AI程序员狠起来连自己的岗位都要干掉。随着AutoML研究的深入,自动搜索最优的神经网络模型已经变得越来越快。最近微软开源了他们的方案FLAMA,网络搜索性能比sota还要显著提升,资源消耗降低为原来的十分之一!最重要的是它是Python库,三行代码就能彻底改造你的AutoML方案!
近年来,AutoML在自动化机器学习的设计方面已经取得了巨大的成功,例如设计神经网络架构和模型更新规则。
神经架构搜索(NAS)是其中一个重要的研究方向,可以用来搜索更好的神经网络架构以用于图像分类等任务,并且可以帮助设计人员在硬件设计上找到速度更快、能耗更低的架构方案。
但AutoML 是一个十分消耗资源和时间的操作,因为它涉及到大量的实验来排除性能不强的架构,来找到一个具有良好性能的超参数配置。由于它的搜索空间通常非常大,因此需要一种有效的 AutoML 方法来更有效地搜索它们。
AutoML 中超参数搜索的资源和时间消耗可归结为以下两个因素:
1. 大量的候选超参数的组合实验需要找到一个性能良好的配置;
2. 每个超参数的都需要很长时间来评估性能,因为评估过程包括训练模型和在一个给定的数据集上验证机器学习模型性能。
如此浪费时间,怎么忍?微软最近就带了他们FLAML(Fast Lightweight AutoML),即快速的、轻量化的AutoML库。

论文的第一作者是雷德蒙德微软研究院的首席研究员,研究主要集中在与数据平台和数据科学相关的理论和系统之间的相互作用,追求快速,经济,可扩展和实用的解决方案与理论保证。
他在清华大学获得了计算机科学学士学位,在伊利诺伊大学厄巴纳-香槟分校计算机科学系完成了博士学位。

FLAML是一个轻量级Python库,可以自动、高效、经济地查找准确的机器学习模型,用户无需为每个learner选择具体使用的模型和超参数。
它速度快,还省钱,简单轻量级的设计使得这个库很容易扩展,例如添加定制的learner或评价指标。
FLAML 利用搜索空间的结构同时优化成本和模型性能。它包含由微软研究院开发的两个新方法:
1. 成本节约优化 Cost-Frugal Optimization (CFO)
成本节约优化对搜索过程中对cost是十分敏感的,搜索方法从一个低成本的初始点开始,逐渐移动到一个较高的成本区域,同时优化给定的目标(如模型损失或准确度)。
2. BlendSearch
Blendsearch 是 CFO 的扩展,它结合了 CFO 的节俭和贝叶斯优化的探索能力。与 CFO 一样,BlendSearch 需要一个低成本的初始点作为输入(如果存在这个点的话) ,并从这个点开始搜索。然而,与 CFO 不同的是,BlendSearch 不会等到本地搜索完全收敛之后才尝试新的起点。
这两个方法的灵感来源主要源于传统的机器学习模型:
1. 许多机器学习算法都有超参数,这会导致训练成本的大幅度变化。例如,一个有10棵树的 XGBoost 模型比一个有1000棵树的模型训练得更快。
2. 参数的cost通常是连续的、一致的,也就是说评估10棵树比评估100棵树的速度要更快,而评估100棵树要比评估500棵树更快。
这两个思路提供了关于成本空间中超参数的有用的结构信息,CFO 和 BlendSearch,能够有效地利用这些启发式方法来降低搜索过程中产生的成本,而不影响到最优解的收敛性。

在验证FLAML的有效性时,在最新的 AutoML 基准测试中,FLAML 能够在超过62% 的任务上只使用10% 的计算资源,就能够获得与最先进的 AutoML 解决方案相同或更好的性能。
FLAML 的高性能归功于其快速的优化方法,CFO和BlendSearch利用搜索空间的结构来选择性能优良和成本低的搜索顺序。在有限的预算约束条件下,可以对搜索效率产生很大的影响。
FLAML利用搜索空间的结构来选择针对成本和错误优化的搜索顺序。例如,系统倾向于在搜索的开始阶段提出更简单、快速的配置,但在搜索的后期阶段需要时,会迅速转向具有高模型复杂度和大样本量的配置。如果它在开始时有利于简单的学习者,但如果错误改善过于缓慢,则会对这种选择进行惩罚。
CFO 从一个低成本的初始点(在搜索空间中通过 low_cost_init_value 指定)开始,并根据其随机本地搜索策略执行本地更新。利用这种策略,CFO 可以快速地向低损耗区域移动,表现出良好的收敛性。此外,CFO 倾向于在必要时避免探索高成本区域。进一步证明了该搜索策略具有可证明的收敛速度和有界的期望代价。
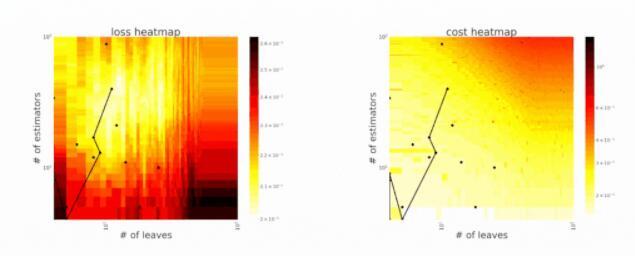
BlendSearch 进一步将 CFO 使用的局部和全局搜索策略与全球搜索结合起来。具体来说,BlendSearch 维护一个全局搜索模型,并基于全局模型提出的超参数配置逐步创建局部搜索线程。
它基于实时性能和损失进一步优化了全局搜索线程和多个局部搜索线程。在复杂的搜索空间情况下,如搜索空间包含多个不相交、不连续的子空间时,可以进一步提高 CFO 的效率。
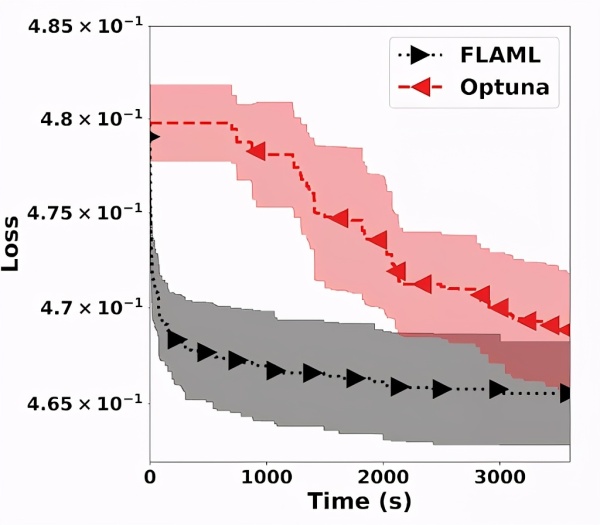
相比最先进的超参数调优库 Optuna 获得的结果,FLAML使用9个维度的超参数调优 LightGBM,可以看到,FLAML 能够在更短的时间内实现更好的解决方案。
研究人员进行了一个实验来检查 BlendSearch 和 Optuna (使用多变量 TPE 采样器)以及在高并行化设置中的随机搜索的性能。使用了来自 AutoML 基准测试的12个数据集的子集。每个优化运行是与16个试验并行进行20分钟,使用3倍的交叉验证,使用 ROC-AUC评价指标。这些试验用不同的随机种子重复了三次。
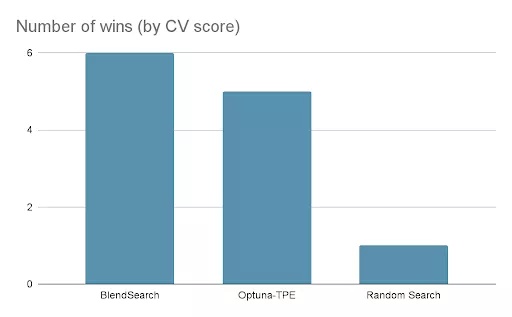
在12个数据集中,BlendSearch 在6个数据集中取得了最好的交叉验证分数。此外,与 Optuna 的1.96% 相比,BlendSearch 比随机搜索平均提高了2.52% 。值得注意的是,BlendSearch 使用单变量 Optuna-TPE 作为其全局搜索器ーー使用多变量 TPE 最有可能进一步提高分数。
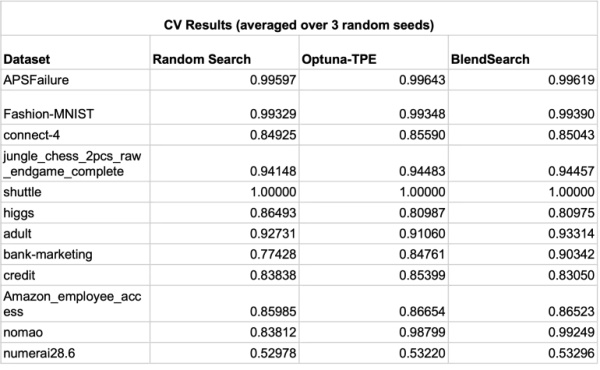
此外,由于其低成本的方法,BlendSearch 在同一时间内评估的试验次数平均是其他搜索者的两倍。这表明 BlendSearch 和其他算法之间的差距会随着时间预算的增加而扩大。
FLAMA的使用也很简单,首先使用pip进行安装。
假设提供了训练数据集并将其保存为 x _ train、 y _ train,任务是以60秒的时间预算调优 LightGBM 模型的超参数,代码如下所示。

除了LightGBM,FLAML 还为相关任务提供了丰富的定制选项,如不同learner、搜索空间、评估度量等。
为了加速超参数优化,用户可以选择并行化超参数搜索,BlendSearch 能够在并行中很好地工作: 它利用了多个搜索线程,这些线程可以独立执行,而不会明显降低性能。对于现有的优化算法(如贝叶斯优化算法)来说,并不是所有优化方法都可以并行处理。
为了实现并行化,FLAML 与 Ray Tune 进行集成中,Ray Tune 是一个 Python 库,可以通过边缘优化算法(edge optimization algorithms)来加速超参数调整。Ray Tune 还允许用户在不更改代码的情况下将超参数搜索从单个计算机扩展到集群上运行。
用户可以在 FLAML 中使用 Ray Tune,或者在 Ray Tune 中从 FLAML 运行超参数搜索方法来并行化的搜索,主要通过在 FLAML 中配置 n_concurrent _trials 参数可以实现并行。


