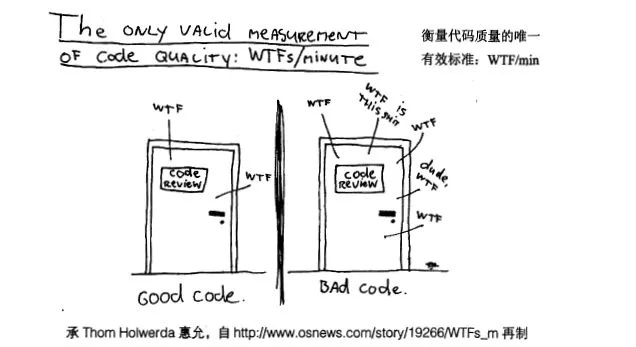
合格的程序员不仅仅是让代码跑起来,而是要做到代码整洁,只满足为了能让编译器通过编译,机器能跑就行而写代码的程序会算不上开发者,码农都不算。
好的命名能体现出代码的特征,含义或者是用途,让阅读者可以根据名称的含义快速厘清程序的脉络。
本篇分享如下代码命名套路来提高我们代码命名:
勿模糊,准确达意
避免误导
做有意义的区分
结合上下文简化名称
使用可搜索、易读的名称
包命名规范
类名与方法名规范
混乱的代价
我相信每个程序员都被某些人的垃圾代码恶心过,导致开发进度被严重延缓、性能差劲、bug 多。
每次新增和修改代码如履薄冰,我们只有对那堆腐朽的代码了然于胸才敢修改。
随着时间推移,团队生产力下降,所有人都抵触这个项目,对其束手无策。
新手不熟悉原来的场景和设计,不知道如何修改才符合实际意图,导致更容易出现混乱。
最后,开发团队产生了抵触心理并造反了,再也无法忍受在这个垃圾代码基础上做开发,而管理层不愿意投入资源重新设计。
一个优秀的开发者应该时刻保持代码整洁,无关 deadline。
为什么会写出垃圾代码呢?
有的人可能会说,需求变化违背了最初的设计、排期太紧没法干好......
其实,这是一种不专业的托词。
推进进度是产品经理他们该干的,虽然痴迷于进度,但是多数产品经理也会期望有良好的可拓展代码以便应对市场变换莫测的需求。
连海誓山盟的爱情都会变,又如何做到需求不会改变呢?
所以我们比他们更加重视代码质量,才能应对变化的需求。
保护代码持续整洁优雅是每个优秀开发者都应该遵守的原则。
混乱的代码只会拖慢未来的开发进度,唯一加快进度的方法:始终尽可能保持代码优雅整洁。
好比医生在做手术之前要先消毒,你说消毒太耗时间了,直接拿刀子整吧。
作为专业的医生你会照做么?
作为专业的程序员,我们要了解代码变坏的风险并坚持保持代码质量。
什么是整洁代码
代码质量评判需要综合各种因素得到的,我们并不能从单一的维度去评判。
比如代码可读性好,但是空间与时间复杂度高,这并不能算得上是好代码。
好的代码应该具备:易拓展和维护、简洁(只做好一件事)、可复用性强(没有重复代码)、能快速写出单元测试。可读性强、没有副作用(做了名称以外的工作)。
易拓展和维护
在不破坏原来的代码设计下,可以简单快速的修改和添加代码实现功能拓展。
简单地说就是预留了拓展点,将新代码放在设计的可拓展点,不会因为新增一个功能而改动大量原始代码。
对修改关闭,对拓展开放,开闭原则。
对于开发而言,我们维护旧代码的时间超过新项目新代码的时间。
代码的可维护性就变得很重要,也就是说代码分层清晰、模块划分精当,满足高内聚低耦合、抽象出合理的接口,面向接口编程就意味着有较好的可维护性。
同样的代码,熟悉他的资深工程师会觉得很容易维护,而新人因为不熟悉代码,不懂设计模式而无法理解。
所以,易拓展具有主观性,我们需要提高基础技能才有资格说代码是否易拓展和维护。
只做好一件事
单一职责:每个函数、每个类、每个模块只专注于一件事。
不要设计大而全的类或者函数,我们需要将他们拆分成更细粒度功能更加单一的类。
它不会隐藏设计者的意图,干净利落的抽象和直截了当的控制语句。
我们应该让每个函数每行代码简单、逻辑清晰。这样的话,类依赖和被依赖的类也会变少,减少耦合度。
需要注意的是,也不能拆分太细,否则就会破坏内聚性。
高手,就是用最简单的方法去解决复杂问题。
没有重复代码
在开发过程中,我们应该尽可能抽象出「变与不变」,复用已经存在的代码,不要写重复的代码。
比如运用「封装、继承、抽象、多态」特性,代码封装成模块,隐藏变化的细节,暴露不变的接口。
把业务与非业务的代码逻辑分析,抽象成通用的框架、工具类等。
比如应用模板方法设计模式将不变的算法逻辑框架定义出来,把变化的点延迟到子类重写。
能快速写成单元测试
代码的可测试性差,比较难写单元测试,那基本上就能说明代码设计得有问题。
试想下,如果一个类大而全,有一个方法依赖了十几个外部对象才能完成工作,耦合严重。
当你在编写单元测试的时候,需要 mock 十几个依赖对象和数据。
那说明这个代码糟透了,需要合理拆分和设计。
可读性强
软件设计大师 Martin Fowler 说过:「Any fool can write code that a computer can understand. Good programmers write code that humans can understand.」
翻译成中文就是:"任何二货都会编写计算机能跑的代码。优秀的程序员能够编写人能够理解的代码。”
而可读性就会涉及到编码规范、命名、注释、函数职责是否单一、长度是否精简。
有数据显示读代码的时间与写代码的时间比例超过 10:1,并且编写当前代码的难度,取决于读周边代码的难度。
所以我认为可读性强是最重要的一点。
高质量命名套路
开发过程后命名随处可见,我们给变量、方法、参数、类、包命名。
而命名的好坏会影响我们的可读性,我们不妨从命名作为切入口来写好代码。
勿模糊,准确达意
在开发过程中,一旦发现更好的名称,就换掉旧的。
一个变量、方法、或者类的名称应该展示出它该有的功能。根据名字我们能知道它能做什么事情,如何使用。
如果一个名称需要大量注释来补充避免使用者跳坑,那就是糟糕的名字。
变量名体现出该字段作用,比如 LocalDate now = LocaDate.now(); now 标识当前时间。
防止出现让人模糊无法理解,必须还要依据大量上下文才能理解的代码。
不要使用魔术。
反例 1 :使用魔数
// 从数据库获取列表
List<String> buyerList = dao.getList();
buyerList.forEach(x -> {
for (int i = 1; i <= 5; i++) {
processedBuyerList.add(String.format("%s,%s", i, x));
}
});
你会疑问,为啥索引是从 1 开始?为啥 <= 5。除此之外, i 与 1 极其相似,难以区分。
正确的方式应该使用实际含义的名字让人理解这么写的目的,否则维护的人将痛苦不堪。
反例 2:使用生僻字,又臭又长
UltimateAssociatedSubjectRunBatchServiceImpl,当我们看到这样的类名,是不是不知道怎么读,也不知道如何搜索和定位,更不知道到底表达的意思是什么,可能命这个名字的人还以为准确表达,其实是“王大妈的裹脚布,又臭又长”。
原本的业务含义是:执行关联主体任务相关业务类。
鉴于此,我们第一步要避免使用生僻字,可以命名为LinkSubjectServiceImpl ,清晰简单的表达出关联主体的业务逻辑都在该类。
不要误导
尽量不要使用不同之处较小的名称,这样让他人无法一眼区分两个名称是啥意思。
例如:函数 deleteIndex 和函数deleteIndexEx,这两个函数名区别很小了,加之函数 deleteIndexEx后面Ex还是缩写,也不知道是什么意思,所以他人只能去看函数内容才能明白两者的区别。
XYZStringHandler与 XYZStringStorage。
UserController与 UserInfoController。
让人抓狂,他们到底是一个东西还是不同的?差别在哪?没有两年脑血栓写不出这样的。
反例 3:名不副实
下面是一个生成文件并提供下载功能的接口。
public void downloadExcel(HttpServletResponse response) {
List<File> files = listFile();
String fileName = System.currentTimeMillis() + ".zip";
DownloadZip.downLoadFiles(files, filePath);
DownloadZip.fileDownload(response, filePath, fileName);
}
我们会疑惑,downLoadFiles 与 fileDownload 到底有啥区别?为啥要调用两次。
这种真的是十年脑血栓才写得出来。
downLoadFiles 的功能是创建将 files 打包成 zip 文件,而 fileDownload则是把指定的文件输出给浏览器下载。
所以 downLoadFiles 应该命名为 createZipFile用于合理区分避免误人子弟。
做有意义的区分
getActiveOrder();
getActiveOrderInfo();
getActiveOrderData();
getActiveOrders();
上面都是废话命名,别人你怎么知道到底该调用那个方法?
哪个表示订单明细?还是历史订单,还是全部订单查询,废话是另一种没有意义的区分。
名称不同,意思却无差别。
Order、OrderInfo、OrderData,他们名称相同 ,意思却无差别,属于毫无意义的废话。如果缺少明确约定,变量moneyAmount就与money没区别。
Variable一词永远不应当出现在变量名中。Table一词永远不应当出现在表名中。
结合上下文简化名称
public class Order {
private String orderNum;
private String orderCreateTime;
//...
}
比如 Order类,在该上下文中,没必要给每个成员变量重复添加 order 这个前缀单词,直接命名为 createTime、num。
因为我们可以借助 Order 这个上下文来获取信息。
Order order = new Order();
order.getCreateTime();
名称易读、可搜索
可读指的是不要使用一些生僻字,难以发音的单词。
可搜索是便于利用 IED 的自动补全和搜索功能,能根据我们的命名规范快速定位想要找的类或者方法等。
可读
名称读不出来,在讨论的时候就好像是一个沙雕。
哎,那个「treeNewBeeAxibaKula」类是什么作用?
听到这样的名字尴尬癌都犯了。
使用一些生僻字,犹如「王大妈的裹脚布,又长又臭」,没有两年脑血栓写不出这样的垃圾代码。
可搜索
IED 很智能,当我们输入 「Hash」的时候,会列举出所有 Hash 相关的类。
命名的时候最好符合项目命名习惯,列表数据查询大家使用 listXXX,你就不要用 queryXXX,统一命名规范,很重要。
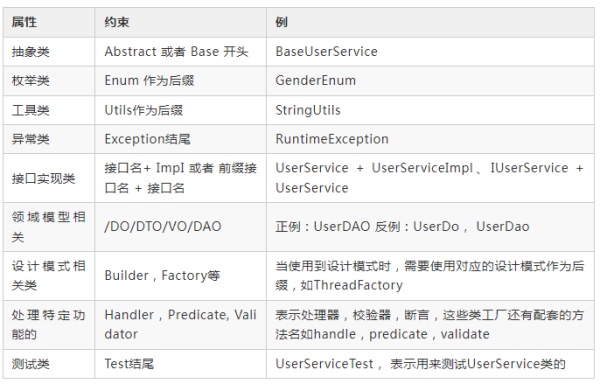
包命名
包名统一使用小写,点分隔符之间有且仅有一个自然语义的英文单词或者多个单词自然连接到一块(如 springframework,deepspace 不需要使用任何分割)。
包名的构成可以分为以下几四部分【前缀】 【发起者名】【项目名】【模块名】。
以下表格授权于「Java 填坑笔记」
常见的前缀可以分为以下几种:

类名
类名使用大驼峰命名形式,应该使用名词或者名词短语,比如:Customer、Account。
避免使用 Manager、Processor 等动词。
接口名除了用名词和名词短语以外,还可以使用形容词或形容词短语,如 Cloneable,Callable 等,表示实现该接口的类有某种功能或能力。
方法名
方法命名一般为动词或动词短语,与参数或参数名共同组成动宾短语,即动词 + 名词。一个好的函数名一般能通过名字直接获知该函数实现什么样的功能。
布尔返回值的方法
注:Prefix-前缀,Suffix-后缀,Alone-单独使用

按需执行的方法

用来检查的方法

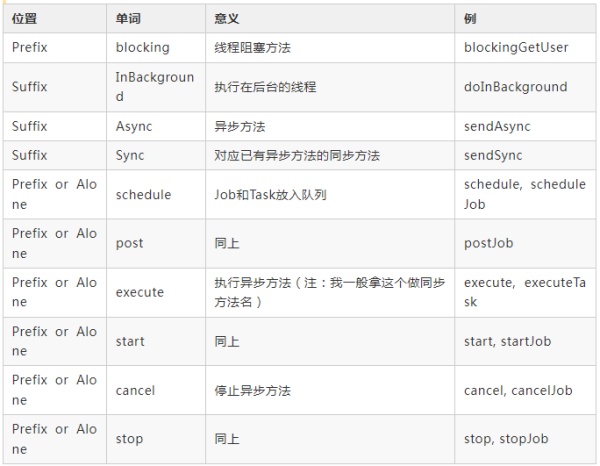
异步相关方法
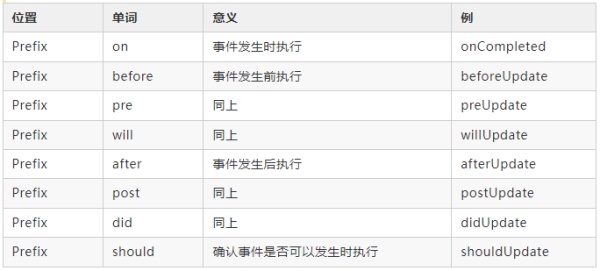
回调方法
操作对象生命周期的方法
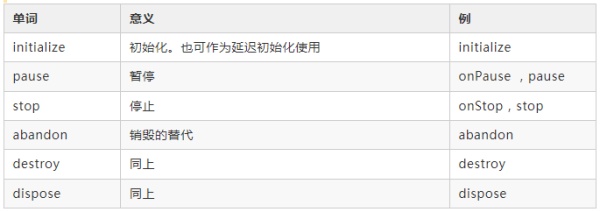
4.7 与集合操作相关的方法
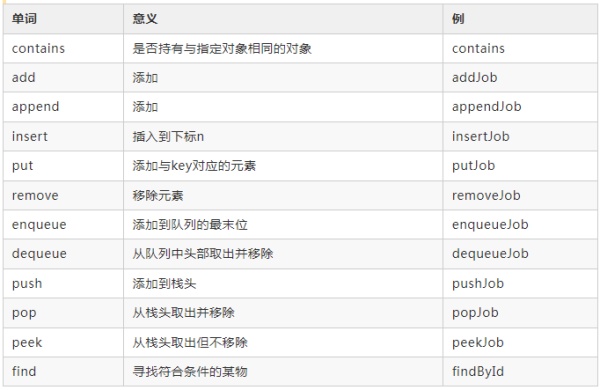
与数据相关的方法
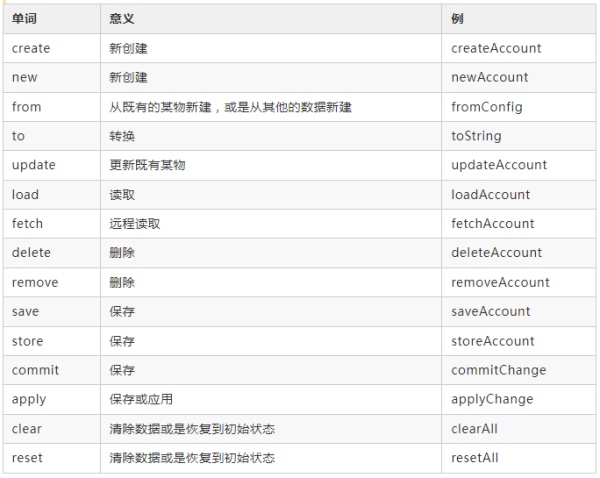
成对出现的动词
| 单词 | 意义 |
| get获取 | set 设置 |
| add 增加 | remove 删除 |
| create 创建 | destory 移除 |
| start 启动 | stop 停止 |
| open 打开 | close 关闭 |
| read 读取 | write 写入 |
| load 载入 | save 保存 |
| create 创建 | destroy 销毁 |
| begin 开始 | end 结束 |
| backup 备份 | restore 恢复 |
| import 导入 | export 导出 |
| split 分割 | merge 合并 |
| inject 注入 | extract 提取 |
| attach 附着 | detach 脱离 |
| bind 绑定 | separate 分离 |
| view 查看 | browse 浏览 |
| edit 编辑 | modify 修改 |
| select 选取 | mark 标记 |
| copy 复制 | paste 粘贴 |
| undo 撤销 | redo 重做 |
| insert 插入 | delete 移除 |
| add 加入 | append 添加 |
| clean 清理 | clear 清除 |
| index 索引 | sort 排序 |
| find 查找 | search 搜索 |
| increase 增加 | decrease 减少 |
| play 播放 | pause 暂停 |
| launch 启动 | run 运行 |
| compile 编译 | execute 执行 |
| debug 调试 | trace 跟踪 |
| observe 观察 | listen 监听 |
| build 构建 | publish 发布 |
| input 输入 | output 输出 |
| encode 编码 | decode 解码 |
| encrypt 加密 | decrypt 解密 |
| compress 压缩 | decompress 解压缩 |
| pack 打包 | unpack 解包 |
| parse 解析 | emit 生成 |
| connect 连接 | disconnect 断开 |
| send 发送 | receive 接收 |
| download 下载 | upload 上传 |
| refresh 刷新 | synchronize 同步 |
| update 更新 | revert 复原 |
| lock 锁定 | unlock 解锁 |
| check out 签出 | check in 签入 |
| submit 提交 | commit 交付 |
| push 推 | pull 拉 |
| expand 展开 | collapse 折叠 |
| begin 起始 | end 结束 |
| start 开始 | finish 完成 |
| enter 进入 | exit 退出 |
| abort 放弃 | quit 离开 |
| obsolete 废弃 | depreciate 废旧 |
| collect 收集 | aggregate 聚集 |
总结
命名目的都是为了让代码和工程师进行对话,增强代码的可读性,可维护性。优秀的代码往往能够见名知意。

