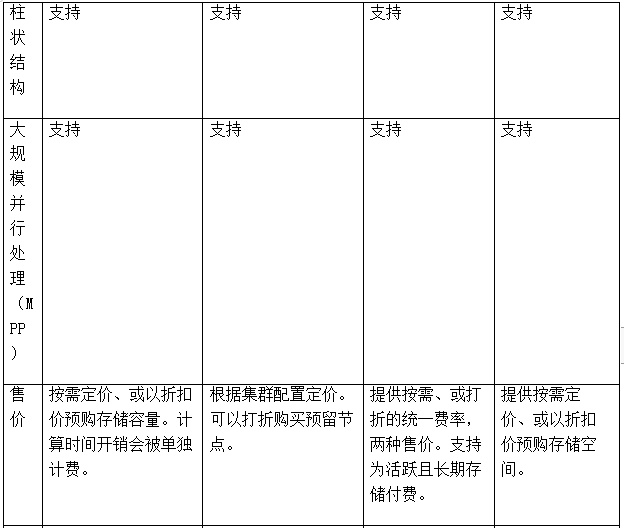
目前,业界有许多新兴的云数据仓库提供商,其中当属Snowflake、Amazon Redshift、Google BigQuery和Microsoft Azure Synapse Analytics,四种最为主流和可靠。他们在成本或技术细节上虽然有所不同,但是都具有高度可扩展性等共同特征。例如,它们都采用了大规模并行处理(massively parallel processing,MPP)的方式,来同时处理多项操作的存储结构。这样既加速了存储和计算资源的扩缩容,又实现了以数据列格式的存储,所带来的更好的压缩和查询特性。它们即便在发生中断或故障时,也能保证可靠的数据复制、备份、以及快速检索。
此外,与部署在本地的数据仓库相比,云端方案更具有商业智能上的可扩展性,能够加速分析操作,快速上线,提供数据的集成、可观察性,以及整个生态系统。
数据仓库对比一览表


Snowflake
Snowflake是一个可运行在Google Cloud、Microsoft Azure和AWS架构之上的云数据仓库。由于其并非运行在自己的云基础架构上,而使用的是主流公共云服务提供商,因此它可以让用户更加轻松地,以跨云平台、跨区域的方式移动数据。
Snowflake支持几乎无限数量的并发用户,并且可以在几乎零维护与管理的情况下运行。与之相关的更新与清理元数据,按需扩展,按秒计费,以及许多其他琐碎的维护任务都可以被自动化。
用户还可以使用SQL或其他商业智能(BI)和机器学习(ML)工具,去查询半结构化的数据。同时,Snowflake还提供了对于XML、JSON、以及Avro等文档存储格式的原生支持。如下图所示,其混合架构分为:云服务层、计算层和存储层,三个不同的层次。
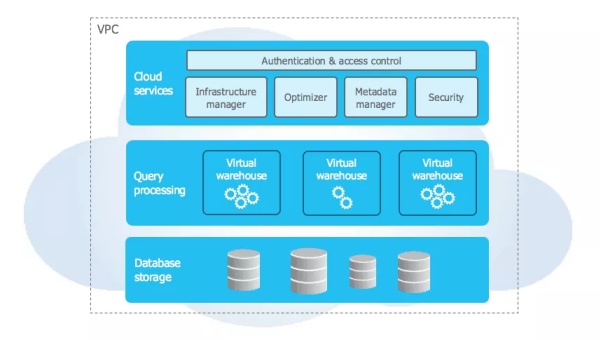
Snowflake的三层架构
作为Snowflake的主要客户,日本乐天电子商务集团使用它来扩展其数据资源。该公司曾有一个被称为Rakuten Rewards的现金返还和购物奖励计划。随着投入CPU和内存数量的不断增加,其用户需求逐渐超出了现有的数据仓库能力。通过在引入Snowflake后,乐天为各个团队设立了专门的仓库。由于Snowflake能够将存储层与计算层相分离,因此那些来自不同业务部门的工作负载,被隔离到了不同的仓库中,避免了相互干扰。最终,乐天不但降低了整体成本,提高了数据的处理效率,而且获得了对其数据操作上的更多可见性。
Amazon Redshift
由Amazon提供的云数据仓库服务—Redshift,可以处理从GB到PB量级大小的数据集。在使用过程中,用户需要先启动一组节点并将其配置好,以便上传并分析数据。作为Amazon Web Services(AWS)生态系统的一部分,Redshift数据仓库服务提供了诸如将用户数据从数据湖中导出,并与其他平台(如:Salesforce、Google Analytics、Facebook Ads、Slack、Jira、Splunk、以及Marketo)相集成等服务。此外,Redshift仓库服务使用列式存储、数据压缩、以及区域映射,来实现高性能和高效存储。
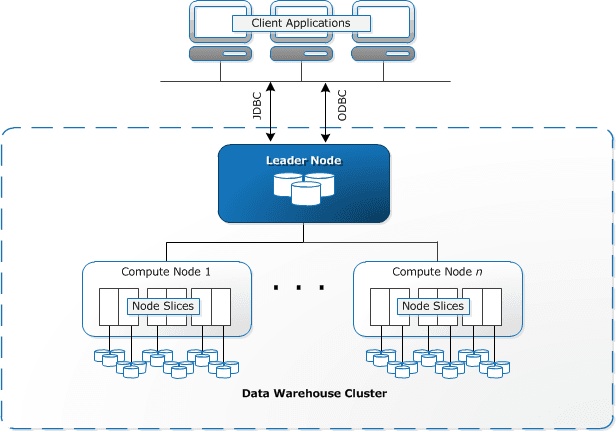
AWS Redshift 架构
目前,Redshift拥有包括Pfizer、Equinox、以及Comcast等数以万计的客户。2020年,全球知名连锁餐厅--必胜客使用Redshift,来整合那些由亚太地区门店所产生的数据,以便其团队能够快速地访问、查询和可视化PB级的数据。过去需要几小时才能生成的商业智能报告,如今几分钟便可搞定。
Google BigQuery
BigQuery是由Google提供的无服务器多云式数据仓库。该服务可以快速地分析从TB到PB量级的数据。与Redshift不同,BigQuery无需预先配置,便可自动执行诸如:数据复制、以及计算资源扩展等后端操作。同时,它能够自动加密各种静态和传输中的数据。
如下图所示,BigQuery架构是由多个组件所组成。其中,Borg是整体的计算部分;Colossus负责分布式存储;它的执行引擎叫做Dremel;而Jupiter就是它的网络。

BigQuery架构
由于BigQuery能够与其他Google Cloud产品协同工作,因此其用户包括Dow Jones、Twitter、The Home Depot、以及UPS等知名企业。例如,丰田的加拿大公司就曾建立了一个名为Build & Price的比较工具,以方便网站访客定制车辆,并获得即时报价。这些数据会由Google Analytics 360负责收集,并被提取到BigQuery中。然后,其仓储服务会将机器学习(ML)模型应用到这些数据上,并根据购买的可能性,为每个访客分配一个倾向得分。这些预测得分会每八小时刷新一次,并持续被导入Analytics 360。据此,丰田根据倾向得分创建了不同的群体,进而向每个群体投放个性化的广告。
Azure Synapse Analytics
由Microsoft提供的云数据仓库--Azure Synapse Analytics,通过统一的用户界面(UI)将数据仓库、数据集成、以及大数据分析结合在一起。借助在无代码环境中构建的ETL/ELT流程,用户不但可以从近百个本地连接器中提取数据,也可以通过集成化的人工智能(AI)和商业智能工具,实现Azure机器学习、认知服务、以及Power BI。此外,该智能工具还可以轻松地被应用于包括Dynamics 365、Office 365、以及各种SaaS产品的数据集中。
在Azure Synapse Analytics中,用户能够使用T-SQL、Python、Scala、以及.NET等语言,以预配置或无服务器的方式,按需分析数据资源。

Azure Synapse Analytics体系结构
目前,Microsoft的云数据仓库服务拥有众多的客户。其中作为零售和批发药业巨头的Walgreens,已经将其库存管理数据迁移到了Azure Synapse处,以便供应链分析师能够在其界面上,通过直接拖放和调用Power BI工具的方式,来查询并创建可视化的数据,进而降低了整体投入的成本。
选择云数据仓库时需要考虑的因素
用例
用户的独特运行环境和用例,往往是评估数据仓库提供商的关键因素之一。例如,使用JSON的企业可能会更喜欢Snowflake,毕竟它为该格式提供了原生支持。而没能配备专门数据管理员的小型组织,可能会避免使用Redshift,毕竟它需要定期监控和配置。对此,那些具有即插即用设置(plug-and-play)的服务,可能会更适合它们。
支持实时的负载
许多公司需要在数据生成之后,立即对其进行分析。例如,一些公司可能需要实时地检测各种欺诈或安全问题,而另一些公司可能需要处理大量的物联网(IoT)数据流,以进行异常检测。对此,IT团队应重点评估云数据仓库是如何处理数据流的摄取。例如:BigQuery提供了一个流式的API,用户只需几行代码即可完成调用。Azure为实时数据的摄入提供了内置的Apache Spark流等功能选项。Snowflake将Snowpipe作为附加组件,以实现实时的摄入。而RedShift则需要使用Kinesis Firehose,来实现数据流的摄取。
安全性
虽然每一个云数据仓库提供商都非常重视安全性,但是它们在技术上,特别是加密处理方式上会有所差异。例如,BigQuery能够在默认情况下,对传输中和静止的数据进行加密;而该功能需要在Redshift中得到明确的启用。
计费
由于提供商会以不同的方式来为服务计费,因此公司需要估算并知晓,他们期望每个月花费在集成、存储和分析的数据量与成本。据此,IT团队可以选择性价比高的云数据仓库提供商。
例如:Redshift会将计算资源和存储捆绑在一起,因此用户需要在接受预购的存储和内存容量的前提下,选用其简单的定价方案。Google会根据字节读取、流式插入、以及存储空间,来收取服务费。不过,由于读取的字节数往往会产生波动,因此由BigQuery采取的计费方式虽然精细,但是其成本难以被预测。Azure Synapse使用数据仓库单元(DWU)的概念,来为计算资源的定价,以便向用户单独收取存储的费用。Snowflake会根据用户使用到的虚拟仓库的数量和时长,进行计费;而它在存储方面,则是按照每月使用到的TB数量,来单独计费。
生态系统
生态系统对于应用程序和数据的留存也是非常重要的。例如:那些数据已经被存放在Google Cloud中的企业,可以通过使用BigQuery或Snowflake,来获得额外的性能提升。同时,由于共享着相同的基础设施,因此他们的数据非但不会在公共互联网上移动,而且其传输路径也会得到更好的优化。
数据类型
企业往往会用到结构化、半结构化、以及非结构化的数据,而大多数数据仓库只能支持前两种数据类型。因此,IT团队应当根据实际需求,确保选择的云仓库基础设施,能够存储和查询到特殊类型的数据。
扩缩容
既然是云数据仓库,那么针对存储和性能的扩展能力就需要被纳入评估的范畴。对此,Redshift要求用户手动添加更多的节点,以增加存储和算力资源。而Snowflake则具有自动扩缩容的功能,可以动态添加或删除各个节点。
维护
根据公司的规模和数据的不同需求,数据仓库应当通过提供自动或手动的方式,来实现日常的管理与维护。小型团队可以选用BigQuery或Snowflake所提供的自动优化服务。而Redshift等云数据仓库则提供了更具灵活性和掌控度的、手动级别的维护方式,以便用户团队更好地优化其数据资产。
小结
我们从各项参数、技术规格、以及定价模型等方面,为您综合比较了Snowflake、Redshift、BigQuery、以及Azure Synapse Analytics,这四种典型的云数据仓库。希望根据上述给出的考虑因素,您和您的团队能够从公司业务的实际需求出发,选定合适的服务提供商及其产品,让云数据仓库为贵司的产品、市场、销售、以及其他部门,提升数据的洞察力,减少盲目的猜测,并为激烈的竞争优势铺平道路。
原文标题:Cloud Data Warehouse Comparison: Redshift vs BigQuery vs Azure vs Snowflake for Real-Time Workloads,作者: Mariana Park

