一文带你了解如何使用Sidecar来实现微服务。

译者 | 布加迪
合理设计的微服务应遵循单一职责原则,因此分离应该被架构中的其他服务重用的通用功能很重要。Sidecar模式提倡通过识别每个服务中的通用功能来增强模块性,将它们组合到库中,或将它们移到单独的服务中。
顾名思义,Sidecar模式提倡分离横切关注点(cross-cutting concern),将横切关注点从实际服务中移除,推送到单独的模块、库或服务,然后这些功能可被架构中的其他服务重用。
本文讨论了微服务架构中哪种功能可以作为候选功能或可以被视为Sidecar,以及Sidecar的实现方法和优缺点。
Sidecar候选功能
面向切面编程带来了分离横切关注点这个值得关注的概念;简而言之,从代码中移除通用功能,只关注业务逻辑,这就是在服务内的每个方法/函数中重复相同代码的意义所在。
Sidecar模式本质上相似;唯一的区别是,Sidecar模式从微服务方面进行对话。将代码的通用部分抽象出来变得更重要了。
一些最重要的候选功能包括如下:
•日志聚合
•安全
•错误处理,并在发布错误日志或将错误事件推送到Kafka主题或监控队列之后采取必要的动作。
•项目中的通用功能类似于实体(数据库模型)或其他服务也使用的特定业务逻辑。
•其他服务正常运行所需要的服务或数据库配置、Kafka配置、队列配置等方面的配置更改。
•缓存需求(如果有这种需求的话)。
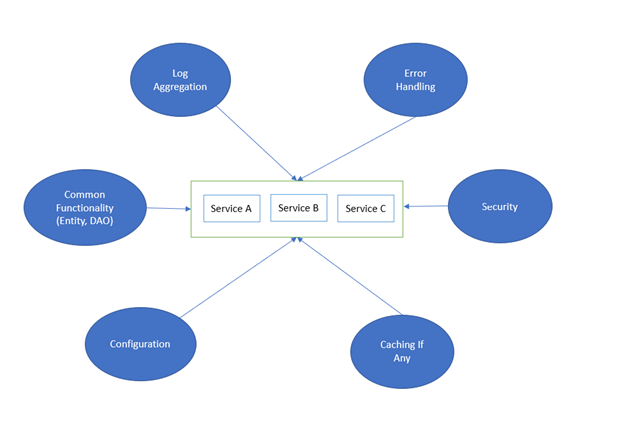
所有这些通用功能/Sidecar可以附加到服务上,就像边车附加到摩托车上那样。

优缺点
•优点
实施这种模式的最大优点是,所有通用功能都可供架构中的所有服务使用,它通过将通用功能抽象到不同的层,大大降低了架构的复杂性。
微服务本质上是多语言的,这些通用功能可以使用最适合该特定操作的技术或编程语言来开发。
模式隐式避免了代码重复,因为我们不需要在每个服务中编写这种重复的代码。
服务和Sidecar候选功能之间是松散耦合的关系。
•缺点
Sidecars具有单独的可维护性,这可能是库或单独的服务。如果我们在应用程序中有大量的Sidecar,那么它会影响服务的性能。需要确定Sidecar功能是否需要独立于主服务进行扩展;如果是,需要将这些Sidecar作为单独的服务来托管。
实施方法
•将Sidecars保存在单独的库中
最常见的方法是将Sidecars保存在单独的库中,并将这些库单独导入到微服务中,比如将数据库模型保存在单独的库中,然后通过该库将这些模型导入到所有微服务,有各种构建工具(比如Maven、Gradle或SBT等)可用用于配置。
这种方法有以下缺点:
Sidecar过载:设想一个项目中维护多个Sidecar,比如架构中存在的日志、缓存、配置和安全都可能会在所有微服务中带来Sidecar过载的问题。
版本不一致:维护每个库的正确版本对于开发人员来说将是一场噩梦,想象一下cache-lib Sidecar拥有服务A在使用的最新版本1.1,但我们忘了提及仍在使用cache-lib版本1.0的服务B的正确版本,这会在应用程序中产生明显的不一致,而这种不一致很难调试和识别。
解决这个问题的一种方法是创建一个含有所有这些Sidecar库的Uber库,然后我们需要做的就是在微服务中维护Uber库的正确版本,我们需要确保Uber库经过更新,使用最新版本的Sidecars,比如说cache-lib 1.1应该在Uber库中可用。
•将Sidecars保留为单独的服务
另一种方法是在单独的服务中各自维护Sidecar。但是为每个操作调用服务调用会带来严重的性能问题,但理想情况下,我们通常不为日志或通用功能创建服务。安全或缓存可能是理想的独立的服务候选功能。
这种方法的最大缺点是,始终需要优化服务间通信以获得更好的性能。在这种情况下,它就像架构中的另一个微服务,总是需要扩展,监控哪种有悖Sidecar的用途。
结论
Sidecar模式是一种非常有用且简洁的模式,它使横切关注点远离实际的服务实现。合理设计的微服务应该始终遵循单一职责原则(SRP),而Sidecar模式通过远离重复功能来补充SRP原则。每个设计原则都有优缺点,在库中维护Sidecar以及保留最重要功能的混合方法应该在单独的服务中加以维护。
原文标题:Microservices Patterns: Sidecar,作者:Sameer Shukla
链接:https://dzone.com/articles/microservices-patterns-sidecar

