得益于计算机仿真技术的不断发展,我们能够在电脑中重建越来越逼真的现实世界,制作出《冰雪奇缘》等优秀的特效电影。
但逼真的场景、丰富的细节离不开超高精度的物理模拟,因此特效的每一帧几乎都是用经费烧出来的。

现代动画电影(包括《冰雪奇缘》等),经常使用基于物理的动画生产特效,丰富感官的体验。基于粒子的表示是其中常用的方法。场景越大,粒子就越多。比如,要模拟一个 300 米长的溃坝场景中的水,可能会需要数千万粒子,而这些粒子的存储需要大量显存。比如说,如果需要96GB的显存,则需要购置大量高端显卡,如 4 块 NVIDIA Quadro P6000 GPU。
哦,对了,一块 P6000 在 Amazon 上的售价约为 4000 美元,而这样的 GPU,你要买 4 块。显然,这个成本不是普通家庭能玩得起的。
针对这一现状,快手、麻省理工、浙大、清华的研究者进行了物理编译器自动量化方面的研究,提出了一套用于量化模拟的新的语言抽象和编译系统——QuanTaichi。它可以使用低精度量化的数字数据类型并将其打包(packing)以表示模拟状态,从而减少了内存空间和带宽消耗。有了这项技术的加持,高精度的物理模拟只需要一块 GPU 就能实现。
QuanTaichi 的实现基于 MIT CSAIL 胡渊鸣等人之前提出的「太极(Taichi)」编程语言和编译器,使开发人员可以轻松地在不同的全精度和量化模拟器之间进行切换,以探索最佳的量化方案,并最终在空间和精度之间取得良好的平衡。相关工作已经入选图形学顶会 SIGGRAPH 2021,也已经被合入到了太极的开源 Github 库中。

论文链接:https://yuanming.taichi.graphics/publication/2021-quantaichi/quantaichi.pdf
项目地址:https://yuanming.taichi.graphics/publication/2021-quantaichi/
GitHub 地址:https://github.com/taichi-dev/quantaichi
下面这个视频展示了量化后的仿真结果。两只兔子形烟雾(4亿体素)演化的逼真程度和全精度浮点数的结果不相上下。但需要指出的是,这个 demo 需要的存储空间仅为全精度浮点数模拟的二分之一!
为了验证结果,研究人员还做了一些用户调研,测试题大致如下。你能分辨出哪个是量化后的吗?
同样的技术还可以应用在手机端,使得物理模拟在手机端提速 40%,让运算能力不太强的手机运行更复杂的效果。
总体来看,QuanTaichi 不仅可以在通用 GPU 计算领域大幅提升研发效能,助力游戏中的物理模拟、大尺度图像处理、媒体编解码、科学计算等方向,还适用于太极平台上应用的各类模型,能够提升存储空间的使用效率,也有助于太极技术生态的未来发展。
目前,太极技术已经让快手成为首个推出实时液体及烟雾模拟动态效果的短视频和直播平台,行业首发了「别哭鸭」、「我要去潜水」、「火焰超能力」等特效。其中,「圣诞快乐」魔法表情成为爆款,有 74 万用户拍摄并上传了视频,大约有两千多万用户观看了太极支持的这款魔法表情。
技术细节
用于模拟的量化数字数据类型
在 QuanTaichi 中,研究者提出了以下几种自定义数值类型:
1. 自定义整数类型(Custom Int)由用户指定位数的整数类型,包括有符号类型和无符号类型;

2. 自定义浮点数类型(Custom Float):由用户指定位数的浮点数类型,QuanTaichi 为其提供了三种实现:
定点数类型(Fixed-point):定点数使用一个自定义整数加一个缩放因子表示,读取乘以缩放因子实现整型数到浮点数的转换;读取时做相反的操作;

普通自定义浮点数类型(Floating-point):由用户指定的小数和指数部分组成;

共享指数浮点类型(Shared exponent):同样由用户指定的小数和指数部分组成。与普通自定义浮点数类型不同的是,该类型会共享同一个指数部分。物理模拟中的数据通常具有物理含义,当某些数值的绝对值显著大于其他值时,较小的数值通常影响不大。比如:考虑三维速度(u,v,w),当 x 方向的速度的绝对值远远大于其他两个方向时,v 和 w 的数值并不会对模拟造成显著的影响。
下图是三种自定义浮点数在内存中的组织形式示例:

位适配器类型
当前的计算机体系结构并不支持任意位长度的数据读写和计算,因此,研究者在 QuanTaichi 中提出了两种位适配器:
1. 位结构体(Bit structs)。位结构体允许用户使用多个不同的自定义类型数据(如 custom int 5、custom float 12 等)填充一个完整的计算机硬件原生支持的类型(如 32 位整数等)。
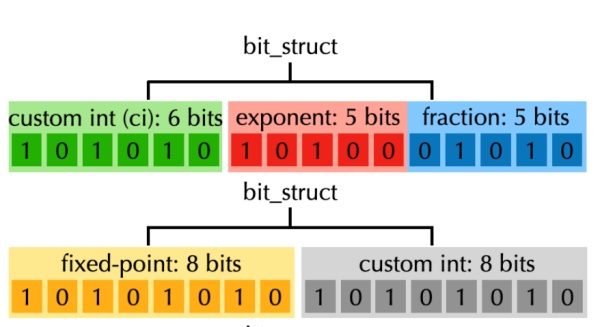
2. 位数组(Bit arrays)。位数组允许用户在一个硬件原生类型中存储多个同样的自定义类型数据。
编译器优化
1. 位结构体融合存储
这种优化的核心思想是分析 Kernel 的计算流程,将 bit-struct 内部的成员变量尽可能批量写入,减少原子性内存访问次数。
在实际应用中,一个位结构体中的字段经常一起访问,因此一个位结构体的不同组件很可能被一个 kernel 中的多个语句存储。在这种情况下,研究者对该位结构中的所有存储使用一个 atomicRMW(atomic read-modify-write), 以减少内存访问开销。
2. 线程安全推断
判断操作是否为线程安全,如果本身是安全的,则不用费时的原子写操作。QuanTaichi 支持两种访存模式的优化:
按元素访问(Element-wise accesses)。在并行模拟器中,许多操作以「元素」方式进行:每个独立线程一次处理一个粒子或体素,与粒子或体素相关的内存加载 / 存储完全不受数据竞争的影响。在这种情况下,可以安全地使用非原子操作来执行内存加载 / 存储;
位结构体整体存储(Storing the entire bit struct)。之所以使用 atomicRMW 而不是非原子操作,是为了避免原子位结构体中的部分位被程序并发修改。但当位结构体整体存储时,我们并不需要担心这一问题,因此可以使用非原子操作代替计算代价昂贵的 atomicRMW。
3. 位数组向量化
考虑以下情形:

虽然该研究中的系统可以很容易地提高存储效率,但是这种按位 for 循环的计算效率很低,原因有两个。首先,我们必须为模拟的 1 位数值使用硬件原生的 32 位整数寄存器,这只使用了操作位宽度的 1/32。其次,当逐位存储结果时,为了线程安全,代码生成器必须发出大量昂贵的 atomicRMW 操作,因为多个 CPU/GPU 线程可能会在一个 u32 中写入不同的位,从而导致数据争用。为此,研究者实现了以下三种优化方法:按位进行循环向量化;带有偏移量的位向量化读取;位向量化的整数加法。对位数组加载、存储并对算法进行矢量化,以便每次迭代都处理一个完整的 32 x u1 位数组,而不是单个的 u1。
实验结果
「生命游戏」测试
研究者首先在「生命游戏」上测试了他们的系统。生命游戏是一个二维网格游戏,这个网格中每个方格居住着一个活着或死了的细胞。一个细胞在下一个时刻的生死取决于相邻 8 个方格中活着或死了的细胞的数量。如果相邻方格活着的细胞数量过多,这个细胞会因为资源匮乏而在下一个时刻死去;相反,如果周围活细胞过少,这个细胞会因为孤单而死去。

每个细胞的「生」或「死」两种状态可以用一个位来表示。在 C 语言等传统语言中,用户必须使用 char (u8) 类型来表示细胞状态,除非他们手动打包 / 拆封这些状态。但在 QuanTaichi 系统中,用户可以在不修改任何计算代码的情况下将存储效率提升至原来的 8 倍。
OTCA 元像素是「生命游戏」中的一种特殊结构,该结构由 2048x2048 个细胞组成,其整体行为与单个细胞行为一致。研究者在单张 NVidia RTX 3080 Ti (10GB) 上实现了 70 x 70 个 OTCA 元像素,即超过 200 亿个细胞的生命游戏模拟。

欧拉流体模拟测试
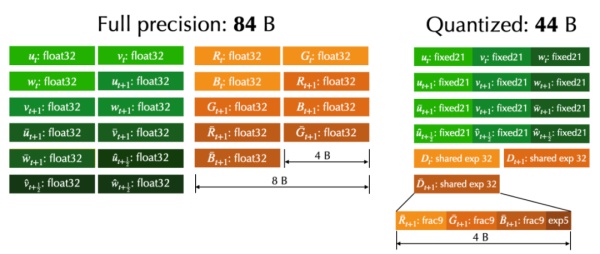
研究者实现了一个基于稀疏网格的 advection-reflection 流体模拟求解器。通过量化方法,他们成功地将每一个网格所需的存储空间从 84 个字节压缩到了 44 个字节。在 NVidia Tesla V100(32GB)上,他们实现了超过 4.2 亿个激活稀疏网格的烟雾模拟。下图分别是量化的方案和模拟结果。
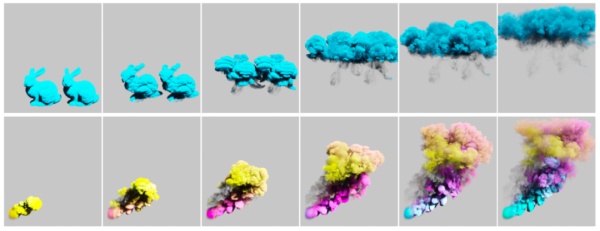
MLS-MPM 算法测试
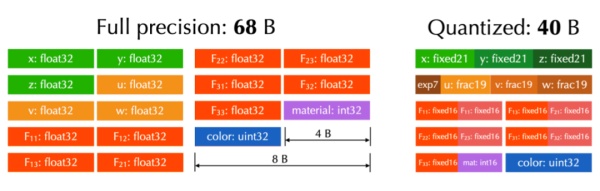
研究者选择了 MLS-MPM 算法测试他们的系统在混合欧拉 - 拉格朗日方法上的有效性。具体来说,他们选择了一种量化方案,使得每个粒子消耗的存储空间从 68 个字节下降到 40 个字节。在 NVidia RTX 3090 上,他们实现了超过 2.3 亿个粒子的弹性体模拟。下图分别是量化方案和模拟结果:

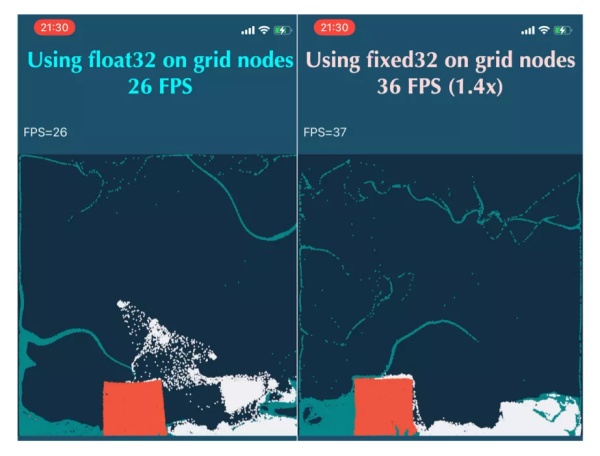
由于 iPhone 的 GPU 对整型运算增加了额外的优化和加速,因此研究者还在移动设备(iPhoneXS)上测试了量化后的 MLS-MPM 的表现。与台式机相比,移动设备的计算能力相对有限,并且对实时响应有强烈的需求。因此,它们通常只能运行小规模的模拟,存储并不是真正的问题。但在测试中,研究者惊讶地发现:在背景网格上使用量化数据类型仍然是有提升的。因为移动 GPU 通常只支持 32 位整数的高性能原生 atomicAdd,而并不原生支持浮点数的 32 位 atomicAdd。使用「ti.quant.fixed(fration=32)」表示网格数据可以将软件模拟的 32 位浮点数 atomicAdd 转换为硬件原生的 32 位整数 atomicAdd,显著提高了在 iPhone XS 上运行的 MLS-MPM 程序的 P2G 性能。