作为9月2日成都核酸检测的亲历者, 也跟所有的成都市民一样,经历了核酸系统崩溃之后的排队崩溃和心理崩溃。
昨天,在至少排了一个小时的队之后,前面还没有动静。我跑到志愿者扫码登记的地方观察了很久,也看了网上各种各样的分析,声音很多。
作为一个程序猿,也来说说我的看法
在发出这个内容之前,我看到 东软已经发出了声明 ,概括起来主要是这样:第一次崩溃是成都政府的系统不行,第二次则是因为网络不行。总而言之,都不是东软自己软件的问题。

对于这个声明,你问我怎么看?我最后再告诉你。
我先从技术角度对这个问题做一个整体分析。 首先是网上的几个传说,但传说也仅仅只是传说,这个锅应该都不归它们。
首先:是说网络信号有问题,这个说法很明显在打脸。 运营商的资源非常丰富。从事实上看,当时排队的人那么多,大家也都在刷视频、聊天,都非常流畅,完全无卡顿。呼吁大家让出信号通道,设置为飞行模式,完全是想多了,运营商表示不答应。

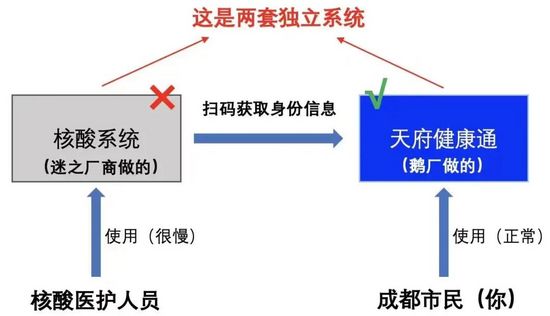
其次:有人认为是天府健康通的问题
这个问题也有人澄清,成都的核酸检测可以通过刷身份证,或者扫天府健康通的健康码进行。
如果说真的是健康码有了故障,那市民们完全可以刷身份证来做核酸。但从市民们的反馈来看,这两种方法都无法成功。
那很明显,问题自然出现在了核酸系统这一端。我们也可以看到,这两套系统也是两个不同厂家提供的支持,另外根据热心人士提供信息,天府健康通规划的容量是完全足够的。

第三:有人认为是数据库的问题
这个确实有可能,但不是数据库本身的问题,而是数据设计的问题。 即便用了MySQL,也不能就说是数据库本身的问题,比如说,有一个灶台和一口小锅,一次不能炒很多,但可以多几口锅,分开炒,所以也不能把这个锅甩给MySQL数据库,同时这个数据库的设计一定是核酸系统厂家(迷之厂商)设计的才对。
分析完了几个传言,那么核酸系统是哪里出现了问题?
成都市民不外出小区,检测点全部进入小区,所以一下子要多出好几倍的业务量,的确对核酸系统提出了非常高的要求。针对这类高并发的业务系统,如何提高系统稳定性,可靠性,确实是一个技术活,这也不是简单某一点上的问题,而是一个系统工程,在多个环节上都需要进行控制,否则很难达到目标。
我接着从程序员的角度,来列举几个可能存在问题的环节。
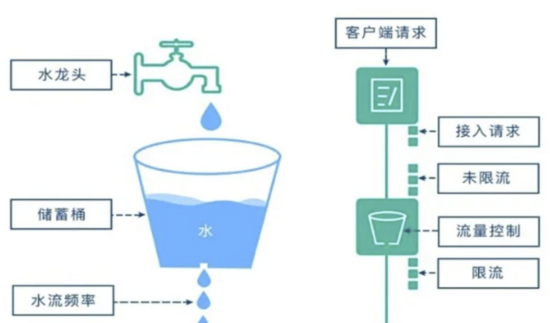
第一:接入网关
这个能力非常重要,也是互联网架构中不可缺少的环节,主要的能力是鉴权和限流。鉴权的目的是防止被非法访问,不合规不合法的访问请求被阻止掉;其次是限流,我们的系统设计一定有一个上限,超过上限怎么办?与其让系统崩溃还不如把请求控制在设计的流量范围内,系统还可以运行。
例如:我们设计的交通是四车道,当车流量达到四车道的负荷时,就进行限制,控制车辆进入,这样可以保障四车道的车流继续进行运转,如果不限流,其结果就是将四车道变成停车场,全部都堵死,谁也跑不了。这就是有些系统设计时考虑了这个环节时的情况是可能较慢,但不至于崩盘,不至于都不能用。
成都核酸系统,就很可能存在这种问题,在2号之前在区县使用的时候没有问题,2号进行大面积使用时,系统经常卡死,一直转圈,操作人员被迫终止程序重新登录。

高速公路变成停车场
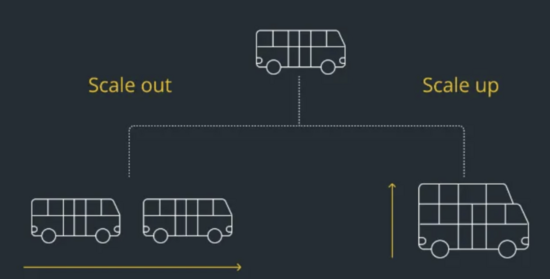
第二:应用服务器扩展能力
扩展分为垂直扩展和水平扩展。 所谓的垂直扩展,大家容易理解,就是将处理能力低的服务器升级到高配置,例如:增加CPU,增加内存等,但是这种往往比较受限,服务器垂直扩展能力是有限的,不能无限制的扩展。
其次是水平扩展,就是说增加数量,就是一台服务不够,再增加一台,10台不够,就增加到20台,这个就和架构设计有关系了,能做到水平扩展才行,不然想通过资源来扩展都没有办法使上力。
成都核酸系统根据2号的情况来看,无论是扫描身份证读取身份基本信息, 还是读取天府健康通健康码获取用户信息都比较慢,比较怀疑这里处理的服务器能力也不足 ,如果架构上非常灵活支持水平扩展,通过申请政务云资源,应该很快可以提升。
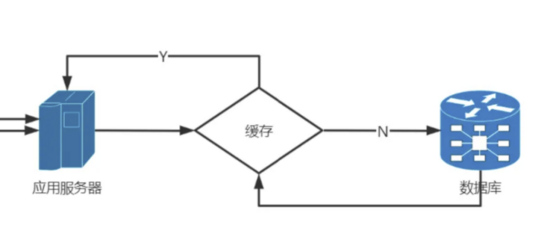
第三:业务缓存
大家都知道数据存放在数据库中,每次的读写都需要产生大量的磁盘IO,这是性能的瓶颈,可以将高频使用的数据存放在内存中,大大提升读写的效率,同时也不用每次都访问数据库,既减轻了数据库的压力,也大大提升效率。
但是内存的数据不是长久存放,最终还必须要写到磁盘中,所以在架构设计的时候要充分考虑数据一致性和安全问题,防止数据丢失以及不一致。
根据2号的表现来看,成都的核酸系统在获取完待检测人员信息之后, 加入到检测人员列表时,也需要较长时间,并且还容易在这个环节卡死,所以大概率是在写入数据时出现异常, 有可能是直接采用写入数据库的方式,产生了数据库拥塞,所以是否使用了缓存技术无法判断。
第四:数据库的性能优化
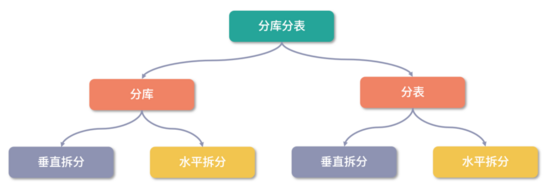
这是最后一个环节,包括:分库、分表、读写分离,也是最容易出现问题的地方。
一是采用分库,就是给数据库瘦身,不要把所有的数据都放在一个库中, 类似不能把高新区的人都安排在一个小区一样,安排在一个小区,所有人都要通过小区大门进出,容易导致阻塞,就是说的请求拥堵。
二是采用分表,就是让单个的表中的数据不能太多,也是避免读写时产生拥堵, 类似一个小区中的不同楼栋一样,如果所有的人都住在一栋楼,这些人员的进出就会很拥堵,进门要堵,电梯要堵,所以可以分成不同的楼栋,大家分开进行,减低拥堵可能性。分表的方式很多,可以按照日期来分表,每天一套表,也可以按照区域来分表,不同区域的数据存在不同的表中,结果就是单表的数据量会变小,读写拥堵可能性大大减低,这也是提升数据库性能的很好的手段。
三是采用读写分离,就是分成不同的库, 有些库主要负责写入数据,有些数据库是负责查询数据,一个主库负责写,然后复制几个库来支持查询,这样可以将数据库的负荷进行分担,也可以大大提升性能。
成都的核酸系统也有可能是在写入数据时出现异常,很大可能是没有采用分库、分表的技术,导致在数据写入时产生大量的并发,写入不了。
其实,核酸系统的业务并不复杂。
主要流程就是: 登录人员登录到对应的检测点之后,然后就是选择单检、混检1(10混)、混检2(20混)。假如选择混检1,然后扫描试管上条码,生成一组,再扫描检测人员,满10人后,选择封管,就能完成一组操作。
但就算业务逻辑不复杂,还能出现如此差的表现,那我分析主要问题还是出现在架构设计上,没有考虑高并发场景。
很大可能性是:
没有考虑限流机制(应该根据压测的容量进行设置阈值);
没有考虑缓存机制,导致都需要直接读写数据库,给数据库造成极大压力;
没有考虑数据库的分库分表,导致数据库异常繁忙,并发量大时,没有办法正常写入。
所以我认为与网络没有太大关系,和天府健康通也没有关系,和政务云资源也没有关系 (按照需求进行分配,政务云的资源是动态分配,满足业务需求不会太大挑战)。
真心建议核酸系统开发公司认真分析,找出问题根源,进行认真优化,不要让我们再经历这样的情况!
(本文系投稿,作者是一名来自成都的程序员)

