本文将介绍成功创建机器学习解决方案时,一些最常见的设计模式。
作者 | 彼尔·保罗·伊波利托(Pier Paolo Ippolito),数据科学家
译者 | 卢鑫旺
审校 | 梁策 孙淑娟
介绍
设计模式是针对常见通用问题的一整套最佳实践和可重用解决方案。在数据科学和软件开发、建筑设计等学科中,有大量问题重复出现,因此,尝试对最常见的问题进行分类,并提供不同形式的计划蓝图,以便轻松识别和解决这些问题,为更多人群带来巨大的好处。

在软件开发中使用设计模式,这一想法首先由埃里克·加马(Erich Gamma)等人在《设计模式:可重用面向对象软件要素》(Design Patterns: Elements of Reusable Object-Oriented Software)[1]中提出。此外,根据萨拉·罗宾森(Sara Robinson)等人的《机器学习设计模式》(Machine Learning Design Patterns)[2]一文,设计模式也得以应用到了机器学习过程。
在本文中,我们将探讨组成MLOps的不同设计模式。MLOps (Machine Learning -> Operations,即机器学习->运营)是一整套流程,旨在将实验性的机器学习模型转换为可在现实世界中做决策的生产性服务。其核心是,MLOps与DevOps基于相同原则,但还额外关注数据验证和持续训练/评估(图1)。
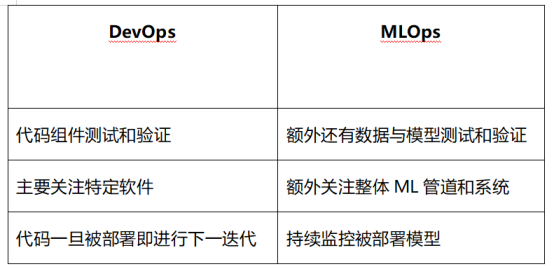
图1:DevOps和MLOps(图片来自作者)
MLOps的一些主要好处:
上市时间缩短(部署更快)
模型稳健性增强(识别数据漂移、重新训练模型等更便捷)
训练/比较不同ML模型更灵活
另一方面,DevOps强调软件开发的两个关键概念:持续集成(CI)和持续交付(CD)。持续集成的重点是使用一个中心库作为团队在项目中协作的一种方式,并且在不同团队成员添加新代码时,尽可能自动化添加、测试和验证新代码。通过这种方式,人们可以在任何时候测试应用程序的不同部分是否能够正确地相互通信,并对任何形式的错误快速识别。持续交付则侧重于平稳地更新软件部署,尽量避免任何形式的宕机。
MLOps设计模式
工作流管道
机器学习(ML)项目由许多不同步骤构建(图2):
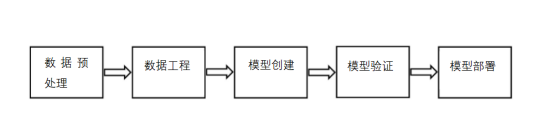
图2:ML项目关键步骤(图片来自作者)
在对一个新模型进行原型设计时,通常使用单个脚本(单片)来编写整个过程,但随着项目愈发复杂,团队参与成员增多,这时就有必要将项目的每个不同步骤划分为一个单独的脚本(微服务)。因此,采取这种方法可能会带来一些好处:
更容易对不同步骤的编排进行更改试验
根据定义使项目具有可扩展性(可以轻松添加和删除新步骤)
每个团队成员都可以专注于流程中的不同步骤
每个不同的步骤都可以获得分散的模型产出
工作流管道设计模式,旨在定义一个计划蓝图来创建ML管道。ML管道可以用一个有向无环图(DAG)表示,其中每一步都由一个容器来体现(图3)。
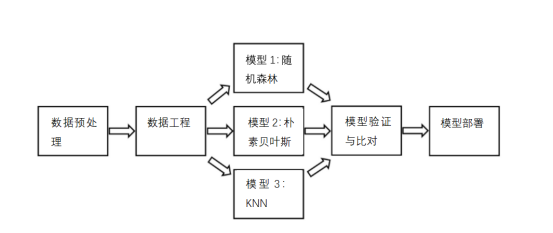
图3:有向无环图(DAG)示例(图片来自作者)
遵循这种结构,就有可能创建可重用和可管理的ML过程。使用工作流管道的一些好处是:
通过在流程中添加和删除步骤,可以创建复杂的实验来测试不同的预处理技术、机器学习模型和超参数
单独保存每个不同步骤的输出。如果在最后步骤中应用了任何更改,可避免在管道开始时重新运行步骤(从而节省时间和算力)
在出现错误的情况下,可以很容易地确定哪些步骤需要更新修改
一旦使用CI/CD部署到生产环境中,就可根据不同的因素(如时间间隔、外部触发器、ML指标变化等)调度管道重新运行
特征平台
特征平台是一个为机器学习过程设计的数据管理层(图4)。这个设计模式的主要用途是简化组织管理和使用机器学习特征的方式。这通过创建某种形式的中心库来实现,该中心库用来存储公司曾经为构建ML流程创建的所有特征。通过这种方式,如果数据科学家需要为不同的ML项目提供相同的特征子集,他们就无需多次把原始数据转换为处理过的特征,因为这可能更费时间。最常见的两种开源特征平台解决方案是Feast和Hopsworks。
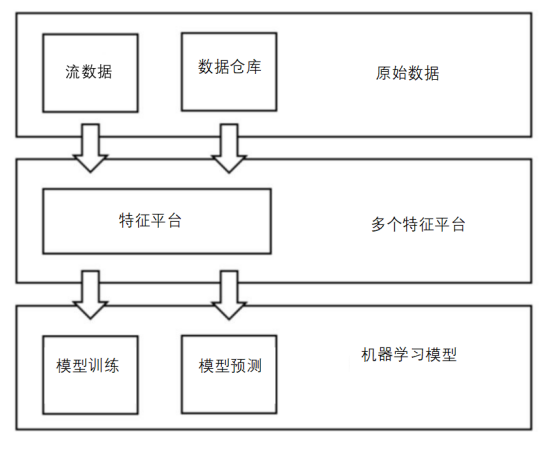
图4:特征平台设计模式(图片来自作者)
了解更多关于特征平台的信息可以查阅 (https://towardsdatascience.com/getting-started-with-feature-stores-121006ee81c9)
转换
转换(Transform)设计模式旨在通过将输入、特征和转换保持为单独的实体,使机器学习模型在生产中更易于部署和维护(图5)。事实上,原始数据通常需要经过不同的预处理步骤,然后才能用作机器学习模型的输入,其中一些转换需要保存,以便在预处理推理所用数据时重用。
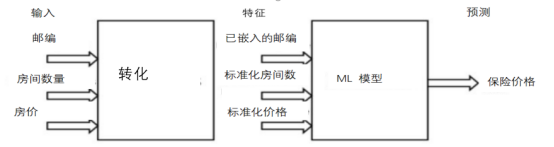
图5:输入和特征之间的关系(图片来自作者)
例如,在训练ML模型之前,为了处理离群值并使数据看起来更像高斯分布,通常将归一化/标准化技术应用于数值数据。这些转换应该保存下来,以便在将来提供新数据进行推断时重用。而如果不保存这些转换,那么在训练和服务之间我们将会产生数据倾斜问题,造成为推理提供的输入数据与用于训练ML模型的输入数据分布不同。
为了避免训练模型和服务之间产生任意类型的数据倾斜,一个可行的解决方案是使用特征平台设计模式。
多模式输入
在训练ML模型时,图像、文本、数字等不同类型的数据都可使用,不过某些类型的模型只能接受特定类型的输入数据。例如,Resnet-50只能取图像作为输入数据,而其他的ML模型,如KNN (K Nearest Neighbor,K最近邻)只能够取数字数据作为输入。
为了解决ML问题,有必要使用不同形式的输入数据。在这种情况下,我们需要应用某种形式的转换,以为所有不同类型输入数据(多模式输入设计模式)创建共同表示。举个例子,假如我们有一个文本、数字和分类数据的组合,为了训练ML模型,我们可以利用情感分析、词包或词嵌入等技术将文本数据转换为数字格式,并利用独热编码(one-hot-encoding)对分类数据进行转换。这样,我们就可以将所有数据以相同的格式(数值)保存下来,以便用于模型训练。
级联
在某些场景中,仅用一个ML模型不可能解决问题。在这种情况下,有必要创建一系列相互依赖的ML模型来实现最终目标。举个例子,假设我们尝试预测向用户推荐的物品内容(图6)。为了解决这个问题,我们首先要创建一个模型,它能够预测用户小于还是大于18岁。然后,根据该模型的响应,路由到两个不同ML推荐引擎中的一个(一个向18岁以上的用户推荐产品,另一个向18岁以下的用户推荐产品)。
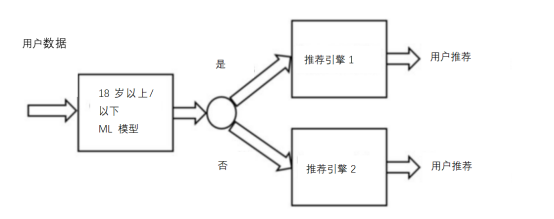
图6:级联设计模式(图片来自作者)
为了创建这个级联的ML模型,我们需要确保它们一起训练。事实上,由于其相互依赖,那么如果第一个模型发生变化(而不更新其他模型),就可能导致后续模型不稳定。我们可以使用工作流管道设计模式(Workflow Pipeline)自动化此类流程。
结论
在本文中,我们探讨了支持MLOps的一些最常见的设计模式。如果你有兴趣了解更多关于机器学习中的设计模式问题,请参阅瓦力阿帕·拉克沙马南(Valliappa Lakshmanan) 在AIDVFest20上的演讲以及《机器学习设计模式》(Machine Learning Design Patterns)一书的公共GitHub知识库。
参考文献
[1] "Design Patterns: Elements of Reusable Object-Oriented Software" (Addison-Wesley,1995): www.uml.org.cn/c%2B%2B/pdf/DesignPatterns.pdf
[2] "Machine Learning Design Patterns" (Sara Robinson et. al., 2020):
https://www.oreilly.com/library/view/machine-learning-design/9781098115777/
作者:
彼尔·保罗·伊波利托(Pier Paolo Ippolito) 是一名毕业于南安普顿大学的数据科学家。他持有人工智能硕士学位,对人工智能的发展和机器学习应用(如金融和医学领域)有着浓厚的兴趣。
联系方式:
如想了解作者最新的文章和项目,可通过以下方式联络:
译者介绍
卢鑫旺,51CTO社区编辑,半路出家的九零后程序员。做过前端页面,写过业务接口,搞过爬虫,研究过JS,有幸接触Golang,参与微服务架构转型。目前主写Java,负责公司可定制化低代码平台的数据引擎层设计开发工作。
原文标题:Design Patterns in Machine Learning for MLOps,作者:Pier Paolo Ippolito
2022年1月13日发布于Towards Data Science

